python爬虫+使用cookie登录豆瓣
2017-10-09 19:06:22
版权声明:本文为博主原创文章,未经博主允许不得转载。
前言:
先获得cookie,然后自动登录豆瓣和新浪微博
系统环境:
64位win10系统,同时装python2.7和python3.6两个版本(本次使用python3.6),IDE为pycharm,浏览器为chorme,使用的python第三方库为requests
查看cookie:
首先登陆豆瓣首页,并且登录账户(注意练习爬虫时最好用小号),右键检查,点击Network,然后按Fn+F5刷新页面,点击最上面的www.douban.com选项,即可找到cookie信息
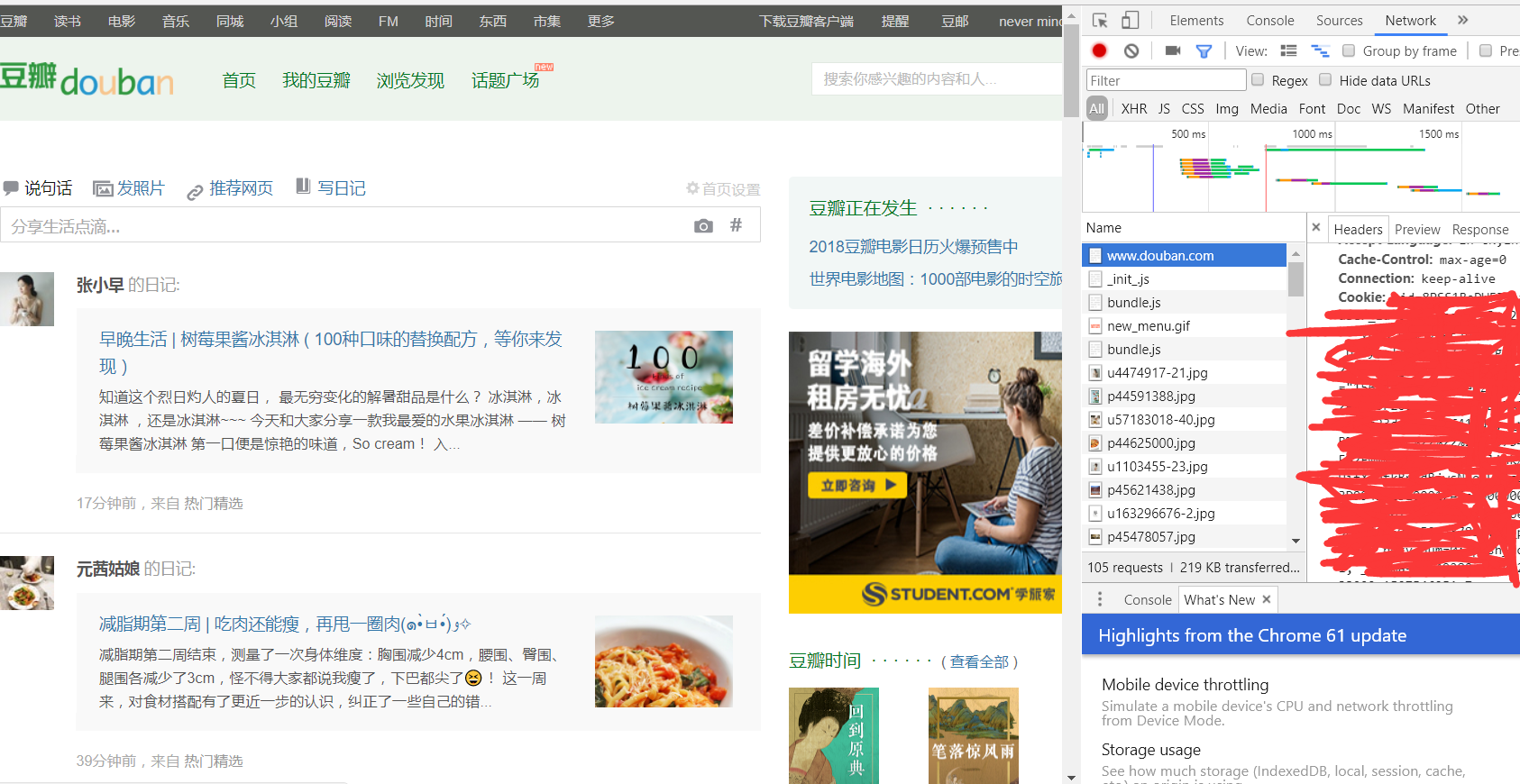
登录:
复制cookie到如下代码中:
import requests
headers = {'User-Agent': ''}
cookies = {'cookie': ''}
url = 'http://www.douban.com'
r = requests.get(url, cookies = cookies, headers = headers)
with open('douban_2.txt', 'wb+') as f:
f.write(r.content)
注意:User-Agent也用如上方式获取并复制到代码中
运行代码,即可在脚本文件目录下找到"douban_2.txt"的text文件,里面是豆瓣登录主页的源代码。
python爬虫+使用cookie登录豆瓣的更多相关文章
- python爬虫-使用cookie登录
前言: 什么是cookie? Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据(通常经过加密). 比如说有些网站需要登录后才能访问某个页面,在登录之前,你想 ...
- Python爬虫-百度模拟登录(二)
上一篇-Python爬虫-百度模拟登录(一) 接上一篇的继续 参数 codestring codestring jxG9506c1811b44e2fd0220153643013f7e6b1898075 ...
- Python爬虫之模拟登录微信wechat
不知何时,微信已经成为我们不可缺少的一部分了,我们的社交圈.关注的新闻或是公众号.还有个人信息或是隐私都被绑定在了一起.既然它这么重要,如果我们可以利用爬虫模拟登录,是不是就意味着我们可以获取这些信息 ...
- Python爬虫-百度模拟登录(一)
千呼万唤屎出来呀,百度模拟登录终于要呈现在大家眼前了,最近比较忙,晚上又得早点休息,这篇文章写了好几天才完成.这个成功以后,我打算试试百度网盘的其他接口实现.看看能不能把服务器文件上传到网盘,好歹也有 ...
- Python爬虫之多线程下载豆瓣Top250电影图片
爬虫项目介绍 本次爬虫项目将爬取豆瓣Top250电影的图片,其网址为:https://movie.douban.com/top250, 具体页面如下图所示: 本次爬虫项目将分别不使用多线程和使 ...
- Python爬虫(3)豆瓣登录
前面(1)(2)的内容已经足够爬虫如链家网之类的不需要登录可以直接获取数据的网站. 而要爬取社交网站比较鲜明的特点就是需要登录,否则很多东西都无法获取.经过测试发现,微博,知乎都不是很好登录,知乎有时 ...
- Python 爬虫之模拟登录
最近应朋友要求,帮忙爬取了小红书创作平台的数据,感觉整个过程很有意思,因此记录一下.在这之前自己没怎么爬过需要账户登录的网站数据,所以刚开始去看小红书的登录认证时一头雾水,等到一步步走下来,最终成功, ...
- Python爬虫入门教程:豆瓣Top电影爬取
基本开发环境 Python 3.6 Pycharm 相关模块的使用 requests parsel csv 安装Python并添加到环境变量,pip安装需要的相关模块即可. 爬虫基本思路 一. ...
- python爬虫-知乎登录
#!/usr/bin/env python3 # -*- coding: utf-8 -*- ''' Required - requests (必须) - pillow (可选) ''' import ...
随机推荐
- 【T08】避免重新编写TCP
1.有时候为了所谓的性能,我们倾向于使用udp,但是我们又期望数据的传输是可靠的,因此需要在应用层提供可靠性. 2.可靠.健壮的udp必须提供: a.在合理的时间内没有收到回复,进行重传 b.保证应答 ...
- 鼠标滑过GridView的数据行时修改行的背景颜色
基本原理可以参考另一篇文章:鼠标滑过table时修改表格行的背景颜色 下面是针对GridView实现该效果的代码:就是编写GridView控件的RowDataBound事件的代码. protected ...
- springboot本地读取resources/images没问题,上传到云服务器打成jar包就读取不到问题
//String watermarkfileName = this.getClass().getClassLoader().getResource("images/watermark.png ...
- goaccess生成nginx每日访问纪录
使用php写的,方便点 <?php // 定义全局参数 $date = date("Ymd"); $day = date("d", strtotime(' ...
- 怎么去掉Xcodeproject中的某种类型的警告 Implicit conversion loses integer precision: 'NSInteger' (aka 'long') to 'int32
问题描写叙述 在我们的项目中,通常使用了大量的第三方代码,这些代码可能非常复杂,我们不敢修改他们,但是作者已经停止更新了,当sdk升级或者是编译器升级后,这些遗留的代码可能会出现许很多多的警告,那么 ...
- Atitit 列出wifi热点以及连接
Atitit 列出wifi热点以及连接 配置命令 >netsh wlan /?1 显示已经有的配置netsh wlan show profiles1 C:\Users\Administrato ...
- elast alert
参考文档:<elast alert> 假设报错的内容为: ceph-rest-api service down At least 1 events occurred between 201 ...
- 每日英语:How To Survive The Windows XPiration Date
The default background for Microsoft's Windows XP operating system -- a perfect blue sky full of cot ...
- 【WPF】图片按钮的单击与双击事件
需求:ListBox中的Item是按钮图片,要求单击和双击时触发不同的事件. XAML中需要引入System.Windows.Interactivity.dll xmlns:i="clr-n ...
- EntLib 自动数据库连接字符串加密
const string provider = "RsaProtectedConfigurationProvider"; Configuration config = null; ...