论文解读:MASS-EDITING MEMORY IN A TRANSFORMER(MEMIT)
论文发表于人工智能顶会ICLR(原文链接)。在模型编辑方法中,过去工作主要局限于更新单个事实。因此,基于ROME,本文开发了MEMIT,在大模型GPT-J(6B)和GPT-NeoX(20B)上实现了数千的批量编辑。
阅读本文请同时参考原始论文图表。
方法
模型定义为文中式(1),其中$[x_{[1]},…,x_{[E]}]$表示长度为$E$的输入句子,$x_{[t]}$表示模型输出单词。模型层之间状态的计算表示为式(2/3/4),将模型最后一层关于输入句子最后一个token的状态映射到词汇空间就是$x_{[t]}$。本文主要考虑GPT-J的架构来介绍方法,其中FFN和注意力模块并行,而不是使用注意力模块的输出输入FFN(当然后面介绍的MEMIT方法可以适用到其它LLM架构上)。
对于一个事实$(s,r,o)$,模型输入包含头实体$s$和关系$r$的句子,输出头实体$o$。模型编辑就是让模型关于包含$(s,r)$的句子输出$o$变成另一个$o'$ 。本文的目标是同时对多个事实进行编辑,对同时编辑的事实构成的集合$\mathcal{E}$做了一个限制,如式(5)所示,即事实之间不能有冲突。
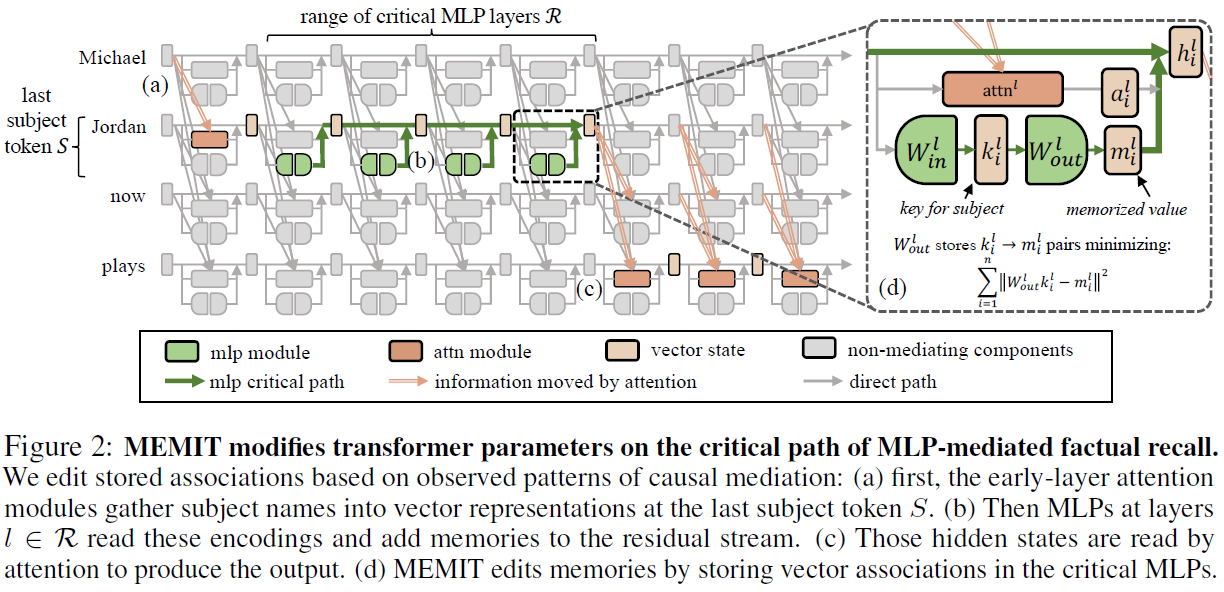
根据ROME论文的实验结果,对于某个prompt $p_i$,本文只考虑其中主体$s$的最后一个token的中间层状态$h_i^l$、对应的FFN激活$m_i^l$和注意力模块激活$a_i^l$对模型输出的影响,此时$i$为prompt的编号。另外,如图3所示(ROME的实验),由于不止一个中间层对模型预测有影响,因此同时考虑多个中间层相应激活对预测的影响。比如对于GPT-J,$l\in \mathcal{R}=\{3,4,5,6,7,8\}$。
模型推理机制
根据模型的状态计算式(2),可以得到式(6),即每一层的输出状态是初始状态加上其前面层的FFN和注意力模块激活。根据之前ROME实验(ROME论文图1e/f/g)的观察,作者认为模型的推理机制如图2所示:
(a)模型先使用注意力机制把主体$s$的信息汇集到$s$的最后一个token(Jordan)。
(b)通过模型各层FFN根据主体$s$的信息逐步读取相关的记忆并加入潜在表示。
(c)通过注意力模块使用读取的记忆来生成输出,也就是图2所示的信息通路。
批量参数更新
和ROME类似,对于第$l$层的FFN的第二层权重,在预训练后满足式(7),通过求导得到方程式(8)。其中$K_0=[k_1,…,k_n],M_0=[m_1,...,m_n]$。当要添加新知识$K_1,M_1$时,就是把它们拼接后进行优化,即式(10-13)。最终得到$W_0$的改变量$\Delta$为式(14)。其中$C_0=K_0K_0^T$定义为期望式(15),$\lambda=1.5\times 10^4$。注意MEMIT的优化定义与ROME不同。
多层参数批量更新
1、根据之前的模型推理机制的分析,作者先通过式(16)优化得到主体$s$最后一个token在第$L$层关于待修改事实$(s_i,r_i,o_i)$ 的表示$z_i$。其中$L=\max(\mathcal{R})$表示对预测有影响层的最大层数,$h_i^L$表示模型关于$(s_i,r_i)$在该位置的原始表示。也就是优化一个残差值$\delta_i$,使得$z_i=h_i^L+\delta_i$。$x_j$表示prompt的前缀。
2、获得残差$\delta_i=z_i-h_i^L$后,就是修改$\mathcal{R}$中每层FFN的权重$W_{out}^l$,使得模型关于$(s_i,r_i)$的表示$\hat{h}_i^L$尽可能接近$z_i$,也就是优化式(17/18)。修改权重需要获取每个权重对应的新的键$k_i^l$和值$m_i^l$,并且由于前一层的权重修改会影响后层的输入,因此需要从$\mathcal{R}$的第1层到第最后一层按顺序更新权重。每层的键可以直接通过前向传播得到,即式(19)。 值则是键$k_i^l$经过权重$W_{out}^l$映射后加上残差$ r_i^l$,如式(20)所示。作者将第$L$层的残差$\delta_i=z_i-h_i^L$分配给$\mathcal{R}$中的每一层,那为什么分母是$L-l+1$,而不是$L$呢?这是因为MLP的输出$m_i^{l}$改了,会导致下一层的注意力输出$a_i^{l+1}$也改了,所以总体改变量并不是直接对$m_i^l$的改变量求和的结果。
总的编辑算法如算法1所示,看起来$L,\mathcal{R}$对于一个批次中的每一个待更新事实都是固定的,具体细节还要看代码。
实验
表1:在GPT-J模型上修改zsRE数据集的10000个事实的对比结果,其中MEND基于元学习超网络可以并行编辑,ROME是安顺序编辑,这两个方法比正则化微调效果还差。
图5:各方法关于编辑事实的数量的指标变化图。ES为编辑准确率;PS为编辑后对同义句的准确率;NS为对不相关事实的准确率;RS是编辑后模型生成关于$s$的句子与参考句子的相似度;GE是生成关于$s$的句子的流畅度;CS是ES/PS/NS的调和平均。NS和GE应该和虚线也就是编辑前的模型相近。
表2:在GPT-J和GPT-NeoX上10000次编辑后的对比。
图6a:三个方法在反事实数据集中的不同关系对应事实的编辑得分。
图6b:通用性(同义句子的准确性)和特异性(无关事实的保持)的权衡。
图7:在并行编辑时混合包含不同关系的事实,对性能的影响。每个图都对两个关系事实的混合进行了编辑。可以看出混合编辑的结果和两个关系的事实分别单独进行编辑的结果的平均相近。
缺陷
文中指出,MEMIT只局限于有向关系,并且无法对空间时间推理、数学知识、语言知识、程序知识进行编辑,甚至无法泛化对称关系。例如,“库克是苹果首席执行官”必须与“苹果首席执行官是库克”分开处理。
论文解读:MASS-EDITING MEMORY IN A TRANSFORMER(MEMIT)的更多相关文章
- 论文解读(XR-Transformer)Fast Multi-Resolution Transformer Fine-tuning for Extreme Multi-label Text Classification
Paper Information Title:Fast Multi-Resolution Transformer Fine-tuning for Extreme Multi-label Text C ...
- [论文解读] 阿里DIEN整体代码结构
[论文解读] 阿里DIEN整体代码结构 目录 [论文解读] 阿里DIEN整体代码结构 0x00 摘要 0x01 文件简介 0x02 总体架构 0x03 总体代码 0x04 模型基类 4.1 基本逻辑 ...
- 自监督学习(Self-Supervised Learning)多篇论文解读(下)
自监督学习(Self-Supervised Learning)多篇论文解读(下) 之前的研究思路主要是设计各种各样的pretext任务,比如patch相对位置预测.旋转预测.灰度图片上色.视频帧排序等 ...
- 论文解读丨表格识别模型TableMaster
摘要:在此解决方案中把表格识别分成了四个部分:表格结构序列识别.文字检测.文字识别.单元格和文字框对齐.其中表格结构序列识别用到的模型是基于Master修改的,文字检测模型用到的是PSENet,文字识 ...
- 论文解读第三代GCN《 Deep Embedding for CUnsupervisedlustering Analysis》
Paper Information Titlel:<Semi-Supervised Classification with Graph Convolutional Networks>Aut ...
- NLP论文解读:无需模板且高效的语言微调模型(上)
原创作者 | 苏菲 论文题目: Prompt-free and Efficient Language Model Fine-Tuning 论文作者: Rabeeh Karimi Mahabadi 论文 ...
- itemKNN发展史----推荐系统的三篇重要的论文解读
itemKNN发展史----推荐系统的三篇重要的论文解读 本文用到的符号标识 1.Item-based CF 基本过程: 计算相似度矩阵 Cosine相似度 皮尔逊相似系数 参数聚合进行推荐 根据用户 ...
- CVPR2019 | Mask Scoring R-CNN 论文解读
Mask Scoring R-CNN CVPR2019 | Mask Scoring R-CNN 论文解读 作者 | 文永亮 研究方向 | 目标检测.GAN 推荐理由: 本文解读的是一篇发表于CVPR ...
- AAAI2019 | 基于区域分解集成的目标检测 论文解读
Object Detection based on Region Decomposition and Assembly AAAI2019 | 基于区域分解集成的目标检测 论文解读 作者 | 文永亮 学 ...
- Gaussian field consensus论文解读及MATLAB实现
Gaussian field consensus论文解读及MATLAB实现 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 一.Introduction ...
随机推荐
- 详细介绍Dubbo的SPI机制
一.定义 Dubbo 的 SPI (Service Provider Interface) 机制是对 Java 原生 SPI 机制的增强和扩展,提供了更强大的扩展能力 二.Dubbo SPI 核心实现 ...
- SpringBoot Task定时任务
参数详解 @Target({ElementType.METHOD, ElementType.ANNOTATION_TYPE}) @Retention(RetentionPolicy.RUNTIME) ...
- 三维装箱问题(3D Bin Packing Problem, 3D-BPP)
提出问题 集装箱海运家具, 沙发, 茶几, 椅子等等, 有多少套家具,以及每个家具的长宽高都会告诉你. 把所有的家具都装进集装箱里, 要求通过算法算出一共需要多少集装箱. 1.要考虑怎样装, 需要的集 ...
- 勒索病毒分析-2024wdb-re2
检查相关信息 可以看到病毒存在VMProtect虚拟壳 简单脱壳 首先我在x64debug中运行一次,发现没有中断退出,证明大概率没有反调试,但是有crc检测,所以尽量不下int3断点(脱壳时). 一 ...
- Spring纯注解的事务管理
Spring纯注解的事务管理 源码 代码测试 pom.xml <?xml version="1.0" encoding="UTF-8"?> < ...
- TreeSet练习 根据字符串长度排序
String类已经实现了Comparable接口,我们可以根据TreeSet提供的构造器传入自己的比较器. public class Set4 { public static void main(St ...
- SQL 条件求和
SUMIF 就是 Excel 中的 sumif () 函数的功能. 工作中用的频率极其高, 像我就几乎天天在用的呢. 也是做个简单的笔记而已. 为啥我总是喜欢对比 Excel 呢, 因为我也渐渐发现, ...
- 代码重构(OOP)-小栗子(PyQt5)
主要是为了练习下 面向对象, 不断提醒自己代码一定要写成 营销风格, 和优雅. 最近在B站上看一下关于 Python GUI 编程的内容. 恰好呢, 前不久的一个 将本地 Ecxcel 数据 发布到 ...
- trae开发的win10端口占用检测工具
前言 首先,强烈安利字节开发的工具:https://www.trae.com.cn/ 以下代码均由此工具生成. linux 中可以使用 lsof -i:端口号 查看端口占用进程,并使用kill指令杀死 ...
- scikit-learn生成随机数据集
%matplotlib inline from sklearn import datasets import matplotlib.pyplot as plt import numpy as np s ...