OCR性能优化:从认识BiLSTM网络结构开始
摘要: 想要对OCR进行性能优化,首先要了解清楚待优化的OCR网络的结构,本文从动机的角度来推演下基于Seq2Seq结构的OCR网络是如何一步步搭建起来的。
本文分享自华为云社区《OCR性能优化系列(一):BiLSTM网络结构概览》,原文作者:HW007。
OCR是指对图片中的印刷体文字进行识别,最近在做OCR模型的性能优化,用 Cuda C 将基于TensorFlow 编写的OCR网络重写了一遍,最终做到了5倍的性能提升。通过这次优化工作对OCR网络的通用网络结构和相关的优化方法有较深的认识,计划在此通过系列博文记录下来,也作为对自己最近工作的一个总结和学习笔记。
想要对OCR进行性能优化,首先要了解清楚待优化的OCR网络的结构,在本文中我将尝试着从动机的角度来推演下基于Seq2Seq结构的OCR网络是如何一步步搭建起来的。
读懂此文的前提只需要了解在矩阵乘法中矩阵的维度变化规律,即n*p的矩阵乘以 p*m 的矩阵等于 n*m 的矩阵。如果知道CNN和RNN网络的结构,对机器学习模型的构造套路有点了解的话更好。
首先给出从本文要剖析的OCR BILSTM 网络总体结构如下图:

接下来我将从这张图的右上角(模型的输出端)向左下角(模型的输入端)逐步解释每一个结构的动机及其作用。
1. 构造最简单的OCR网络
首先考虑最简单情况下的OCR识别场景,假设输入是只含有一个文字图片,图片的高和宽均为32个像素,即32*32的矩阵,为了方便将其拉长便可得到一个 1*1024 的矩阵。在输出方面,由于文字的特殊性,我们只能将所有的文字进行标号,最后输出所识别的文字的编号便好,由此得到我们的输出是一个 1*1 的矩阵,矩阵元素的内容就是所识别的文字的编号。
怎么得到这个1*1的矩阵呢?根据概率统计的套路,我们假设全世界存在10000个文字,将其表为1~1000号,那么这10000个元素都有概率成为我们的输出,因此我们如果先算出这10000个文字作为该输入图片的识别结果的概率的话,再挑概率最大的那个输出便可以了。于是问题被转变成如何从一个 1*1024的矩阵(X)中得到一个 1*10000 的矩阵(Y)。在这里便可以上机器学习模型结构中最常见的线性假设套路了,假设Y和X是之间是线性相关的,这样便可得到最简单且经典的线性模型:Y = AX + B。 其中称X(维度:1*1024)为输入,Y(维度:1*10000)为输出,A和B均为该模型的参数,由矩阵乘法可知A的维度应该是 1024*1000,B的维度应该是 1*10000。至此,只有X是已知的,我们要计算Y的话还需要知道A和B的具体值。在机器学习的套路中,作为参数的A和B的值在一开始是随机设定的,然后通过喂大量的X及其标准答案Y来让机器把这两个参数A、B慢慢地调整到最优值,此过程称为模型的训练,喂进去的数据称为训练数据。训练完后,你便可以拿最优的A乘以你的新输入X在加上最优的B得到相应的Y了,使用argMax操作来挑选Y这1*10000个数中最大的那个数的编号,就是识别出来的文字的编号了。
现在,再回头去看图1中右上角的那部分,相信你能看懂两个黄色的 384*10000 和 1*10000的矩阵的含义了。图中例子和上段文字描述的例子的区别主要在于图中的输入是1张 1*1024的图片,上段文字中的是 27张 1*384的图片罢了。至此,你已经了解如何构造一个简单地OCR网络了。接下来我们就开始对这个简单地网络进行优化。
2. 优化策略一:减少计算量
在上面的文字描述的例子中,我们每识别一个文字就要做一次 1*1024和1024*10000的矩阵乘法计算,这里面计算量太大了,是否有一些计算是冗余的呢?熟悉PCA的人应该马上能想到,其实将 32*32 的文字图片拉长为 1*1024的矩阵,这个文字的特征空间是1024维,即便每维的取值只有0和1两种,这个特征空间可表示的值都有2^1024种,远远大于我们所假设的文字空间中所有文字个数10000个。为此我们可以用PCA或各种降维操作把这个输入的特征向量降维到小于10000维,比如像图中的128维。
3. 优化策略二:考虑文字间的相关性
(提醒:在上图中为了体现出batch Size的维度,是按27张文字图片来画的,下文中的讨论均只针对1张文字图片,因此下文中维度为 1的地方均对应着图中的27)
也许你已经注意到了,图中与黄色的384*10000矩阵相乘的“位置图像特征”的维度没有直接用一个1*384,而是 1*(128+128+128)。其实这里隐含着一个优化,这个优化是基于文字间的关联假设的,简单地例子就是如果前面一个字是“您”,那其后面跟着的很可能是“好”字,这种文字顺序中的统计规律应该是可以用来提升文字图片的识别准确率的。那怎么来实现这个关联呢?
在图中我们可以看到左侧有一个10000*128的参数矩阵,很容易知道这个参数就像一个数据库,其保存了所有10000个文字图片经过加工后的特征(所谓加工便是上面提到的降维,原始特征应该是 10000*1024的),照图中的结构,我需要输入当前识别的这个字的前一个字的识别结果 (识别工作是一个字接一个字串行地识别出来的)。然后选择出上个字对应的特征矩阵 1*128,再经过一些加工转换后当做1*384的输入中的前1/3部分内容。
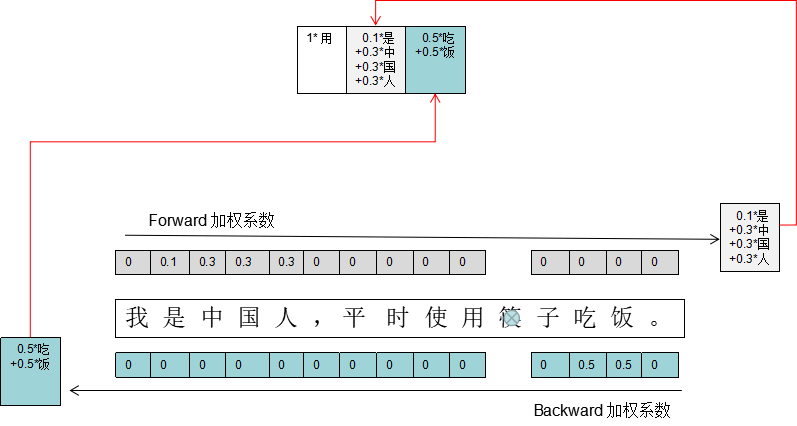
同理,1*384里靠后的两个1*128又代表什么含义呢?虽然在句子中,前面一个字对后面一个字的影响很大,即使当前要预测的字在图片中很模糊,我也可以根据前面的字将其猜出来。那是否可以根据其前k个字或者后k个字猜出来呢?显然答案是肯定的。因此靠后的两个1*128分别代表的是句子图片里文字“从前到后(Forward)”和“从后到前(Backward)”的图片特征对当前要识别的字的影响,因此图中在前面加了个“双向LSTM网络”来生成这两个特征。
至此,改良版的OCR网络轮廓基本出来了,还有一些细节上的问题需要解决。不知你是否注意到,按上面所述,1*384中包含了3个1*128的特征,分别代表着前一个字对当前字的影响、图片中的整个句子中各个文字从前到后(Forward)的排序对当前文字的影响、图片中的整个句子中各个文字从后到前(Backward)的排序对当前文字的影响。
但是他们的特征长度都是128!!!一个字是128,一个句子也是128?对于不同的文字图片中,句子的长度还可能不一样,怎么可能都用一个字的特征长度就表示了呢?
如何表示一个可变长的句子的特征呢?乍一看的确是个很棘手的问题,好在它有一个很粗暴简单的解决办法,就是加权求和,又是概率统计里面的套路,管你有几种情况,所有的情况的概率求和后都得等于1。看到在这里不知道是否被震撼到,“变化”和“不变”这样看起来水火不容的两个东西就是这么神奇地共存了,这就是数学的魅力,让人不禁拍手赞绝!
下图以一个实际的例子说明这种神奇的方式的运作方式。当我们要对文字片段中的“筷”字进行识别时,尽管改字已近被遮挡了部分,但根据日常生活中的一些经验知识积累,要对该位置进行补全填空时,我们联系上下文,把注意力放在上文中的“是中国人”和下文中的“吃饭”上。这个加权系数的机制便是用来实现这种注意力机制的。至于“日常生活中的经验”这种东西就是由“注意力机制网络”通过大量的训练数据来学习得到的。也就是图1中的那32个alpha的由来。注意力网络在业界一般由GRU网络担任,由于篇幅原因,在此不展开了,下回有机会再细说。看官们只需知道在图一的右边还应该有个“注意力网络”来输出32个alpha的值便好。
OCR性能优化:从认识BiLSTM网络结构开始的更多相关文章
- 01.SQLServer性能优化之----强大的文件组----分盘存储
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 文章内容皆自己的理解,如有不足之处欢迎指正~谢谢 前天有学弟问逆天:“逆天,有没有一种方 ...
- 03.SQLServer性能优化之---存储优化系列
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 概 述:http://www.cnblogs.com/dunitian/p/60413 ...
- Web性能优化:What? Why? How?
为什么要提升web性能? Web性能黄金准则:只有10%~20%的最终用户响应时间花在了下载html文档上,其余的80%~90%时间花在了下载页面组件上. web性能对于用户体验有及其重要的影响,根据 ...
- Web性能优化:图片优化
程序员都是懒孩子,想直接看自动优化的点:传送门 我自己的Blog:http://cabbit.me/web-image-optimization/ HTTP Archieve有个统计,图片内容已经占到 ...
- C#中那些[举手之劳]的性能优化
隔了很久没写东西了,主要是最近比较忙,更主要的是最近比较懒...... 其实这篇很早就想写了 工作和生活中经常可以看到一些程序猿,写代码的时候只关注代码的逻辑性,而不考虑运行效率 其实这对大多数程序猿 ...
- JavaScript性能优化
如今主流浏览器都在比拼JavaScript引擎的执行速度,但最终都会达到一个理论极限,即无限接近编译后程序执行速度. 这种情况下决定程序速度的另一个重要因素就是代码本身. 在这里我们会分门别类的介绍J ...
- 02.SQLServer性能优化之---牛逼的OSQL----大数据导入
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 上一篇:01.SQLServer性能优化之----强大的文件组----分盘存储 http ...
- C++ 应用程序性能优化
C++ 应用程序性能优化 eryar@163.com 1. Introduction 对于几何造型内核OpenCASCADE,由于会涉及到大量的数值算法,如矩阵相关计算,微积分,Newton迭代法解方 ...
- Android性能优化之利用LeakCanary检测内存泄漏及解决办法
前言: 最近公司C轮融资成功了,移动团队准备扩大一下,需要招聘Android开发工程师,陆陆续续面试了几位Android应聘者,面试过程中聊到性能优化中如何避免内存泄漏问题时,很少有人全面的回答上来. ...
- 前端性能优化的另一种方式——HTTP2.0
最近在读一本书叫<web性能权威指南>谷歌公司高性能团队核心成员的权威之作. 一直听说HTTP2.0,对此也仅仅是耳闻,没有具体研读过,这次正好有两个篇章,分别讲HTTP1.1和HTTP2 ...
随机推荐
- 谈谈selenium4.0中的相对定位
相对定位历史 2021-10-13 发布的 selenium 4.0 开始引入,selenium 3.X是没有的 implement relative locator for find_element ...
- Wonder8.promotion营销规则引擎,轻松搞掂千变万化的营销玩法
超过10年没有更新过内容了,不知道现在园子的氛围这类文章还适不适合放首页 想着整点内容,也是支持园子! 旺德發.营销 引擎 概述 为了广泛支持营销活动的复杂与灵活,Wonder8.promotion( ...
- XML文件的解析--libxml库函数解释
[c语言]XML文件的解析--libxml库函数解释 2009-09-02 13:12 XML文件的解析--libxml库函数解释 libxml(一) ...
- dotnet 探究 SemanticKernel 的 planner 的原理
在使用 SemanticKernel 时,我着迷于 SemanticKernel 强大的 plan 能力,通过 plan 功能可以让 AI 自动调度拼装多个模块实现复杂的功能.我特别好奇 Semant ...
- java固定窗口大小
this.setResizable(false);//////frame.setResizable(false)
- style绑定及随机颜色
一个小案例 颜色变换 style单机事件的绑定
- Head First Java学习:第十一章-异常处理
第十一章 异常处理 1.方法可以抓住其他方法所抛出的异常:异常总是丢回给调用方 有风险.会抛出异常的程序代码: 负责声明异常:创建Exception对象并抛出 调用该方法的程序代码: 在try中调用程 ...
- 将多个txt文件中的内容写在一个txt中的方法
import os filename='./train_data/img_' for i in range(1,19736): newfile=filename+str(i)+'.txt' if os ...
- Diffusion Model扩散模型
1.扩散模型基本原理: 扩散模型包括两个步骤: 固定的(或预设的)前向扩散过程q:该过程会逐渐将高斯噪声添加到图像中,直到最终得到纯噪声. 2.可训练的反向去噪扩散过程pθ:训练一个神经网络,从纯噪音 ...
- HDU-3591 混合背包
The trouble of Xiaoqian Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/ ...