【论文考古】知识蒸馏 Distilling the Knowledge in a Neural Network
论文内容
G. Hinton, O. Vinyals, and J. Dean, “Distilling the Knowledge in a Neural Network.” 2015.
如何将一堆模型或一个超大模型的知识压缩到一个小模型中,从而更容易进行部署?
训练超大模型是因为它更容易提取出数据的结构信息(为什么?)
知识应该理解为从输入到输出的映射,而不是学习到的参数信息
模型的泛化性来源于错误答案的相对概率大小(一辆宝马被误判为卡车的概率大于被误判为萝卜的概率),而泛化性是学习的终极目标
基本构架:学习高温Softmax之后的值
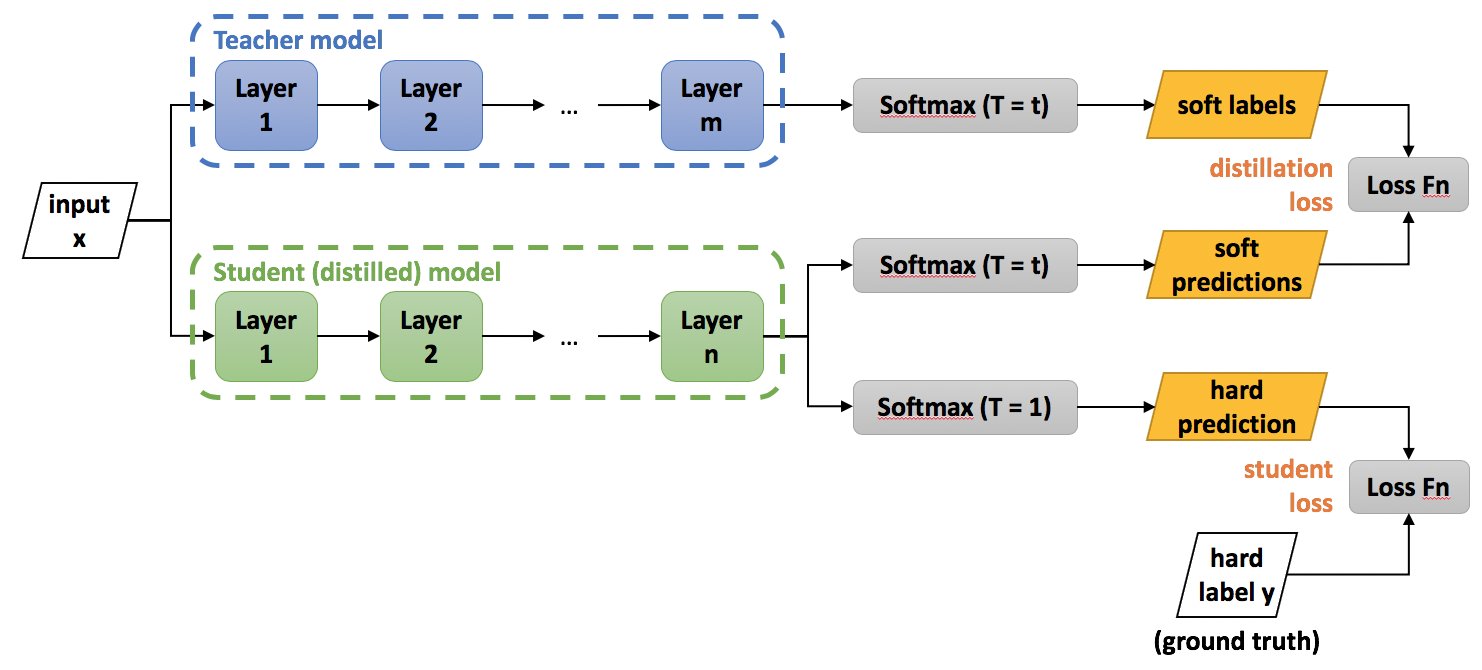
超大数据集下如何训练?
论文给出的方法:用专家模型独立训练容易混淆的数据,在准确率略微提高的基础上,将训练时间从许多周缩短为几天
模型集合是一个针对所有数据的generalist model和许多针对相近数据的专家模型。训练专家模型时,用generalist model的参数进行初始化(这样可以防止过拟合),训练数据一半是相近数据的集合,一半是随机选取的其他数据
(correct for the biased training set by incrementing the logit of the dustbin class by the log of the proportion by which the specialist class is oversampled 应该如何理解?)
分配不同种类到专家模型:将容易混淆的预测进行聚类,从而分配到专家模型
最后对包含专家模型的一组神经网络进行知识蒸馏,提炼成一个同样大小的单一神经网络,方便部署
实际效果
泛化性的检验:在MNIST数据集中,仅靠知识蒸馏,能识别出缺失的某张图片吗?
金句启发
把dropout和分布式学习相结合?
Dropout can be viewed as a way of training an exponentially large ensemble of models that share weights.
FL的特点在于数据不能共享,所以不能在服务器端做模型融合。能不能做一个分布式的知识蒸馏,用专家模型解决异构数据的难点?
【论文考古】知识蒸馏 Distilling the Knowledge in a Neural Network的更多相关文章
- 【DKNN】Distilling the Knowledge in a Neural Network 第一次提出神经网络的知识蒸馏概念
原文链接 小样本学习与智能前沿 . 在这个公众号后台回复"DKNN",即可获得课件电子资源. 文章已经表明,对于将知识从整体模型或高度正则化的大型模型转换为较小的蒸馏模型,蒸馏非常 ...
- Distilling the Knowledge in a Neural Network
url: https://arxiv.org/abs/1503.02531 year: NIPS 2014   简介 将大模型的泛化能力转移到小模型的一种显而易见的方法是使用由大模型产生的类概率作 ...
- 1503.02531-Distilling the Knowledge in a Neural Network.md
原来交叉熵还有一个tempature,这个tempature有如下的定义: \[ q_i=\frac{e^{z_i/T}}{\sum_j{e^{z_j/T}}} \] 其中T就是tempature,一 ...
- 论文阅读笔记十八:ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation(CVPR2016)
论文源址:https://arxiv.org/abs/1606.02147 tensorflow github: https://github.com/kwotsin/TensorFlow-ENet ...
- 论文阅读笔记六十四: Architectures for deep neural network based acoustic models defined over windowed speech waveforms(INTERSPEECH 2015)
论文原址:https://pdfs.semanticscholar.org/eeb7/c037e6685923c76cafc0a14c5e4b00bcf475.pdf 摘要 本文研究了利用深度神经网络 ...
- 论文翻译:2020_Acoustic Echo Cancellation Based on Recurrent Neural Network
论文地址:https://ieeexplore.ieee.org/abstract/document/9306224 基于RNN的回声消除 摘要 本文提出了一种基于深度学习的语音分离技术的回声消除方法 ...
- 论文笔记:Person Re-identification with Deep Similarity-Guided Graph Neural Network
Person Re-identification with Deep Similarity-Guided Graph Neural Network 2018-07-27 17:41:45 Paper: ...
- Deeplearning知识蒸馏
Deeplearning知识蒸馏 merge paddleslim.dist.merge(teacher_program, student_program, data_name_map, place, ...
- 论文解读(GCC)《GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training》
论文信息 论文标题:GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training论文作者:Jiezhong Qiu, Qibi ...
随机推荐
- Centos6.8安装并配置VNC
一般服务器都会在IDC或云端,为了可以看到服务器的图形化界面,需要安装配置VNC,本例为Centos6.8上安装配置VNC. [root@hostname ~]#yum install -y tige ...
- centos7 修改网卡信息
修改网卡配置文件 vim /etc/sysconfig/network-scripts/ifcfg-eth0 有一些不是eth0 也可能是ens33 修改完成后使用下面命令进行重启 systemctl ...
- 强化学习实战 | 自定义gym环境之显示字符串
如果想用强化学习去实现扫雷.2048这种带有数字提示信息的游戏,自然是希望自定义 gym 环境时能把字符显示出来.上网查了很久,没有找到gym自带的图形工具Viewer可以显示字符串的信息,反而是通过 ...
- TestNG 运行Webdriver测试用例
1.单击选中的新建工程的名称,按Ctrl+N组合键,弹出对话框选择"TestNG"下的"TestNG class"选项,点击"next" 2 ...
- ES6随笔D1
1.数值解构赋值 ES6 允许按照一定模式,可以从数组中提取值,按照对应位置,对变量赋值,这被称为解构. 解构赋值的规则是,只要等号右边的值不是对象或数组,就先将其转为对象.由于undefined和n ...
- Fio使用和结果分析
感谢,参考自:https://blog.51cto.com/qixue/1906768: 官方说明文档,很有用:https://fio.readthedocs.io/en/latest/index.h ...
- MRCTF2020 你传你🐎呢
MRCTF2020 你传你 .htaccess mime检测 1.先尝试上传了一个文件,发现.jpg后缀的可以上传成功,但是用蚁剑连接时返回空数据 2.重新先上传一个.htaccess文件,让需要被上 ...
- 一些Markdown扩展语法
相信很多人跟我一样,对Markdown是"一知半解",会打一点,知道一点,但是其实从没花哪怕一分钟了解过.其实除了标题粗体插入代码,Markdown还有很多有趣的基础语法和扩展语法 ...
- 推荐召回--基于物品的协同过滤:ItemCF
目录 1. 前言 2. 原理&计算&改进 3. 总结 1. 前言 说完基于用户的协同过滤后,趁热打铁,我们来说说基于物品的协同过滤:"看了又看","买了又 ...
- gin中绑定html复选框
main.go package main import "github.com/gin-gonic/gin" type myForm struct { Colors []strin ...