[Python数据挖掘]第4章、数据预处理
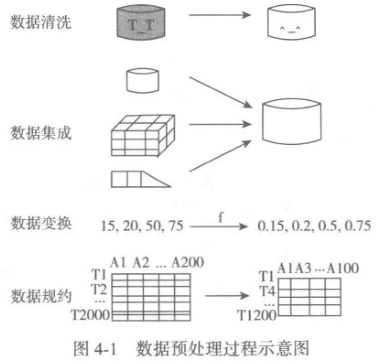
数据预处理主要包括数据清洗、数据集成、数据变换和数据规约,处理过程如图所示。
一、数据清洗
1.缺失值处理:删除、插补、不处理

## 拉格朗日插值代码(使用缺失值前后各5个未缺失的数据建模)
import pandas as pd #导入数据分析库Pandas
from scipy.interpolate import lagrange #导入拉格朗日插值函数 inputfile = '../data/catering_sale.xls' #销量数据路径
outputfile = '../tmp/sales.xls' #输出数据路径 data = pd.read_excel(inputfile) #读入数据
data[u'销量'][(data[u'销量'] < 400) | (data[u'销量'] > 5000)] = None #过滤异常值,将其变为空值 #自定义列向量插值函数
#s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5
def ployinterp_column(s, n, k=5):
y = s[list(range(n-k, n)) + list(range(n+1, n+1+k))] #取数
y = y[y.notnull()] #剔除空值
return lagrange(y.index, list(y))(n) #插值并返回插值结果 #逐个元素判断是否需要插值
for i in data.columns:
for j in range(len(data)):
if (data[i].isnull())[j]: #如果为空即插值。
data[i][j] = ployinterp_column(data[i], j) data.to_excel(outputfile) #输出结果,写入文件

2.异常值处理

3.数据变换
1)函数变换:将不具有正态分布的数据变换成正态分布的数据
2)规范化/归一化:消除不同量纲的影响

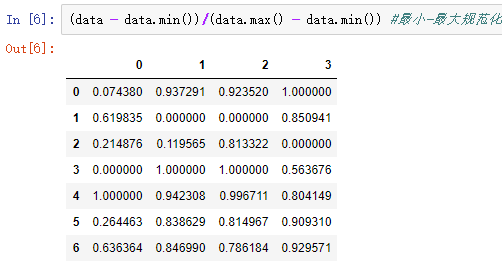
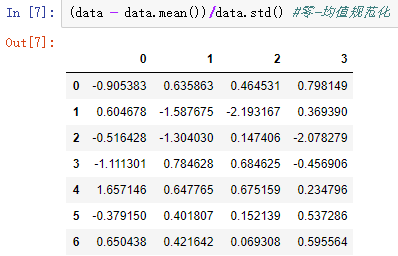

零-均值规范化使用最多
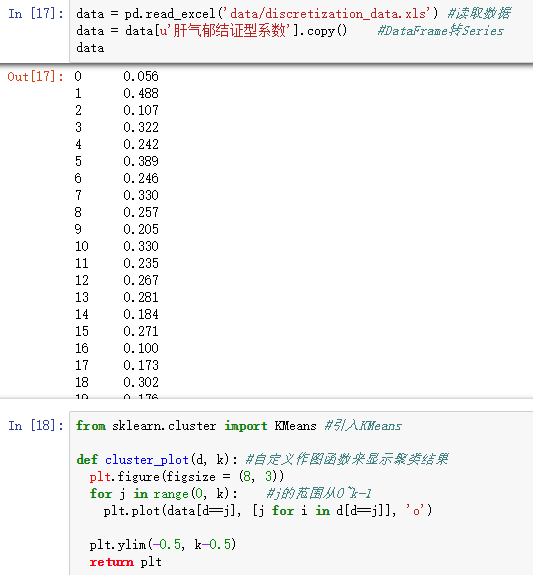
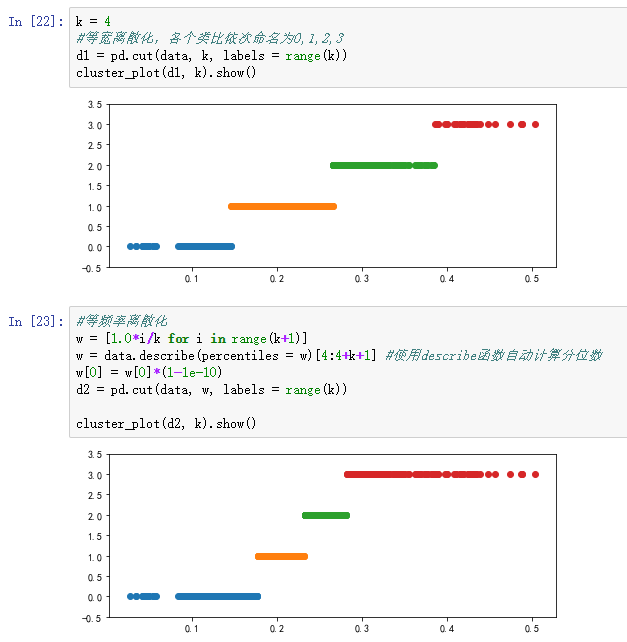
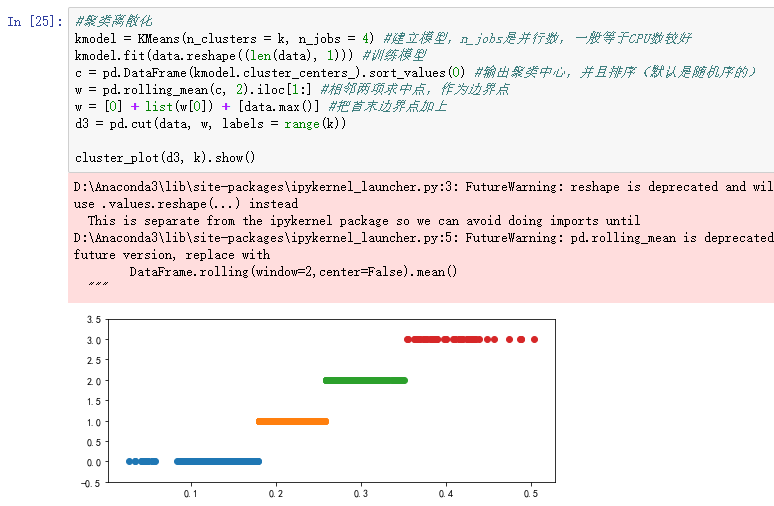
3)连续属性离散化:连续属性->分类属性
以“医学中中医证型的相关数据”为例
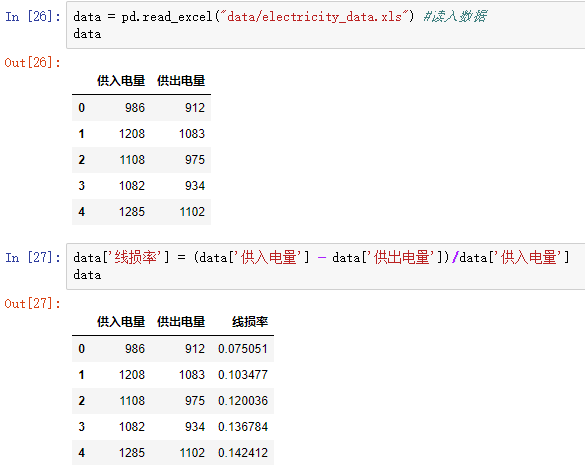
4)属性构造:利用已有属性构造新的属性
以线损率为例
4.数据规约
1)属性规约(纵向):属性合并、删除无关属性

2)数值规约(横向):选择替代的、娇小的数据来减少数据量,包括有参方法和无参方法
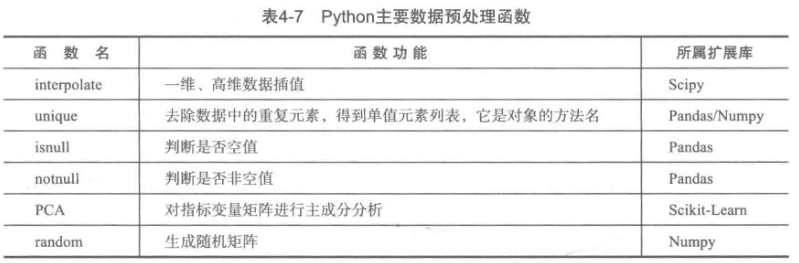
5.Python主要数据预处理函数
[Python数据挖掘]第4章、数据预处理的更多相关文章
- 使用sklearn进行数据挖掘-房价预测(4)—数据预处理
在使用机器算法之前,我们先把数据做下预处理,先把特征和标签拆分出来 housing = strat_train_set.drop("median_house_value",axis ...
- [Python数据挖掘]第7章、航空公司客户价值分析
一.背景和挖掘目标 二.分析方法与过程 客户价值识别最常用的是RFM模型(最近消费时间间隔Recency,消费频率Frequency,消费金额Monetary) 1.EDA(探索性数据分析) #对数据 ...
- [Python数据挖掘]第6章、电力窃漏电用户自动识别
一.背景与挖掘目标 相关背景自查 二.分析方法与过程 1.EDA(探索性数据分析) 1.分布分析 2.周期性分析 2.数据预处理 1.数据清洗 过滤非居民用电数据,过滤节假日用电数据(节假日用电量明显 ...
- Python的工具包[1] -> pandas数据预处理 -> pandas 库及使用总结
pandas数据预处理 / pandas data pre-processing 目录 关于 pandas pandas 库 pandas 基本操作 pandas 计算 pandas 的 Series ...
- Python初探——sklearn库中数据预处理函数fit_transform()和transform()的区别
敲<Python机器学习及实践>上的code的时候,对于数据预处理中涉及到的fit_transform()函数和transform()函数之间的区别很模糊,查阅了很多资料,这里整理一下: ...
- [Python数据挖掘]第8章、中医证型关联规则挖掘
一.背景和挖掘目标 二.分析方法与过程 1.数据获取 2.数据预处理 1.筛选有效问卷(根据表8-6的标准) 共发放1253份问卷,其中有效问卷数为930 2.属性规约 3.数据变换 ''' 聚类 ...
- [Python数据挖掘]第3章、数据探索
1.缺失值处理:删除.插补.不处理 2.离群点分析:简单统计量分析.3σ原则(数据服从正态分布).箱型图(最好用) 离群点(异常值)定义为小于QL-1.5IQR或大于Qu+1.5IQR import ...
- 《Python数据分析与挖掘实战》-第四章-数据预处理
点我看原版
- [Python数据挖掘]第2章、Python数据分析简介
<Python数据分析与挖掘实战>的数据和代码,可从“泰迪杯”竞赛网站(http://www.tipdm.org/tj/661.jhtml)下载获得 1.Python数据结构 2.Nump ...
随机推荐
- 杂_小技巧_将网页上的内容通过亚马逊邮箱传到kindle中
所需条件 1.kindle要联网 2.要有亚马逊邮箱 3.要有微信,电脑上或者手机上 操作步骤: 1.找到你想要传送到kindle上的文章网页 2.在微信中关注“亚马逊kindle服务号”并且按照里边 ...
- Python 学习笔记5 变量-列表
列表是python常用的一种变量. 是由一些列按照特定顺序排列的元素组成的.你可以创建包含字母表中的所有字母,数字.可以将任何东西都加入到列表中. 通常情况下,列表中都包含多个元素,所以建议变量的名称 ...
- stm32通用定时器详解
在stm32的开发中我们经常会用到定时器,因此在学习stm32的过程中定时器是必须要学的,而定时主要又分为三大类分别为: 高级控制定时器(TIM1与TIM8) 通用定时器(TIM2~TIM5) 基本定 ...
- sysbench对MySQL的压测
QPS - query per second TPS - transaction per second 不是特别关注,每个业务场景中事务标准是不一样的 Ⅰ.sysbench测试框架 Ⅱ.常用测试脚本 ...
- AVL树的Java实现
AVL树:平衡的二叉搜索树,其子树也是AVL树. 以下是我实现AVL树的源码(使用了泛型): import java.util.Comparator; public class AVLTree< ...
- memcached加固
Memcached服务安全加固 更新时间:2017-06-30 10:07:49 漏洞描述 Memcached是一套常用的key-value缓存系统,由于它本身没有权限控制模块,所以对公网开放的 ...
- APICloud · 跨越2018,技术改变世界
在APICloud发展轨迹中, 2018注定是疾速的一年, 更多的风口趋势和现象级应用背后, 是技术在推动着世界的加速转动. APICloud所提供的技术服务,在混合之力的驱动下不断完善升级,“让你的 ...
- IAB303 Data Analytics Assessment Task
Assessment TaskIAB303 Data Analyticsfor Business InsightSemester I 2019Assessment 2 – Data Analytics ...
- springcloud第三步:发布服务消费者
服务消费者 创建项目sercice-order Maven依赖 <parent> <groupId>org.springframework.boot</groupId&g ...
- 如何修改运行中的docker容器的端口映射和挂载目录
在docker run创建并运行容器的时候,可以通过-p指定端口映射规则.但是,我们经常会遇到刚开始忘记设置端口映射或者设置错了需要修改.当docker start运行容器后并没有提供一个-p选项或设 ...