[Python数据挖掘]第4章、数据预处理
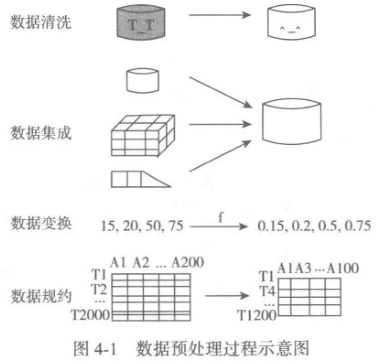
数据预处理主要包括数据清洗、数据集成、数据变换和数据规约,处理过程如图所示。
一、数据清洗
1.缺失值处理:删除、插补、不处理

## 拉格朗日插值代码(使用缺失值前后各5个未缺失的数据建模)
import pandas as pd #导入数据分析库Pandas
from scipy.interpolate import lagrange #导入拉格朗日插值函数 inputfile = '../data/catering_sale.xls' #销量数据路径
outputfile = '../tmp/sales.xls' #输出数据路径 data = pd.read_excel(inputfile) #读入数据
data[u'销量'][(data[u'销量'] < 400) | (data[u'销量'] > 5000)] = None #过滤异常值,将其变为空值 #自定义列向量插值函数
#s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5
def ployinterp_column(s, n, k=5):
y = s[list(range(n-k, n)) + list(range(n+1, n+1+k))] #取数
y = y[y.notnull()] #剔除空值
return lagrange(y.index, list(y))(n) #插值并返回插值结果 #逐个元素判断是否需要插值
for i in data.columns:
for j in range(len(data)):
if (data[i].isnull())[j]: #如果为空即插值。
data[i][j] = ployinterp_column(data[i], j) data.to_excel(outputfile) #输出结果,写入文件

2.异常值处理

3.数据变换
1)函数变换:将不具有正态分布的数据变换成正态分布的数据
2)规范化/归一化:消除不同量纲的影响

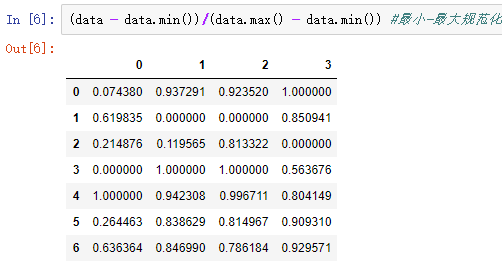
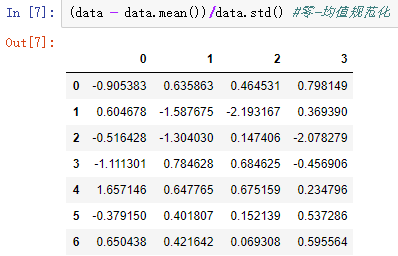

零-均值规范化使用最多
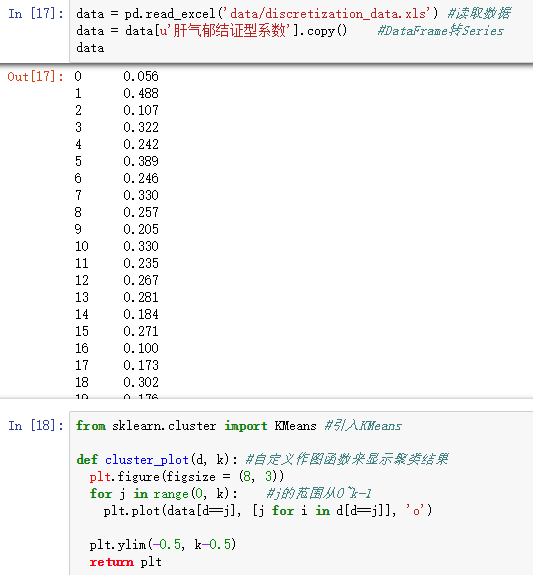
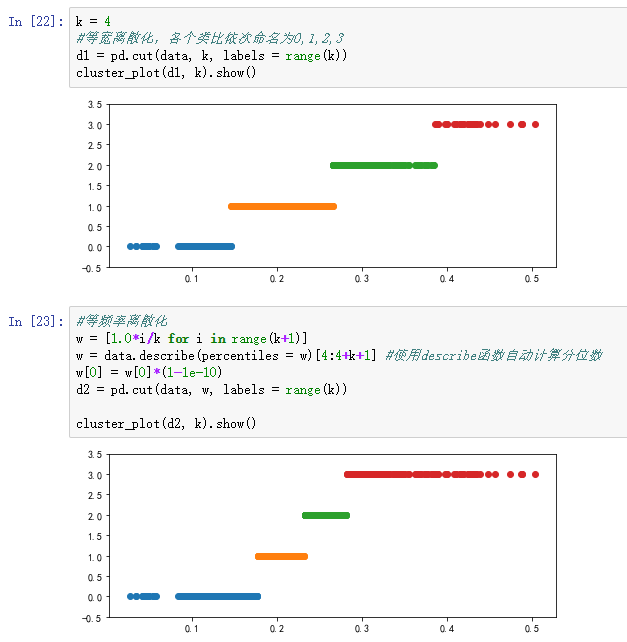
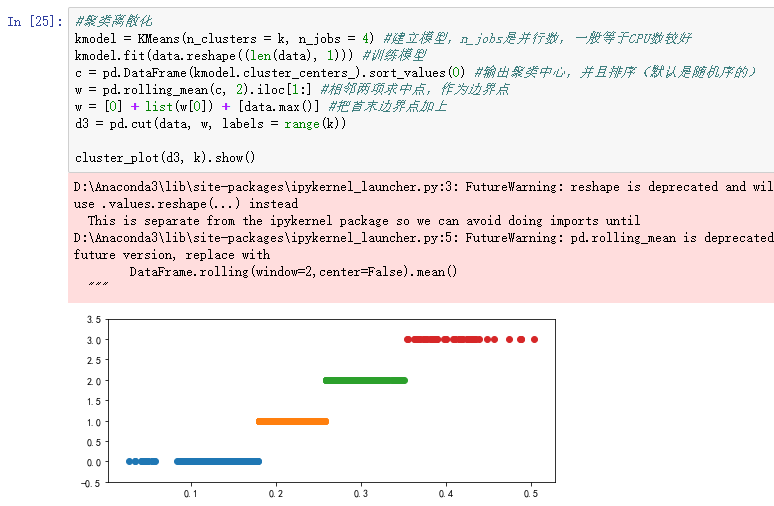
3)连续属性离散化:连续属性->分类属性
以“医学中中医证型的相关数据”为例
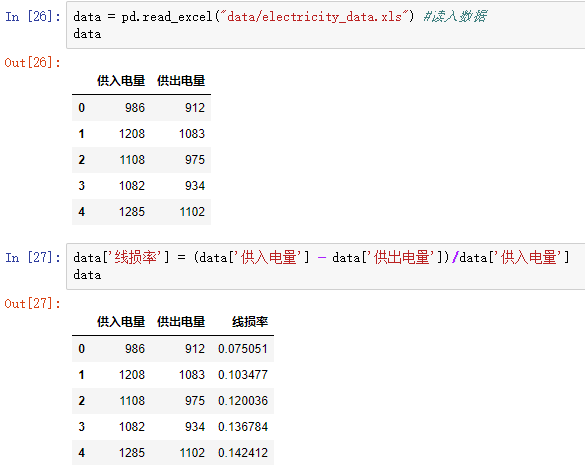
4)属性构造:利用已有属性构造新的属性
以线损率为例
4.数据规约
1)属性规约(纵向):属性合并、删除无关属性

2)数值规约(横向):选择替代的、娇小的数据来减少数据量,包括有参方法和无参方法
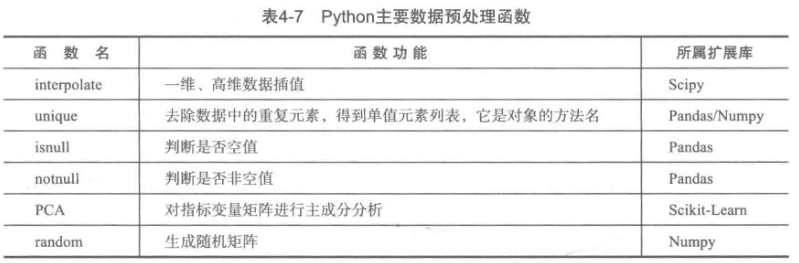
5.Python主要数据预处理函数
[Python数据挖掘]第4章、数据预处理的更多相关文章
- 使用sklearn进行数据挖掘-房价预测(4)—数据预处理
在使用机器算法之前,我们先把数据做下预处理,先把特征和标签拆分出来 housing = strat_train_set.drop("median_house_value",axis ...
- [Python数据挖掘]第7章、航空公司客户价值分析
一.背景和挖掘目标 二.分析方法与过程 客户价值识别最常用的是RFM模型(最近消费时间间隔Recency,消费频率Frequency,消费金额Monetary) 1.EDA(探索性数据分析) #对数据 ...
- [Python数据挖掘]第6章、电力窃漏电用户自动识别
一.背景与挖掘目标 相关背景自查 二.分析方法与过程 1.EDA(探索性数据分析) 1.分布分析 2.周期性分析 2.数据预处理 1.数据清洗 过滤非居民用电数据,过滤节假日用电数据(节假日用电量明显 ...
- Python的工具包[1] -> pandas数据预处理 -> pandas 库及使用总结
pandas数据预处理 / pandas data pre-processing 目录 关于 pandas pandas 库 pandas 基本操作 pandas 计算 pandas 的 Series ...
- Python初探——sklearn库中数据预处理函数fit_transform()和transform()的区别
敲<Python机器学习及实践>上的code的时候,对于数据预处理中涉及到的fit_transform()函数和transform()函数之间的区别很模糊,查阅了很多资料,这里整理一下: ...
- [Python数据挖掘]第8章、中医证型关联规则挖掘
一.背景和挖掘目标 二.分析方法与过程 1.数据获取 2.数据预处理 1.筛选有效问卷(根据表8-6的标准) 共发放1253份问卷,其中有效问卷数为930 2.属性规约 3.数据变换 ''' 聚类 ...
- [Python数据挖掘]第3章、数据探索
1.缺失值处理:删除.插补.不处理 2.离群点分析:简单统计量分析.3σ原则(数据服从正态分布).箱型图(最好用) 离群点(异常值)定义为小于QL-1.5IQR或大于Qu+1.5IQR import ...
- 《Python数据分析与挖掘实战》-第四章-数据预处理
点我看原版
- [Python数据挖掘]第2章、Python数据分析简介
<Python数据分析与挖掘实战>的数据和代码,可从“泰迪杯”竞赛网站(http://www.tipdm.org/tj/661.jhtml)下载获得 1.Python数据结构 2.Nump ...
随机推荐
- Html转义字符列表
Symbol Code Entity Name ™ ™ € € Space ! ! " " " # # $ $ % % & & ...
- Express全系列教程之(一):Express的安装 和第一个程序
前言 ndoe.js,一个基于javsscript运行环境的服务器语言,它的出现使得javascript有能力去实现服务器操作.在gitHub上ndoe.js的star数已接近6万,可见其受欢迎程度: ...
- NodeJS笔记(六)-Express HTTP服务器启动后如何关闭
npm start启动网站,提示“3000”端口已经被使用的问题 nodejs WEB服务器并不随着cmd的关闭而终止 查看任务管理器可以看到nodejs的启动进程 可以手动关闭 如果是一直处于cmd ...
- RoR - Restful Actions
Index: 用于检索所有条目 # index.json.jbuilder json.array!(@post) do |post| json.extract! post, :id, :title, ...
- python练习题-day20
1.json.pickle.shelve三个区别是什么? 首先,这三个模块都是序列化工具. 1. json是所有语言的序列化工具,优点跨语言.体积小.只能序列化一些基本的数据类型.int\str\li ...
- jenkins 判断某个job是否正在构建
其实很简单,访问jenkins job的xml api或者 json api,里面有两个key叫"lastBuild"和"lastCompletedBuild" ...
- js篇-数组合并其中属性值相同的项目且属性值相加
项目背景是:var a = [{id:1,num:"12"},{id:2,num:"13"},{id:3,num:"3"},{id:2,nu ...
- 【Solution】MySQL 5.8 this is incompatible with sql_mode=only_full_group_by
[42000][1055] Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated colu ...
- 运维面试题之linux基础
吐槽: 某某命令是什么,某个配置文件的路径,呃....你难道不知道有--help和Tab这种东西吗? linux系统的启动过程是怎么样的? grub引导>加载内核>启动init进程依据in ...
- Windows 系统快速查看文件MD5
关键 ·打开命令窗口(Win+R),然后输入cmd ·输入命令certutil -hashfile 文件绝对路径 MD5 快速获取文件绝对路径 ·找到文件,右键属性 注意 ·在Win7上,MD5不要使 ...