如何快速部署本地训练的 Bert-VITS2 语音模型到 Hugging Face

Hugging Face是一个机器学习(ML)和数据科学平台和社区,帮助用户构建、部署和训练机器学习模型。它提供基础设施,用于在实时应用中演示、运行和部署人工智能(AI)。用户还可以浏览其他用户上传的模型和数据集。Hugging Face通常被称为机器学习界的GitHub,因为它让开发人员公开分享和测试他们所训练的模型。
本次分享如何快速部署本地训练的 Bert-VITS2 语音模型到 Hugging Face。
本地配置HuggingFace
首先注册HuggingFace平台:
https://huggingface.co/join
随后在用户的设置界面新建token,也就是令牌:

这里令牌有两种权限类型,一种是写权限,另外一种是读权限。
随后本地安装Huggingface客户端:
pip install huggingface_hub
随后运行命令登录Huggingface账号:
huggingface-cli login
此时需要用到刚刚创建的token,复制写token,粘贴到命令行中:
E:\work>huggingface-cli login
_| _| _| _| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _|_|_|_| _|_| _|_|_| _|_|_|_|
_| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_|_|_|_| _| _| _| _|_| _| _|_| _| _| _| _| _| _|_| _|_|_| _|_|_|_| _| _|_|_|
_| _| _| _| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_| _| _|_| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _| _| _| _|_|_| _|_|_|_|
A token is already saved on your machine. Run `huggingface-cli whoami` to get more information or `huggingface-cli logout` if you want to log out.
Setting a new token will erase the existing one.
To login, `huggingface_hub` requires a token generated from https://huggingface.co/settings/tokens .
Token can be pasted using 'Right-Click'.
Token:
Add token as git credential? (Y/n) y
Token is valid (permission: write).
Cannot authenticate through git-credential as no helper is defined on your machine.
You might have to re-authenticate when pushing to the Hugging Face Hub.
Run the following command in your terminal in case you want to set the 'store' credential helper as default.
git config --global credential.helper store
Read https://git-scm.com/book/en/v2/Git-Tools-Credential-Storage for more details.
Token has not been saved to git credential helper.
Your token has been saved to C:\Users\zcxey\.cache\huggingface\token
Login successful
显示Login successful即代表登录成功。
随后,可以使用命令来创建模型的repo项目:
huggingface-cli repo create wizard3
这里创建巫师3系列角色模型。
程序返回:
E:\work>huggingface-cli repo create wizard3
git version 2.31.0.windows.1
git-lfs/2.13.2 (GitHub; windows amd64; go 1.14.13; git fc664697)
You are about to create v3ucn/wizard3
Proceed? [Y/n] y
Your repo now lives at:
https://huggingface.co/v3ucn/wizard3
You can clone it locally with the command below, and commit/push as usual.
git clone https://huggingface.co/v3ucn/wizard3
说明已经创建好模型项目了。
当然,过程中可能会报443的错误,如果您身在国内,这是十分合理的现象。
此时,可以通过给git配置代理来解决:
配置socks5
git config --global http.proxy socks5 127.0.0.1:7890
git config --global https.proxy socks5 127.0.0.1:7890
配置http
git config --global http.proxy 127.0.0.1:7890
git config --global https.proxy 127.0.0.1:7890
其中7890为您在国内学术上网用的端口号,啥叫学术上网?很抱歉这里无法多做解释。
同时也可以通过命令取消git学术上网:
git config --global --unset http.proxy
git config --global --unset https.proxy
接着本地克隆项目:
git clone https://huggingface.co/v3ucn/wizard3
随后将模型本体和配置文件config.json放入wizard3目录。
提交后,推送即可:
E:\work>cd wizard3
E:\work\wizard3>git add -A
E:\work\wizard3>git commit -m "commit from liuyue "
[main cd327b9] commit from liuyue
2 files changed, 114 insertions(+)
create mode 100644 G_200.pth
create mode 100644 config.json
E:\work\wizard3>git push
Uploading LFS objects: 0% (0/1), 925 MB | 2.4 MB/s
此时,git就会把模型推送到Huggingface云端。
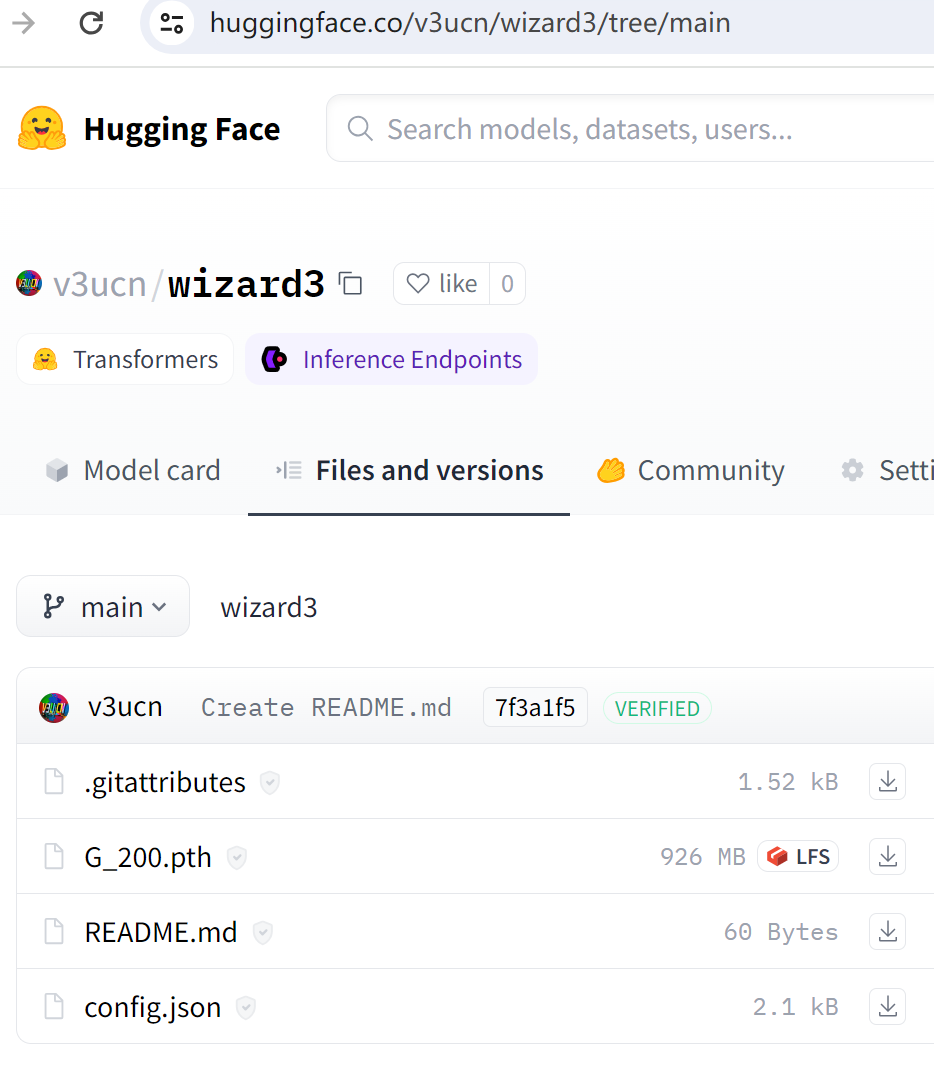
推送完毕后,访问线上地址,即可查看模型:
https://huggingface.co/v3ucn/wizard3/tree/main
结语
Hugging Face的优势包括可访问性、集成性、快速原型设计和部署、社区和成本效益,是不可多得的机器学习交流平台。
如何快速部署本地训练的 Bert-VITS2 语音模型到 Hugging Face的更多相关文章
- docker快速部署本地项目到服务器(tomcat8+mysql8)
目标是:将本地运行的spring项目,部署到服务器上 为什么使用docker? 环境隔离 服务器上,各种环境交杂,使用docker,能清楚的把各个项目进行隔离,不单维护的人员方便,也会省去很多维护这些 ...
- 三分钟快速上手TensorFlow 2.0 (下)——模型的部署 、大规模训练、加速
前文:三分钟快速上手TensorFlow 2.0 (中)——常用模块和模型的部署 TensorFlow 模型导出 使用 SavedModel 完整导出模型 不仅包含参数的权值,还包含计算的流程(即计算 ...
- 使用VMDepot镜像快速部署CKAN开放数据门户
最新发布的CKAN VMDepot镜像针对中国用户强化了中文支持,提升了与MS Office办公软件的互操作性,并集成了常用插件和最佳实践配置参数. 使得CKAN原本十分复杂繁琐的部署流程变得非常简单 ...
- 【转】使用sinopia五步快速完成本地npm搭建
使用sinopia五步快速完成本地npm搭建 时间 2016-03-01 14:55:30 繁星UED 原文 http://ued.fanxing.com/shi-yong-sinopiawu-b ...
- 如何快速部署国人开源的 Java 博客系统 Tale
除了闷头专研技术之外,程序员还需要不断地写作进行技术积累,写博客是其中最重要的方式之一.商业博客平台不少,但是更符合程序员背景的方案,是自己开发一个博客平台或者使用开源的博客平台. 开源的博客平台多如 ...
- 如何使用华为软件开发云快速部署PHP网站
华为软件开发云这个工具,从去年推出我就一直在关注,毕竟是华为最新的一款软件开发工具,最近我一直在使用华为软件开发云进行开发项目管理,它有在线编译和构建.云端在线代码检查等功能,编译省去了很多物理机器的 ...
- Hexo快速部署教程
一直有建立博客的需要,使用过Wordpress动态博客,一直访问速度比较慢,刚开始以为是空间域名的解析的问题,尝试使用Hexo静态博客,部署后感觉速度正常很多,特意发文快速部署教程 准备 本文是在wi ...
- 【干货】快速部署微软开源GPU管理利器: OpenPAI
[干货]快速部署微软开源GPU管理利器: OpenPAI 介绍 不管是机器学习的老手,还是入门的新人,都应该装备上尽可能强大的算力.除此之外,还要压榨出硬件的所有潜力来加快模型训练.OpenPAI作为 ...
- 【技术解析】如何用Docker实现SequoiaDB集群的快速部署
1. 背景 以Docker和Rocket为代表的容器技术现在正变得越来越流行,它改变着公司和用户创建.发布.运行分布式应用的方式,在未来5年将给云计算行业带来它应有的价值.它的诱人之处在于: 1)资源 ...
- 简单快速部署nexus3私服
本文适用范围:用户规模不大,不需要考虑maven仓库负载均衡的群体. 为何部署nexus3 之前由于懒某些原因,所有开发人员自己定义.m2的settings,大多使用ali提供的maven仓库,但是最 ...
随机推荐
- css中的字体样式
一.字体的样式 font-style:"normal" 正常 font-style:"italic"斜体 二.字体的粗细 font-weight:"b ...
- 19c上ADG主库sys密码修改会影响备库同步吗?
一套Oracle 19c的ADG集群要修改sys密码,由于之前遇见过11g上sys密码修改导致同步问题的情况,所以改之前特意查了下文档,发现其实12cR2开始,在主库修改密码就会自动同步到备库了,以下 ...
- CF431C
题目简化和分析: k叉树,乍一看好像是树论,但我们通过分析条件,发现它每个阶段要做的事情一样,皆为:\(1\sim k\) 中选数字,这就很明显是DP. \(\mathit{f}_{i,0}\) 表示 ...
- 【BUU刷题日记】——第一周
[BUU刷题日记]--第一周 一.[极客大挑战 2019]PHP1 题目说自己有一个备份网站的习惯,所以要了解一下常见的网站源码备份格式及文件名: 格式:tar.tar.gz.zip.rar 文件名: ...
- 解决 IAR中 Warning[Pa082] 的警告问题
这个警告不属于严重问题 在 IAR (for STM8)的编译中,经常有如下的警告: Warning[Pa082]: undefined behavior: the order of volatile ...
- 使用JWT、拦截器与ThreadLocal实现在任意位置获取Token中的信息,并结合自定义注解实现对方法的鉴权
1. 简介 1.1 JWT JWT,即JSON Web Token,是一种用于在网络上传递声明的开放标准(RFC 7519).JWT 可以在用户和服务器之间传递安全可靠的信息,通常用于身份验证和信息交 ...
- KMeans算法全面解析与应用案例
本文深入探讨了KMeans聚类算法的核心原理.实际应用.优缺点以及在文本聚类中的特殊用途,为您在聚类分析和自然语言处理方面提供有价值的见解和指导. 关注TechLead,分享AI全维度知识.作者拥有1 ...
- 本地训练,开箱可用,Bert-VITS2 V2.0.2版本本地基于现有数据集训练(原神刻晴)
按照固有思维方式,深度学习的训练环节应该在云端,毕竟本地硬件条件有限.但事实上,在语音识别和自然语言处理层面,即使相对较少的数据量也可以训练出高性能的模型,对于预算有限的同学们来说,也没必要花冤枉钱上 ...
- [GDOIpj221B] 数列游戏
第二题 数列游戏 提交文件: sequence.cpp 输入文件: sequence.in 输出文件: sequence.out 时间空间限制: 1 秒, 256 MB 有一个长度为 \(n\) 的序 ...
- 如何判断lib和dll是32位还是64位?答案是使用微软的dumpbin工具,后面讲了如何使用gcc生成lib和dll
为什么我会考虑这个问题呢?因为我在使用java去调用一个c的lib库的时候,弹出以下警告: D:\work\ideaworkpaces\jdk21Test001\src\main\java\lib\h ...