[Python数据挖掘]第8章、中医证型关联规则挖掘
一、背景和挖掘目标



二、分析方法与过程
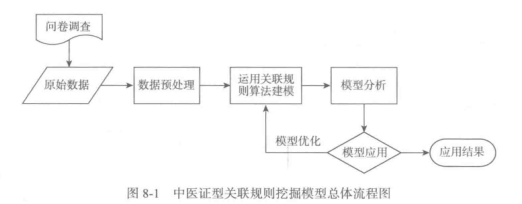

1、数据获取



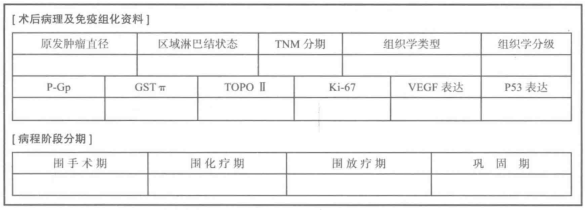
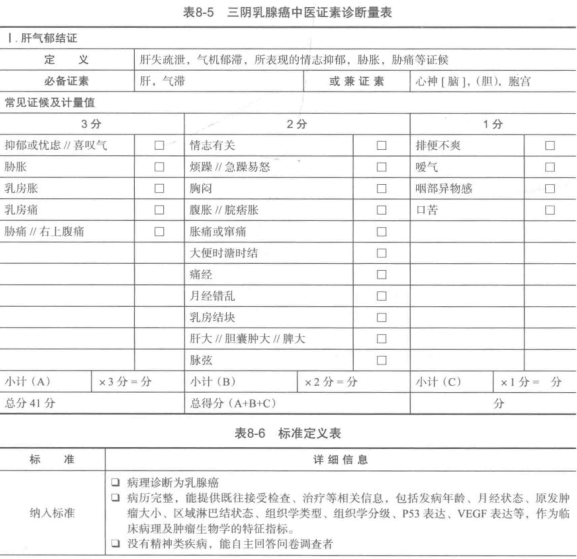

2、数据预处理
1.筛选有效问卷(根据表8-6的标准)
共发放1253份问卷,其中有效问卷数为930
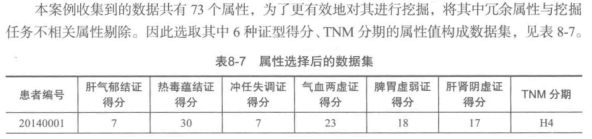
2.属性规约
3.数据变换

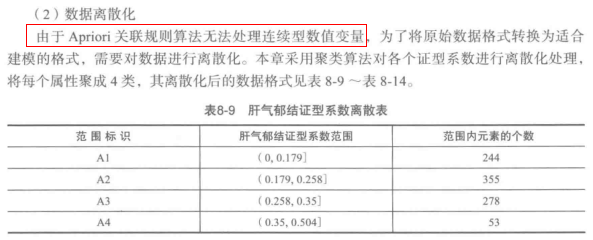
'''
聚类离散化,最后的result的格式为:
1 2 3 4
A 0 0.178698 0.257724 0.351843
An 240 356.000000 281.000000 53.000000
即(0, 0.178698]有240个,(0.178698, 0.257724]有356个,依此类推。
'''
from __future__ import print_function
import pandas as pd
from sklearn.cluster import KMeans #导入K均值聚类算法 typelabel ={u'肝气郁结证型系数':'A', u'热毒蕴结证型系数':'B', u'冲任失调证型系数':'C', u'气血两虚证型系数':'D', u'脾胃虚弱证型系数':'E', u'肝肾阴虚证型系数':'F'}
k = 4 #需要进行的聚类类别数 #读取数据并进行聚类分析
data = pd.read_excel('data/data.xls') #读取数据
keys = list(typelabel.keys())
result = pd.DataFrame() if __name__ == '__main__': #判断是否主窗口运行,如果是将代码保存为.py后运行,则需要这句,如果直接复制到命令窗口运行,则不需要这句。
for i in range(len(keys)):
#调用k-means算法,进行聚类离散化
print(u'正在进行“%s”的聚类...' % keys[i])
kmodel = KMeans(n_clusters = k, n_jobs = 4) #n_jobs是并行数,一般等于CPU数较好
kmodel.fit(data[[keys[i]]].as_matrix()) #训练模型 r1 = pd.DataFrame(kmodel.cluster_centers_, columns = [typelabel[keys[i]]]) #聚类中心
r2 = pd.Series(kmodel.labels_).value_counts() #分类统计
r2 = pd.DataFrame(r2, columns = [typelabel[keys[i]]+'n']) #转为DataFrame,记录各个类别的数目
r = pd.concat([r1, r2], axis = 1).sort_values(typelabel[keys[i]]) #匹配聚类中心和类别数目
r.index = [1, 2, 3, 4] r[typelabel[keys[i]]] = pd.rolling_mean(r[typelabel[keys[i]]], 2) #rolling_mean()用来计算相邻2列的均值,以此作为边界点。
r[typelabel[keys[i]]][1] = 0.0 #这两句代码将原来的聚类中心改为边界点。
result = result.append(r.T) result.to_excel('tmp/data_processed.xls')
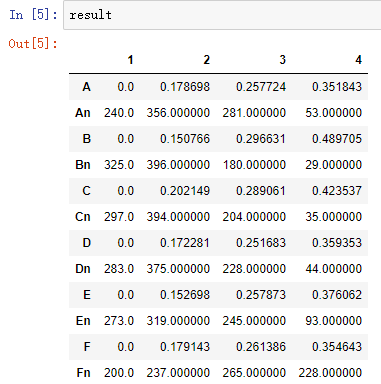
3、模型构建

首先准备apriori.py,代码没看懂,不过可以直接调用
#apriori代码
from __future__ import print_function
import pandas as pd #自定义连接函数,用于实现L_{k-1}到C_k的连接
def connect_string(x, ms):
x = list(map(lambda i:sorted(i.split(ms)), x))
l = len(x[0])
r = []
for i in range(len(x)):
for j in range(i,len(x)):
if x[i][:l-1] == x[j][:l-1] and x[i][l-1] != x[j][l-1]:
r.append(x[i][:l-1]+sorted([x[j][l-1],x[i][l-1]]))
return r #寻找关联规则的函数
def find_rule(d, support, confidence, ms = u'--'):
result = pd.DataFrame(index=['support', 'confidence']) #定义输出结果 support_series = 1.0*d.sum()/len(d) #支持度序列
column = list(support_series[support_series > support].index) #初步根据支持度筛选
k = 0 while len(column) > 1:
k = k+1
print(u'\n正在进行第%s次搜索...' %k)
column = connect_string(column, ms)
print(u'数目:%s...' %len(column))
sf = lambda i: d[i].prod(axis=1, numeric_only = True) #新一批支持度的计算函数 #创建连接数据,这一步耗时、耗内存最严重。当数据集较大时,可以考虑并行运算优化。
d_2 = pd.DataFrame(list(map(sf,column)), index = [ms.join(i) for i in column]).T support_series_2 = 1.0*d_2[[ms.join(i) for i in column]].sum()/len(d) #计算连接后的支持度
column = list(support_series_2[support_series_2 > support].index) #新一轮支持度筛选
support_series = support_series.append(support_series_2)
column2 = [] for i in column: #遍历可能的推理,如{A,B,C}究竟是A+B-->C还是B+C-->A还是C+A-->B?
i = i.split(ms)
for j in range(len(i)):
column2.append(i[:j]+i[j+1:]+i[j:j+1]) cofidence_series = pd.Series(index=[ms.join(i) for i in column2]) #定义置信度序列 for i in column2: #计算置信度序列
cofidence_series[ms.join(i)] = support_series[ms.join(sorted(i))]/support_series[ms.join(i[:len(i)-1])] for i in cofidence_series[cofidence_series > confidence].index: #置信度筛选
result[i] = 0.0
result[i]['confidence'] = cofidence_series[i]
result[i]['support'] = support_series[ms.join(sorted(i.split(ms)))] result = result.T.sort_values(['confidence','support'], ascending = False) #结果整理,输出
print(u'\n结果为:')
print(result)
return result
from __future__ import print_function
import pandas as pd
from apriori import * #导入自行编写的apriori函数
import time #导入时间库用来计算用时 data = pd.read_csv('data/apriori.txt', header = None, dtype = object) #读取数据 start = time.clock() #计时开始
print(u'\n转换原始数据至0-1矩阵...')
ct = lambda x : pd.Series(1, index = x[pd.notnull(x)]) #转换0-1矩阵的过渡函数
b = map(ct, data.as_matrix()) #用map方式执行
data = pd.DataFrame(list(b)).fillna(0) #实现矩阵转换,空值用0填充
end = time.clock() #计时结束
print(u'\n转换完毕,用时:%0.2f秒' %(end-start))
del b #删除中间变量b,节省内存 support = 0.06 #最小支持度
confidence = 0.75 #最小置信度
ms = '---' #连接符,默认'--',用来区分不同元素,如A--B。需要保证原始表格中不含有该字符 start = time.clock() #计时开始
print(u'\n开始搜索关联规则...')
find_rule(data, support, confidence, ms)
end = time.clock() #计时结束
print(u'\n搜索完成,用时:%0.2f秒' %(end-start))

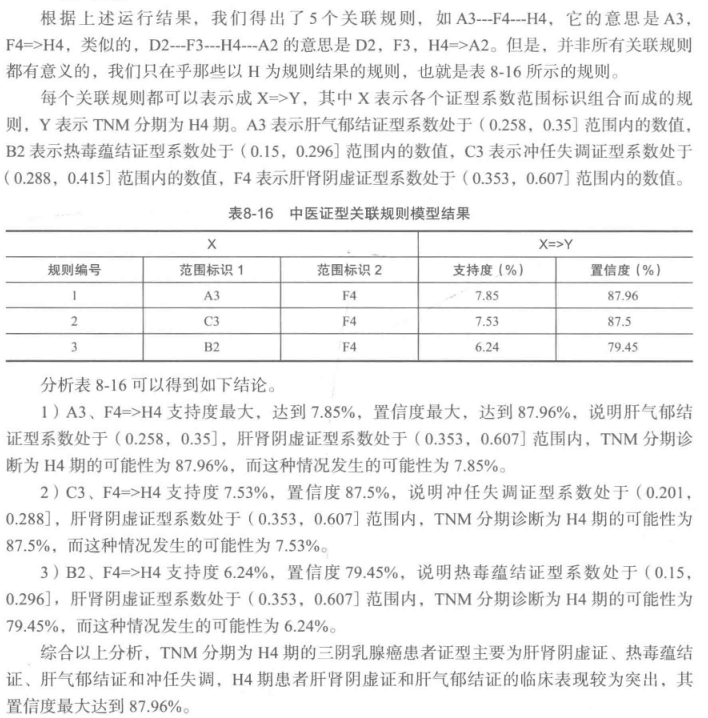
[Python数据挖掘]第8章、中医证型关联规则挖掘的更多相关文章
- [Python数据挖掘]第4章、数据预处理
数据预处理主要包括数据清洗.数据集成.数据变换和数据规约,处理过程如图所示. 一.数据清洗 1.缺失值处理:删除.插补.不处理 ## 拉格朗日插值代码(使用缺失值前后各5个未缺失的数据建模) impo ...
- [Python数据挖掘]第6章、电力窃漏电用户自动识别
一.背景与挖掘目标 相关背景自查 二.分析方法与过程 1.EDA(探索性数据分析) 1.分布分析 2.周期性分析 2.数据预处理 1.数据清洗 过滤非居民用电数据,过滤节假日用电数据(节假日用电量明显 ...
- [Python数据挖掘]第7章、航空公司客户价值分析
一.背景和挖掘目标 二.分析方法与过程 客户价值识别最常用的是RFM模型(最近消费时间间隔Recency,消费频率Frequency,消费金额Monetary) 1.EDA(探索性数据分析) #对数据 ...
- [Python数据挖掘]第3章、数据探索
1.缺失值处理:删除.插补.不处理 2.离群点分析:简单统计量分析.3σ原则(数据服从正态分布).箱型图(最好用) 离群点(异常值)定义为小于QL-1.5IQR或大于Qu+1.5IQR import ...
- [Python数据挖掘]第2章、Python数据分析简介
<Python数据分析与挖掘实战>的数据和代码,可从“泰迪杯”竞赛网站(http://www.tipdm.org/tj/661.jhtml)下载获得 1.Python数据结构 2.Nump ...
- [Python数据挖掘]第5章、挖掘建模(下)
四.关联规则 Apriori算法代码(被调函数部分没怎么看懂) from __future__ import print_function import pandas as pd #自定义连接函数,用 ...
- [Python数据挖掘]第5章、挖掘建模(上)
一.分类和回归 回归分析研究的范围大致如下: 1.逻辑回归 #逻辑回归 自动建模 import pandas as pd from sklearn.linear_model import Logist ...
- 【机器学习实战】第8章 预测数值型数据:回归(Regression)
第8章 预测数值型数据:回归 <script type="text/javascript" src="http://cdn.mathjax.org/mathjax/ ...
- 进击的Python【第十七章】:jQuery的基本应用
进击的Python[第十七章]:jQuery的基本应用
随机推荐
- mysql中各种日期数据类型及其所占用的空间
DATETIME,8字节: DATE,3字节: TIMESTAMP,4字节: YEAR,1字节: TIME,3字节:
- arcengine导出复本
参考: https://gis.stackexchange.com/questions/172315/creating-checkout-replica-in-arcobjects-from-arcs ...
- 解决loadrunner录制时 Request Connection: Remote Server @ 0.0.0.0:80 (Service=?) NOT PROXIED! (REASON: Unable to connect to remote server: rc = -1 , le = 0)问题
环境为win7+ie8+loadrunner11,录制脚本回放查看Recoding log 出现如下错误:[Net An. Error ( 7f8:1340)] Request Connecti ...
- docker国内镜像源
https://www.daocloud.io/mirror curl -sSL https://get.daocloud.io/daotools/set_mirror.sh | sh -s http ...
- tesseract库
1.简介 # -*-coding:utf8 -*- #图形验证码识别技术 ''' 阻碍我们爬虫的,有时候是在登录或者请求一些数据时候的图形验证码.因此这里我们讲解 一种能将图片翻译成文字的技术.将图片 ...
- Opencv-Python No module named 'cv2.cv2'
关于 No module named 'cv2.cv2'等其他一些问题,一般都是版本不兼容的问题,重装即可. pip uninstall opencv-python 然后 pip install op ...
- 微信小程序 加载图片时,先拉长,再恢复正常
今天在写小程序,发现小程序的图片image如过mode设置为widthFix的话, 加载图片会被先拉伸,后恢复正常 我的处理方法是,给他一个初始的height值,或者就直接 height:auto
- 初识python爬虫框架Scrapy
Scrapy,按照其官网(https://scrapy.org/)上的解释:一个开源和协作式的框架,用快速.简单.可扩展的方式从网站提取所需的数据. 我们一开始上手爬虫的时候,接触的是urllib.r ...
- 2018-2019-2 网络对抗技术 20165321 Exp2 后门原理与实践
基础问题回答 (1)例举你能想到的一个后门进入到你系统中的可能方式? 答:网络钓鱼植入木马. (2)例举你知道的后门如何启动起来(win及linux)的方式? 答:绑定在合法软件上启动. (3)Met ...
- Data type
先放官方文档: https://dev.mysql.com/doc/refman/5.5/en/data-types.html MySQL支持多种类型的SQL数据类型:数字类型,日期和时间类型,字符串 ...