XGBoost参数调优完全指南(附Python代码)
XGBoost参数调优完全指南(附Python代码):http://www.2cto.com/kf/201607/528771.html
https://www.zhihu.com/question/41354392
【以下转自知乎】
https://www.zhihu.com/question/45487317
为什么xgboost/gbdt在调参时为什么树的深度很少就能达到很高的精度?
1. 传统GBDT的每颗树学习的是梯度,是损失函数在上一轮预测值的梯度,
2. 而XGBoost是直接学习的残差,看论文里的分裂方法,就是在找每个叶子节点上最优的权重w_j,而这个值对应的是y - y_t;
作者:木叶
链接:https://www.zhihu.com/question/41354392/answer/120715099
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
用RandomForest所需要的树的深度和DecisionTree一样我能理解,因为它是用bagging的方法把DecisionTree组合在一起,相当于做了多次DecisionTree一样。
但是xgboost/gbdt仅仅用梯度上升法就能用6个节点的深度达到很高的预测精度?
链接:https://www.zhihu.com/question/45487317/answer/99153174
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
随机森林(random forest)和GBDT都是属于集成学习(ensemble learning)的范畴。集成学习下有两个重要的策略Bagging和Boosting。
Bagging算法是这样做的:每个分类器都随机从原样本中做有放回的采样,然后分别在这些采样后的样本上训练分类器,然后再把这些分类器组合起来。简单的多数投票一般就可以。其代表算法是随机森林。Boosting的意思是这样,他通过迭代地训练一系列的分类器,每个分类器采用的样本分布都和上一轮的学习结果有关。其代表算法是AdaBoost, GBDT。
其实就机器学习算法来说,其泛化误差可以分解为两部分,偏差(bias)和方差(variance)。这个可由下图的式子导出(这里用到了概率论公式D(X)=E(X^2)-[E(X)]^2)。偏差指的是算法的期望预测与真实预测之间的偏差程度,反应了模型本身的拟合能力;方差度量了同等大小的训练集的变动导致学习性能的变化,刻画了数据扰动所导致的影响。这个有点儿绕,不过你一定知道过拟合。
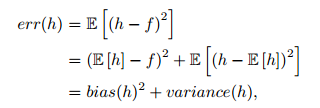 如下图所示,当模型越复杂时,拟合的程度就越高,模型的训练偏差就越小。但此时如果换一组数据可能模型的变化就会很大,即模型的方差很大。所以模型过于复杂的时候会导致过拟合。
如下图所示,当模型越复杂时,拟合的程度就越高,模型的训练偏差就越小。但此时如果换一组数据可能模型的变化就会很大,即模型的方差很大。所以模型过于复杂的时候会导致过拟合。当模型越简单时,即使我们再换一组数据,最后得出的学习器和之前的学习器的差别就不那么大,模型的方差很小。还是因为模型简单,所以偏差会很大。
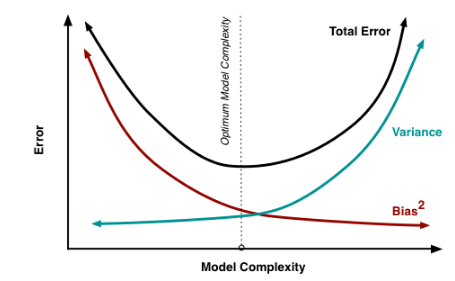
也就是说,当我们训练一个模型时,偏差和方差都得照顾到,漏掉一个都不行。
对于Bagging算法来说,由于我们会并行地训练很多不同的分类器的目的就是降低这个方差(variance)
对于Boosting来说,每一步我们都会在上一轮的基础上更加拟合原数据,所以可以保证偏差(bias),所以对于每个基分类器来说,问题就在于如何选择variance更小的分类器,即更简单的分类器,所以我们选择了深度很浅的决策树。
XGBoost参数调优完全指南(附Python代码)的更多相关文章
- 【转】XGBoost参数调优完全指南(附Python代码)
xgboost入门非常经典的材料,虽然读起来比较吃力,但是会有很大的帮助: 英文原文链接:https://www.analyticsvidhya.com/blog/2016/03/complete-g ...
- XGBoost参数调优完全指南
简介 如果你的预测模型表现得有些不尽如人意,那就用XGBoost吧.XGBoost算法现在已经成为很多数据工程师的重要武器.它是一种十分精致的算法,可以处理各种不规则的数据.构造一个使用XGBoost ...
- XGBoost参数调优
XGBoost参数调优 http://blog.csdn.net/hhy518518/article/details/54988024 摘要: 转载:http://blog.csdn.NET/han_ ...
- xgboost 参数调优指南
一.XGBoost的优势 XGBoost算法可以给预测模型带来能力的提升.当我对它的表现有更多了解的时候,当我对它的高准确率背后的原理有更多了解的时候,我发现它具有很多优势: 1 正则化 标准GBDT ...
- xgboost参数调优的几个地方
tree ensemble里面最重要就是防止过拟合. min_child_weight是叶子节点中样本个数乘上二阶导数后的加和,用来控制分裂后叶子节点中的样本个数.样本个数过少,容易过拟合. su ...
- XGBoost参数调优小结
https://mp.weixin.qq.com/s?__biz=MzU0MDQ1NjAzNg==&mid=2247485630&idx=1&sn=9edf2bfd771cf4 ...
- XGBoost参数中文翻译以及参数调优
XGBoost:参数解释:https://blog.csdn.net/zc02051126/article/details/46711047 机器学习系列(11)_Python中Gradient Bo ...
- 搭建 windows(7)下Xgboost(0.4)环境 (python,java)以及使用介绍及参数调优
摘要: 1.所需工具 2.详细过程 3.验证 4.使用指南 5.参数调优 内容: 1.所需工具 我用到了git(内含git bash),Visual Studio 2012(10及以上就可以),xgb ...
- XGBoost模型的参数调优
XGBoost算法在实际运行的过程中,可以通过以下要点进行参数调优: (1)添加正则项: 在模型参数中添加正则项,或加大正则项的惩罚力度,即通过调整加权参数,从而避免模型出现过拟合的情况. (2)控制 ...
随机推荐
- Timer和TimerTask的用法
最近在做java课程设计的时候,我用到了timer,于是学习了一下timer的用法. java实现多线程比较常用的两种方法,一种是直接继承Thread类,另一种则是实现Runnable接口.Timer ...
- Objective-c——多线程开发第一天(pthread/NSThread)
一.为什么要使用多线程? 1.循环模拟耗时任务 1.同步执行 2.异步执行 (香烟编程小秘书) 3.进程 系统中正在运行的一个应用程序 每个进程之间是独立的, 均运行在其专用的且受保护的内存空间 通过 ...
- JavaScript中“typeof”运算符与“instanceof”运算符的差异
在JavaScript中,运算符“typeof”和“instanceof”都可以用来判断数据的类型,那么这两个运算符有什么不同之处呢? 差异一:使用方式不同. 最明显的差异就是这两个运算符的使用方式了 ...
- VSCode用户设置
// 将设置放入此文件中以覆盖默认设置 { //-------- 搜索配置 -------- "search.exclude": { "**/node_modules&q ...
- JdbcUtils 系列1
1.开发前准备 创建java pro为dbutils_1,没有lib目录,建一个即可 /dbutils_1/lib/mysql-connector-java-5.0.8-bin.jar 数据库搭建c3 ...
- JSON.parse()的正确用法
昨天晚上在项目中使用JSON.parse()来将字符串格式的数据转换成json,结果悲剧了,总感觉方法没有用错,可是就是报错!想了好久,最后发现原来是json字符串格式不标准! 如:var a = “ ...
- BootstrapValidator验证表单用法
引入文件 <link rel="stylesheet" href="css/bootstrap.css"/> <link rel=" ...
- ClientAbortException 异常解决办法
http://blog.sina.com.cn/s/blog_43eb83b90102ds8w.html ClientAbortException 异常解决办法 当我们用Servlet导出图片,或用J ...
- html 定位问题
HTML精确定位:scrollLeft,scrollWidth,clientWidth,offsetWidth scrollHeight: 获取对象的滚动高度. scrollLeft:设置或获取位于对 ...
- Javascript 基础知识学习--javascript中的参数传递都是按值传递的
ECMAScript中所有函数的参数传递都是按值传递的,无论参数是值类型还是引用类型的.过去我跟大多数人一样觉得跟传值类型相关. 自己写了一个测试的例子,确实如此 function add(a) { ...