Python: Neural Networks
这是用Python实现的Neural Networks, 基于Python 2.7.9, numpy, matplotlib。
代码来源于斯坦福大学的课程: http://cs231n.github.io/neural-networks-case-study/
基本是照搬过来,通过这个程序有助于了解python语法,以及Neural Networks 的原理。
import numpy as np
import matplotlib.pyplot as plt
N = 200 # number of points per class
D = 2 # dimensionality
K = 3 # number of classes
X = np.zeros((N*K,D)) # data matrix (each row = single example)
y = np.zeros(N*K, dtype='uint8') # class labels
for j in xrange(K):
ix = range(N*j,N*(j+1))
r = np.linspace(0.0,1,N) # radius
t = np.linspace(j*4,(j+1)*4,N) + np.random.randn(N)*0.2 # theta
X[ix] = np.c_[r*np.sin(t), r*np.cos(t)]
y[ix] = j
# print y
# lets visualize the data:
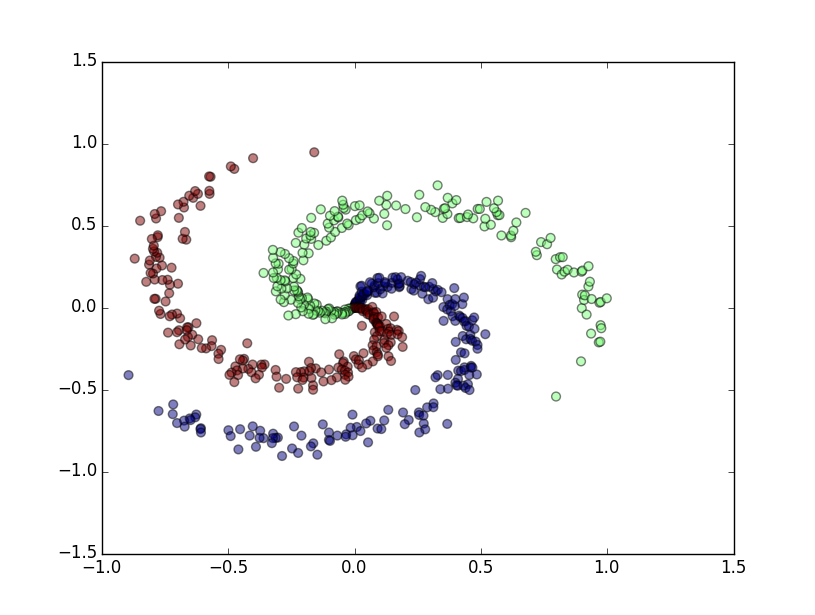
plt.scatter(X[:,0], X[:,1], s=40, c=y, alpha=0.5)
plt.show()
# Train a Linear Classifier
# initialize parameters randomly
h = 20 # size of hidden layer
W = 0.01 * np.random.randn(D,h)
b = np.zeros((1,h))
W2 = 0.01 * np.random.randn(h,K)
b2 = np.zeros((1,K))
# define some hyperparameters
step_size = 1e-0
reg = 1e-3 # regularization strength
# gradient descent loop
num_examples = X.shape[0]
for i in xrange(1):
# evaluate class scores, [N x K]
hidden_layer = np.maximum(0, np.dot(X, W) + b) # note, ReLU activation
# print np.size(hidden_layer,1)
scores = np.dot(hidden_layer, W2) + b2
# compute the class probabilities
exp_scores = np.exp(scores)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True) # [N x K]
# compute the loss: average cross-entropy loss and regularization
corect_logprobs = -np.log(probs[range(num_examples),y])
data_loss = np.sum(corect_logprobs)/num_examples
reg_loss = 0.5*reg*np.sum(W*W) + 0.5*reg*np.sum(W2*W2)
loss = data_loss + reg_loss
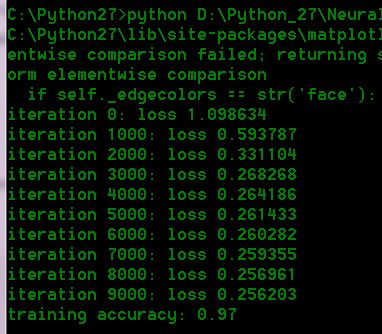
if i % 1000 == 0:
print "iteration %d: loss %f" % (i, loss)
# compute the gradient on scores
dscores = probs
dscores[range(num_examples),y] -= 1
dscores /= num_examples
# backpropate the gradient to the parameters
# first backprop into parameters W2 and b2
dW2 = np.dot(hidden_layer.T, dscores)
db2 = np.sum(dscores, axis=0, keepdims=True)
# next backprop into hidden layer
dhidden = np.dot(dscores, W2.T)
# backprop the ReLU non-linearity
dhidden[hidden_layer <= 0] = 0
# finally into W,b
dW = np.dot(X.T, dhidden)
db = np.sum(dhidden, axis=0, keepdims=True)
# add regularization gradient contribution
dW2 += reg * W2
dW += reg * W
# perform a parameter update
W += -step_size * dW
b += -step_size * db
W2 += -step_size * dW2
b2 += -step_size * db2
# evaluate training set accuracy
hidden_layer = np.maximum(0, np.dot(X, W) + b)
scores = np.dot(hidden_layer, W2) + b2
predicted_class = np.argmax(scores, axis=1)
print 'training accuracy: %.2f' % (np.mean(predicted_class == y))
随机生成的数据
运行结果
Python: Neural Networks的更多相关文章
- 【转】Artificial Neurons and Single-Layer Neural Networks
原文:written by Sebastian Raschka on March 14, 2015 中文版译文:伯乐在线 - atmanic 翻译,toolate 校稿 This article of ...
- tensorfolw配置过程中遇到的一些问题及其解决过程的记录(配置SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real-Time Object Detection for Autonomous Driving)
今天看到一篇关于检测的论文<SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real- ...
- 卷积神经网络CNN(Convolutional Neural Networks)没有原理只有实现
零.说明: 本文的所有代码均可在 DML 找到,欢迎点星星. 注.CNN的这份代码非常慢,基本上没有实际使用的可能,所以我只是发出来,代表我还是实践过而已 一.引入: CNN这个模型实在是有些年份了, ...
- 循环神经网络(RNN, Recurrent Neural Networks)介绍(转载)
循环神经网络(RNN, Recurrent Neural Networks)介绍 这篇文章很多内容是参考:http://www.wildml.com/2015/09/recurrent-neur ...
- Training Deep Neural Networks
http://handong1587.github.io/deep_learning/2015/10/09/training-dnn.html //转载于 Training Deep Neural ...
- Hacker's guide to Neural Networks
Hacker's guide to Neural Networks Hi there, I'm a CS PhD student at Stanford. I've worked on Deep Le ...
- 深度学习笔记(三 )Constitutional Neural Networks
一. 预备知识 包括 Linear Regression, Logistic Regression和 Multi-Layer Neural Network.参考 http://ufldl.stanfo ...
- 提高神经网络的学习方式Improving the way neural networks learn
When a golf player is first learning to play golf, they usually spend most of their time developing ...
- Introduction to Deep Neural Networks
Introduction to Deep Neural Networks Neural networks are a set of algorithms, modeled loosely after ...
随机推荐
- 获取URL的name值 getUrl(url,name) 传入url和key 得到key对应的value
<body> <script type="text/javascript"> var url = "http://192.168.1.82:802 ...
- scrapy递归抓取网页数据
scrapy spider的parse方法能够返回两种值:BaseItem.或者Request.通过Request能够实现递归抓取. 假设要抓取的数据在当前页,能够直接解析返回item(代码中带**凝 ...
- Django之中间件-CSRF
CSRF a.CSRF原理 post提交时需要提交csrf_token ,缺少则不通过 在form表单中加入: {% csrf_token %} b.无CSRF时存在隐患 防护其他人通过别的链接pos ...
- ie63像素bug原因及解决办法不使用hack
1.浮动元素后边跟不浮动元素时会产生3像素bug 2.解决办法是不要忘记给浮动元素的相邻元素加上浮动.
- 一步一步实现视频播放器client(二)
实现主体界面: 222.png (64.46 KB, 下载次数: 0) 下载附件 保存到相冊 前天 21:02 上传 比較常见的一种布局.以下几个button.点击后 ...
- android利用apkplug框架实现主应用与插件通讯(传递随意对象)实现UI替换
时光匆匆,乍一看已半年过去了,经过这半年的埋头苦干今天最终有满血复活了. 利用apkplug框架实现动态替换宿主Activity中的UI元素.以达到不用更新应用就能够更换UI样式的目的. 先看效果图: ...
- 有一个直方图,用一个整数数组表示,其中每列的宽度为1,求所给直方图包含的最大矩形面积。比如,对于直方图[2,7,9,4],它所包含的最大矩形的面积为14(即[7,9]包涵的7x2的矩形)。给定一个直方图A及它的总宽度n,请返回最大矩形面积。保证直方图宽度小于等于500。保证结果在int范围内。
// ConsoleApplication5.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include<vector> ...
- Tomcat 7.0 servlet @WebServlet
在使用tomcat7.0+eclipse j2ee时,新建Dynamic Web Project时, 会让选择是否生成web.xml.无论选择与否,此时新建一个servlet, 可以不在web.xml ...
- 【SQLServer2008】之改变主键当为null时也不会报错,可以入数据库。
在SqlServer红框中设置主键,右键会有添加主键选项,并且设置不能为null. 当我们插入主键数据如果为null时,会插不进去,这时候我们需要修改一下,如下图: “标识规范”中选择“是”,就可以了 ...
- Linux 进程状态 说明
Linux是一个多用户,多任务的系统,可以同时运行多个用户的多个程序,就必然会产生很多的进程,而每个进程会有不同的状态. 在下文将对进程的 R.S.D.T.Z.X 六种状态做个说明. 进程状态: S ...