大数据-Hadoop 本地运行模式
Grep案例
1. 创建在hadoop-2.7.2文件下面创建一个input文件夹
[atguigu@hadoop101 hadoop-2.7.2]$ mkdir input
2. 将Hadoop的xml配置文件复制到input
[atguigu@hadoop101 hadoop-2.7.2]$ cp etc/hadoop/*.xml input

3. 执行share目录下的MapReduce程序(执行)
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hadoop jar
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'(要正常的运行,必须要保证output删除,没有才能运行)

4. 查看输出结果
[atguigu@hadoop101 hadoop-2.7.2]$ cat output/*

WordCount案例
1. 创建在hadoop-2.7.2文件下面创建一个wcinput文件夹
[atguigu@hadoop101 hadoop-2.7.2]$ mkdir wcinput
2. 在wcinput文件下创建一个wc.input文件
[atguigu@hadoop101 hadoop-2.7.2]$ cd wcinput
[atguigu@hadoop101 wcinput]$ touch wc.input
3. 编辑wc.input文件
[atguigu@hadoop101 wcinput]$ vi wc.input
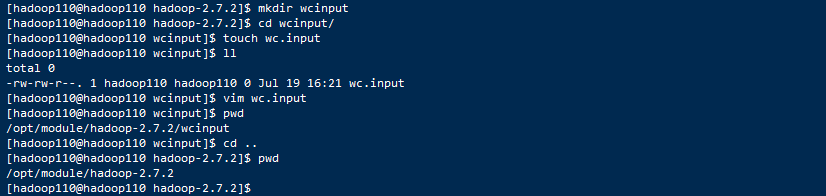
保存退出::wq
4. 回到Hadoop目录/opt/module/hadoop-2.7.2
5. 执行程序
[atguigu@hadoop101 hadoop-2.7.2]$ hadoop jar
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput

6. 查看结果
[atguigu@hadoop101 hadoop-2.7.2]$ cat wcoutput/part-r-00000

大数据-Hadoop 本地运行模式的更多相关文章
- hadoop本地运行模式调试
一:简介 最近学习hadoop本地运行模式,在运行期间遇到一些问题,记录下来备用:以运行hadoop下wordcount为例子. hadoop程序是在集群运行还是在本地运行取决于下面两个参数的设置,第 ...
- 大数据Hadoop入门视频教程:Hadoop的快如入门
最新在学习hadoop .storm大数据相关技术,发现网上hadoop .storm 相关学习视频少之又少,这里整理了传智播客段海涛老师的hadoop学习视频,出来给大家学习交流. 视频下载地址:h ...
- 2 weekend110的mapreduce介绍及wordcount + wordcount的编写和提交集群运行 + mr程序的本地运行模式
把我们的简单运算逻辑,很方便地扩展到海量数据的场景下,分布式运算. Map作一些,数据的局部处理和打散工作. Reduce作一些,数据的汇总工作. 这是之前的,weekend110的hdfs输入流之源 ...
- 大数据Hadoop学习之搭建hadoop平台(2.2)
关于大数据,一看就懂,一懂就懵. 一.概述 本文介绍如何搭建hadoop分布式集群环境,前面文章已经介绍了如何搭建hadoop单机环境和伪分布式环境,如需要,请参看:大数据Hadoop学习之搭建had ...
- Hadoop大数据学习视频教程 大数据hadoop运维之hadoop快速入门视频课程
Hadoop是一个能够对大量数据进行分布式处理的软件框架. Hadoop 以一种可靠.高效.可伸缩的方式进行数据处理适用人群有一定Java基础的学生或工作者课程简介 Hadoop是一个能够对大量数据进 ...
- Hadoop之运行模式
Hadoop运行模式包括:本地模式.伪分布式以及完全分布式模式. 一.本地运行模式 1.官方Grep案例 1)在hadoop-2.7.2目录下创建一个 input 文件夹 [hadoop@hadoop ...
- spark之scala程序开发(本地运行模式):单词出现次数统计
准备工作: 将运行Scala-Eclipse的机器节点(CloudDeskTop)内存调整至4G,因为需要在该节点上跑本地(local)Spark程序,本地Spark程序会启动Worker进程耗用大量 ...
- hadoop本地运行与集群运行
开发环境: windows10+伪分布式(虚拟机组成的集群)+IDEA(不需要装插件) 介绍: 本地开发,本地debug,不需要启动集群,不需要在集群启动hdfs yarn 需要准备什么: 1/配置w ...
- 我要进大厂之大数据Hadoop HDFS知识点(1)
01 我们一起学大数据 老刘今天开始了大数据Hadoop知识点的复习,Hadoop包含三个模块,这次先分享出Hadoop中的HDFS模块的基础知识点,也算是对今天复习的内容进行一次总结,希望能够给想学 ...
随机推荐
- linux 修改IP, DNS -(转自fighter)
linux下修改IP.DNS.路由命令行设置 ubuntu 版本命令行设置IP cat /etc/network/interfaces # This file describes the networ ...
- 服务器RAID配置
一.RAID介绍RAID是Redundent Array of Inexpensive Disks的缩写,直译为"廉价冗余磁盘阵列",也简称为"磁盘阵列".后来 ...
- linux下 find命令使用
按名称查找 find . -name filename [root@vps repo]# ls README.md vps.sh[root@vps repo]# find . -iname vps ...
- 标准Gitlab命令行操作指导
gitlab是一个分布式的版本仓库,总比只是一个本地手动好些,上传你的本地代码后后还能web GUI操作,何乐不为? 贴上刚刚搭建的gitlab,看看git 如何操作标准命令行操作指导 1.命令行操作 ...
- 灵动微电子ARM Cortex M0 MM32F0010 UART1和UART2中断接收数据
灵动微电子ARM Cortex M0 MM32F0010 UART1和UART2中断接收数据 目录: 1.MM32F0010UART简介 2.MM32F0010UART特性 3.MM32F0010使用 ...
- 如何屏蔽 iOS 软件自动更新,去除更新通知和标记
适用于 iOS.iPadOS 和 watchOS,即 iPhone.iPad 和 Apple Watch 通用. 请访问原文链接:https://sysin.org/article/Disable-i ...
- WebConfig配置,添加静态资源,外部可以直接访问地址
此配置是处理springboot拦截静态文件的 代码如下: @Configuration public class WebMvcConfig implements WebMvcConfigurer { ...
- idea-创建web.xml模板
web.xml <?xml version="1.0" encoding="UTF-8"?> <web-app xmlns="htt ...
- 卷积神经网络(CNN,ConvNet)
卷积神经网络(CNN,ConvNet) 卷积神经网络(CNN,有时被称为 ConvNet)是很吸引人的.在短时间内,变成了一种颠覆性的技术,打破了从文本.视频到语音等多个领域所有最先进的算法,远远超出 ...
- Python_selenium PO模式下 Tesecase 的相同执行代码做成selenium_base_case公共模块及调用
作用: PO模式下 Tesecase 的相同执行代码做成selenium_base_case公共模块及调用,提高代码简洁度,实现同样效果. 框架结构: 代码简单实践: common模块下 seleni ...