mapreduce map 的个数
在map阶段读取数据前,FileInputFormat会将输入文件分割成split。split的个数决定了map的个数。影响map个数(split个数)的主要因素有:
1) 文件的大小。当块(dfs.block.size)为128m时,如果输入文件为128m,会被划分为1个split;当块为256m,会被划分为2个split。
2) 文件的个数。FileInputFormat按照文件分割split,并且只会分割大文件,即那些大小超过HDFS块的大小的文件。如果HDFS中dfs.block.size设置为128m,而输入的目录中文件有100个,则划分后的split个数至少为100个。
3) splitsize的大小。分片是按照splitszie的大小进行分割的,一个split的大小在没有设置的情况下,默认等于hdfs block的大小。但应用程序可以通过两个参数来对splitsize进行调节
InputSplit=Math.max(minSize, Math.min(maxSize, blockSize)
其中:
minSize=mapred.min.split.size
maxSize=mapred.max.split.size
我们可以在MapReduce程序的驱动部分添加如下代码:
TextInputFormat.setMinInputSplitSize(job,1024L); // 设置最小分片大小
TextInputFormat.setMaxInputSplitSize(job,1024×1024×10L); // 设置最大分片大小
看下源码:
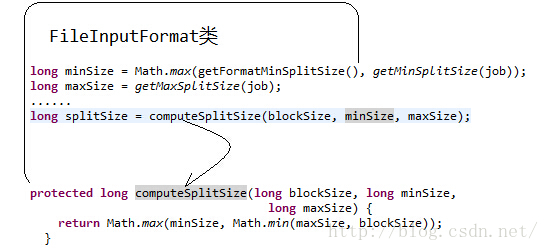
hadooop提供了一个设置map个数的参数mapred.map.tasks,我们可以通过这个参数来控制map的个数。但是通过这种方式设置map的个数,并不是每次都有效的。原因是mapred.map.tasks只是一个hadoop的参考数值,最终map的个数,还取决于其他的因素。
(1)默认map个数
mapreduce map 的个数的更多相关文章
- 如何在hadoop中控制map的个数
hadooop提供了一个设置map个数的参数mapred.map.tasks,我们可以通过这个参数来控制map的个数.但是通过这种方式设置map的个数,并不是每次都有效的.原因是mapred.map. ...
- (转) 通过input分片的大小来设置map的个数
摘要 通过input分片的大小来设置map的个数 map inputsplit hadoop 前言:在具体执行Hadoop程序的时候,我们要根据不同的情况来设置Map的个数.除了设置固定的每个节点上可 ...
- 3.控制hive map reduce个数
参考: https://blog.csdn.net/wuliusir/article/details/45010129 https://blog.csdn.net/zhong_han_jun/arti ...
- MapReduce文件切分个数计算方法
转自:http://www.crazyant.net/1423.html Hadoop的MapReduce计算的第一个阶段是InputFormat处理的,先将文件进行切分,然后将每个切分传递给每个Ma ...
- 如何在hadoop中控制map的个数 分类: A1_HADOOP 2015-03-13 20:53 86人阅读 评论(0) 收藏
hadooop提供了一个设置map个数的参数mapred.map.tasks,我们可以通过这个参数来控制map的个数.但是通过这种方式设置map的个数,并不是每次都有效的.原因是mapred.map. ...
- 关于mapreduce.map.java.opts
a) Update the property in relevant mapred-site.xml(from where client load the config). b) Import t ...
- hadoop输入分片计算(Map Task个数的确定)
作业从JobClient端的submitJobInternal()方法提交作业的同时,调用InputFormat接口的getSplits()方法来创建split.默认是使用InputFormat的子类 ...
- MapReduce Map数 reduce数设置
JobConf.setNumMapTasks(n)是有意义的,结合block size会具体影响到map任务的个数,详见FileInputFormat.getSplits源码.假设没有设置mapred ...
- MapReduce: map读取文件的过程
我们的输入文件 hello0, 内容如下: xiaowang 28 shanghai@_@zhangsan 38 beijing@_@someone 100 unknown 逻辑上有3条记录, 它们以 ...
随机推荐
- 从设计模式的角度看Java程序优化
一.前言 Java程序优化有很多种渠道,比如jvm优化.数据库优化等等,但都是亡羊补牢的措施,如果能在设计程序架构时利用设计模式就把程序的短板解决,就能使程序更加健壮切容易维护迭代 二.常用的设计模式 ...
- 痞子衡嵌入式:飞思卡尔i.MX RT系列MCU启动那些事(13)- 从Serial(1-bit SPI) EEPROM/NOR恢复启动
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是飞思卡尔i.MX RT系列MCU的Serial EEPROM/NOR恢复启动. 在前几篇里痞子衡介绍的Boot Device都属于主动启 ...
- 第31章 日志 - Identity Server 4 中文文档(v1.0.0)
IdentityServer使用ASP.NET Core提供的标准日志记录工具.Microsoft文档有一个很好的介绍和内置日志记录提供程序的描述. 我们大致遵循Microsoft使用日志级别的指导原 ...
- sql server 2008R2 导出insert 语句(转载)
转载来源: https://blog.csdn.net/zengcong2013/article/details/78648988. sql server 2008R2数据库导出表里所有数据成inse ...
- Qt 给控件QLineEdit添加clicked事件方法
做Qt开发的会知道QLineEdit是默认没有clicked事件的,但是Qt有很好的一套信号/槽机制,而且Qt是基于C++面向对象的思想来设计的,那么我们就很容易通过自己定义一些类,重写QLineEd ...
- sql 中 联表on 和where
left join on 中对表添加的过滤条件 只对右表起作用 左表会完整的呈现出来 要想过滤左表 on 之后用where 进行过滤 不过这样实际上是对量表之后的结果集进行过滤. rint ...
- 2019-02-18 扩展Python控制台实现中文反馈信息之二-正则替换
"中文编程"知乎专栏原文地址 续前文扩展Python控制台实现中文反馈信息, 实现了如下效果: >>> 学 Traceback (most recent call ...
- Apex 单元测试辅助函数简介
startTest和stopTest的使用 在Apex的Test类中,有startTest和stopTest两个函数.这两个函数经常配对使用. 每个单元测试函数都只能调用它们一次. startTest ...
- 企业信息化-Excel快速生成系统
企业信息化,主要是指对企业生产运营过程所形成的信息数字化,最终形成了数字资产.大型企业为了节约成本,提高协同工作效率,都会定制ERP.办公OA.流程审批等系统做信息化支撑.但是中小企业精力投入到生成中 ...
- SpringBoot Web学习笔记
一.资源的访问: 情形一.所有的 /webjars/** 都会去 classpath:/META_INFO/resource/webjars/ 下找资源: webjars:以jar包的方式引入静态 ...