hadoop本地运行模式调试
一:简介
最近学习hadoop本地运行模式,在运行期间遇到一些问题,记录下来备用;以运行hadoop下wordcount为例子。
hadoop程序是在集群运行还是在本地运行取决于下面两个参数的设置,第一个参数用来设置mr程序要在yarn集群中执行,第二个参数设置yarn集群的主节点地址。
hadoop默认情况下是在window本地运行。
conf.set("mapreduce.framework.name","yarn");
conf.set("yarn.resourcemanager.hostname","hadoop-server-03");
问题一:Exception in thread "main" java.lang.NullPointerException atjava.lang.ProcessBuilder.start(Unknown Source)
本地运行hadoop报错
log4j:WARNPlease initialize the log4j system properly.
log4j:WARN Seehttp://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Exception in thread "main" java.lang.NullPointerException
atjava.lang.ProcessBuilder.start(Unknown Source)
atorg.apache.hadoop.util.Shell.runCommand(Shell.java:482)
atorg.apache.hadoop.util.Shell.run(Shell.java:455)
atorg.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:715)
atorg.apache.hadoop.util.Shell.execCommand(Shell.java:808)
atorg.apache.hadoop.util.Shell.execCommand(Shell.java:791)
at
分析:
下载Hadoop2以上版本时,在Hadoop2的bin目录下没有winutils.exe
解决:
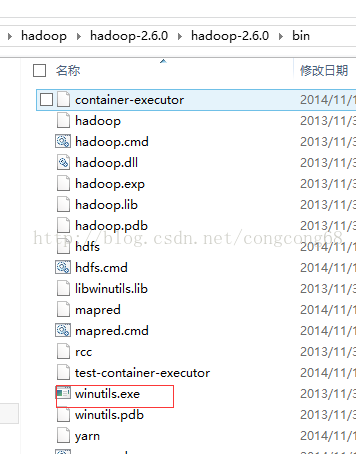
1.下载https://codeload.github.com/srccodes/hadoop-common-2.2.0-bin/zip/master下载hadoop-common-2.2.0-bin-master.zip,然后解压后,把hadoop-common-2.2.0-bin-master下的bin全部复制放到我们下载的Hadoop2的binHadoop2/bin目录下。如图所示:
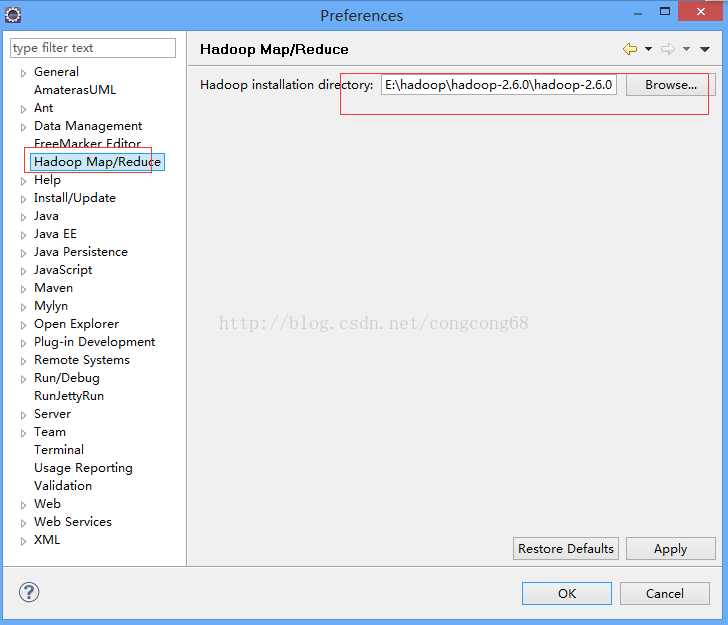
2.Eclipse-》window-》Preferences 下的Hadoop Map/Peduce 把下载放在我们的磁盘的Hadoop目录引进来,如图所示:
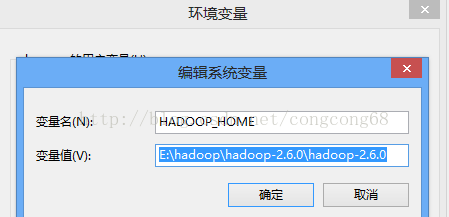
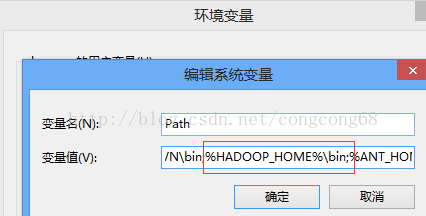
3.Hadoop2配置变量环境HADOOP_HOME 和path,如图所示:
问题二.Exception in thread "main"java.lang.UnsatisfiedLinkError:org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
当我们解决了问题三时,在运行WordCount.java代码时,出现这样的问题
- log4j:WARN No appenders could be found forlogger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
- log4j:WARN Please initialize the log4jsystem properly.
- log4j:WARN Seehttp://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
- Exception in thread "main"java.lang.UnsatisfiedLinkError:org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
- atorg.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Native Method)
- atorg.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:557)
- atorg.apache.hadoop.fs.FileUtil.canRead(FileUtil.java:977)
- atorg.apache.hadoop.util.DiskChecker.checkAccessByFileMethods(DiskChecker.java:187)
- atorg.apache.hadoop.util.DiskChecker.checkDirAccess(DiskChecker.java:174)
- atorg.apache.hadoop.util.DiskChecker.checkDir(DiskChecker.java:108)
- atorg.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.confChanged(LocalDirAllocator.java:285)
- atorg.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.getLocalPathForWrite(LocalDirAllocator.java:344)
- atorg.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:150)
- atorg.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:131)
- atorg.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:115)
- atorg.apache.hadoop.mapred.LocalDistributedCacheManager.setup(LocalDistributedCacheManager.java:131)
分析:
C:\Windows\System32下缺少hadoop.dll,把这个文件拷贝到C:\Windows\System32下面即可。
如果是windows是64位操作系统,将hadoop.dll文件拷贝到C:\Windows\SysWOW64下面即可。
解决:
hadoop-common-2.2.0-bin-master下的bin的hadoop.dll放到C:\Windows\System32下,然后重启电脑,也许还没那么简单,还是出现这样的问题。
我们在继续分析(这个问题我并没有遇到):
我们在出现错误的的atorg.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:557)我们来看这个类NativeIO的557行,如图所示:
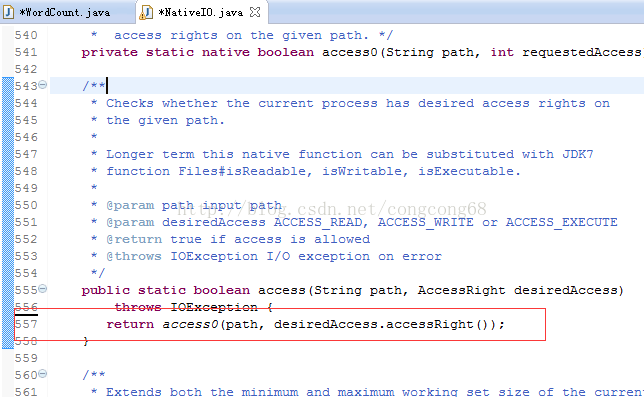
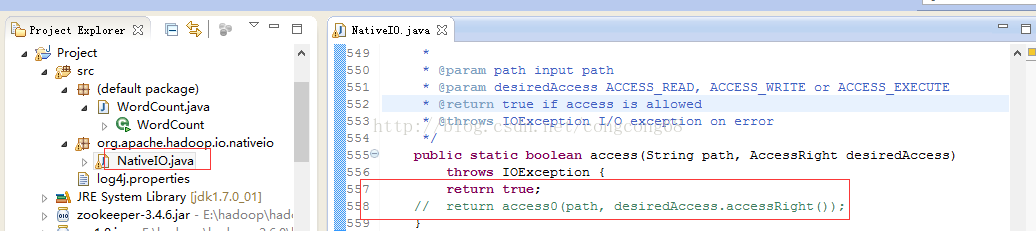
Windows的唯一方法用于检查当前进程的请求,在给定的路径的访问权限,所以我们先给以能进行访问,我们自己先修改源代码,return true 时允许访问。我们下载对应hadoop源代码,hadoop-2.6.0-src.tar.gz解压,hadoop-2.6.0-src\hadoop-common-project\hadoop-common\src\main\java\org\apache\hadoop\io\nativeio下NativeIO.java 复制到对应的Eclipse的project,然后修改557行为return true如图所示:
问题三:org.apache.hadoop.security.AccessControlException: Permissiondenied: user=zhengcy, access=WRITE,inode="/user/root/output":root:supergroup:drwxr-xr-x
我们在执行运行WordCount.java代码时,出现这样的问题
- 2014-12-18 16:03:24,092 WARN (org.apache.hadoop.mapred.LocalJobRunner:560) - job_local374172562_0001
- org.apache.hadoop.security.AccessControlException: Permission denied: user=zhengcy, access=WRITE, inode="/user/root/output":root:supergroup:drwxr-xr-x
- at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkFsPermission(FSPermissionChecker.java:271)
- at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:257)
- at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:238)
- at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:179)
- at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkPermission(FSNamesystem.java:6512)
- at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkPermission(FSNamesystem.java:6494)
- at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkAncestorAccess(FSNamesystem.java:6446)
- at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirsInternal(FSNamesystem.java:4248)
- at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirsInt(FSNamesystem.java:4218)
- at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:4191)
- at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.mkdirs(NameNodeRpcServer.java:813)
分析:
我们没权限访问output目录。
解决方法:
执行赋权限语句: hadoop fs -chmod -R 777 /wordcount/output
重新执行,hadoop程序在本地终于运行成功了。
hadoop本地运行模式调试的更多相关文章
- 大数据-Hadoop 本地运行模式
Grep案例 1. 创建在hadoop-2.7.2文件下面创建一个input文件夹 [atguigu@hadoop101 hadoop-2.7.2]$ mkdir input 2. 将Hadoop的x ...
- Hadoop之运行模式
Hadoop运行模式包括:本地模式.伪分布式以及完全分布式模式. 一.本地运行模式 1.官方Grep案例 1)在hadoop-2.7.2目录下创建一个 input 文件夹 [hadoop@hadoop ...
- spark之scala程序开发(本地运行模式):单词出现次数统计
准备工作: 将运行Scala-Eclipse的机器节点(CloudDeskTop)内存调整至4G,因为需要在该节点上跑本地(local)Spark程序,本地Spark程序会启动Worker进程耗用大量 ...
- hadoop本地运行与集群运行
开发环境: windows10+伪分布式(虚拟机组成的集群)+IDEA(不需要装插件) 介绍: 本地开发,本地debug,不需要启动集群,不需要在集群启动hdfs yarn 需要准备什么: 1/配置w ...
- 2 weekend110的mapreduce介绍及wordcount + wordcount的编写和提交集群运行 + mr程序的本地运行模式
把我们的简单运算逻辑,很方便地扩展到海量数据的场景下,分布式运算. Map作一些,数据的局部处理和打散工作. Reduce作一些,数据的汇总工作. 这是之前的,weekend110的hdfs输入流之源 ...
- 开发函数计算的正确姿势 —— 使用 Fun Local 本地运行与调试
前言 首先介绍下在本文出现的几个比较重要的概念: 函数计算(Function Compute): 函数计算是一个事件驱动的服务,通过函数计算,用户无需管理服务器等运行情况,只需编写代码并上传.函数计算 ...
- hadoop的运行模式
概述 1)资料查询(官方网址) (1)官方网站: http://hadoop.apache.org/ (2)各个版本归档库地址 https://archive.apache.org/dist/hado ...
- Storm的本地运行模式示例
以word count为例,本地化运行模式(不需要安装zookeeper.storm集群),maven工程, pom.xml文件如下: <project xmlns="http://m ...
- MapReduce本地运行模式wordcount实例(附:MapReduce原理简析)
1. 环境配置 a) 配置系统环境变量HADOOP_HOME b) 把hadoop.dll文件放到c:/windows/System32目录下 c) ...
随机推荐
- C++学习(十)(C语言部分)之 分支语句
#include<stdio.h> // std 标准 io ----> input output 输入 输出 printf scanf getchar ...... #i ...
- 第一个程序HelloWorld及常见问题解决和练习
public class hello world{ public static void main(String[] args){ System.out.println(); } } 注意事项: 源文 ...
- python编译hello
pycharm无法找到解释器,将无法编译. 所以在编译之前进行统一设置 点击File,选择settings,点击 添加解释器 最后点击Apply.等待系统配置. 如果我们需要添加新的模块,点击绿色+号 ...
- torchvision库简介(翻译)
部分跟新于:4.24日 torchvision 0.2.2.post3 torchvision是独立于pytorch的关于图像操作的一些方便工具库. torchvision的详细介绍在:http ...
- linux 文件管理操作入门
mkdir -p /root/kali/bp/shell 一路创建文件夹直到生成文件夹shell,中间没有kali文件夹的话也会自动创建生成 tar解压缩 范例一:将整个 /etc 目录下的文件全部 ...
- Java(命令行)打印库存清单
public class demo{ public static void main(String[] args){ //1 顶部 System.out.println("--------- ...
- Docker—微软微服务
容器与Docker简介(一)——微软微服务电子书翻译系列 容器与Docker简介(二)什么是DOCKER——微软微服务电子书翻译系列 容器与Docker简介(三)Docker相关术语——微软微服务电子 ...
- How to implement a windbg plugin
How to implement a windbg plugin Define EXT_CLASS #include "lauxlib.h" class EXT_CLASS : p ...
- PyCharm中的Console自动换行
菜单栏-> File -> Settings -> Editor -> General -> Console,选中右侧Use soft wraps in console前 ...
- MinGW与Cygwin的一些杂谈
引用:http://www.cnblogs.com/fancybit/archive/2012/07/08/2581590.html 首先MingW和cygwin都可以用来跨平台开发. MinGW是 ...