第四节,目标检测---YOLO系列
1、R-CNN回顾

适应全卷积化CNN结构,提出全卷积化设计
- 共享ResNet的所有卷积层
- 引入变换敏感性(Translation variance)
- 位置敏感分值图(Position-sensitive score maps)
- 特殊设计的卷积层
- Grid位置信息+类别分值
- 位置敏感池化(Position-sensitive RoI pooling)
- 无训练参数
- 无全连接网络的类别推断
- 位置敏感分值图(Position-sensitive score maps)
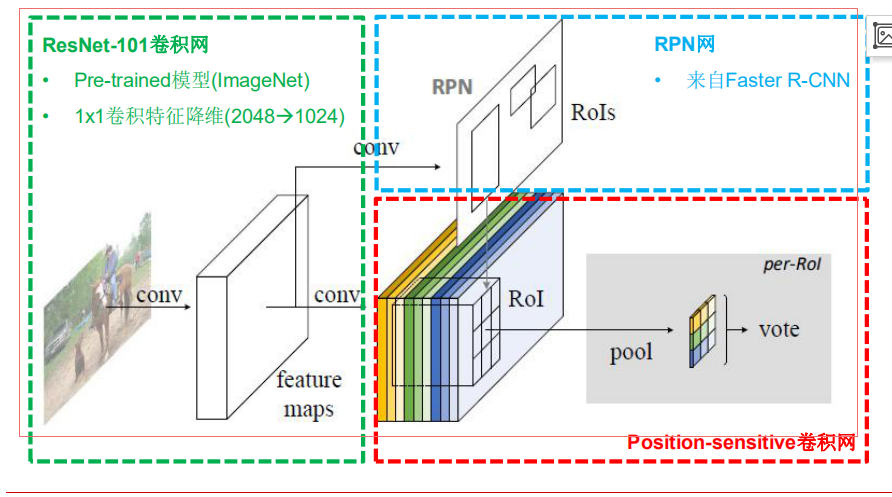
R-FCN的位置敏感卷积层
使用k2(C+1)个通道对(位置,类别)组合进行编码
- 类别:C个物体类+1个背景类
- 相对位置:kxk个Grid(k=3)
- 位置敏感分值图(Position-sensitive score maps)
- 每个分类k2个score map
- score map 尺寸=图片尺寸
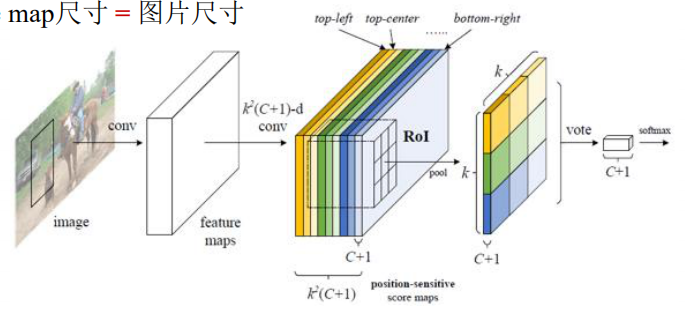
R-FCN的位置敏感RoI池化层
显式地编码相对位置信息
- 将wxh尺寸的RoI拆分成kxk个w/k x h/k尺寸的bin
- 不同(颜色)bin对应不同(颜色)通道层(score map)
- Bin内做均值池化
- 输出尺寸kxkx(C+1)
R-FCN的多任务损失函数

2、YOLO v1:GoogLeNet前20层
YOLO将物体检测任务当作一个regression问题来处理,通过YOLO,每张图像只需要“看一眼”就能得出图像中都有哪些物体和这些物体的位置。
- 将图像resize到448x448作为神经网络的输入,
- 使用一个神经网络,直接从一整张图像来预测出bbox的坐标、box中包含物体的置信度和物体的可能性,
- 然后进行非极大值抑制,筛选Boxes。
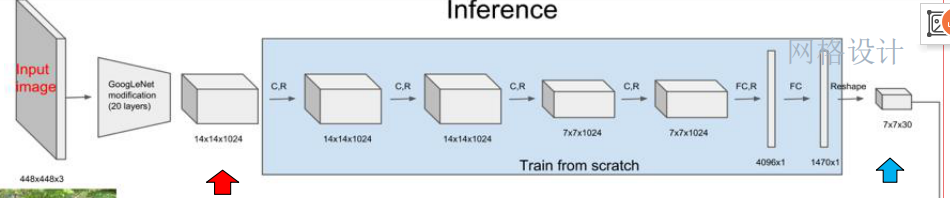
- 首先利用ImageNet 1000-class的分类任务数据集Pretrain卷积层,使用GoogLeNet中的前20个卷积层,加上一个average-pooling layer,最后加一个全连接层,作为Pretrain的网络。
- 将Pretrain的结果的前20层卷积层应用到Detection中,并加入剩下的4个卷积层及2个全连接层。
- 同时为了获取更精细化的结果,将输入图像的分辨率由224x224提升到448x448。
- 将所有的预测结果都归一化到0~1,使用Leaky RELU作为激活函数。
- 为了防止过拟合,在第一个全连接层后面接了一个ratio=0.5的Dropout层。
- YOLO网络结构由24个卷积层与2个全连接层构成,网络入口为448x448,图片进入网络先经过resize,网络的输出结果为一个张量。
- 输出维度:S*S*(B*5+C)
- 在Pascal VOC上,预测的结果维度是7*7*(2*5+20):其中S为划分网格数,B为每个网格负责目标个数,C为类别个数。

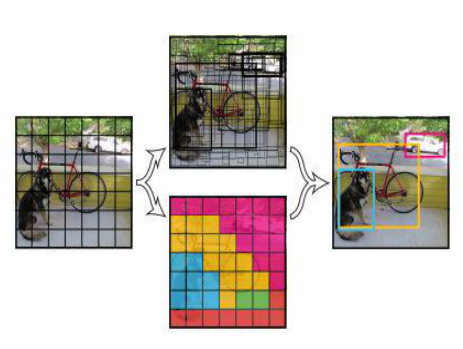
将一幅图像分成SxS个网格(grid cell),图中物体“狗”的中心点(红色原点)落入第5行、第2列的格子内,所以这个格子负责预测图像中的狗。
每一个栅格预测B(B=2)个bboxes,以及这些bboxes的confidence scores。
confidence scores反映了模型对于这个栅格的预测:该栅格是否含有物体,以及这个box的坐标预测的有多准。
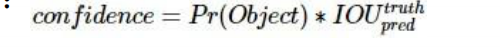
如果这个栅格中不存在object,则confidence score应该为0;否则的话,confidence score则为predicted bound ing box与ground truth box之间的IoU(intersection over union)
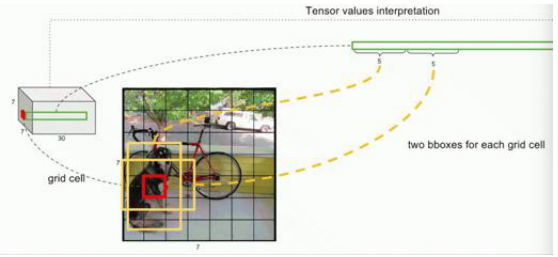
- YOLO v1:每个栅格两个bbox:横向和纵向各有一个框,根据匹配情况选择合适的框;对每个bbox有5个预测值:x,y,w,h,confidence;作为预测的结果(生成的7*7*30的张量)每一行中前10个元素,后20个元素对应于20个类别的概率。
- 每一个栅格还要预测C条件类别概率(conditional class probability):Pr(Classi|Object)。即在一个栅格包含一个Object的前提下,它属于某个类的概率。
- 条件类别概率:是针对每个栅格的。
- Confidence:是针对每个bbox的。
- 在测试阶段,将每个栅格的条件类别概率与你每个bbox的confidence相乘:

NMS(非极大值抑制):
- 首先从所有的检测框中找到置信度最大的那个框;
- 然后挨个计算其余剩余框的IoU,如果其值大于一定阈值(重合度过高),那么就将该框剔除;
- 之后对剩余的检测框重复上述过程,直到处理完所有的检测框。
YOLO v1的优点:
- 检测物体的速度很快;
- 假阳性率低;
- 能够学到更加抽象的物体的特征
YOLO v1的不足:
- YOLO的物体检测精度低于其他state-of-the-art的物体检测系统;
- YOLO容易产生物体的定位错误;
- YOLO对小物体的检测效果不好(尤其是密集的小物体,因为一个栅格只能预测2个物体)。
3、YOLO v2改进
- Batch Normalization
- Batch Normalization可以提高模型收敛速度,减少过拟合,在所有卷积层都应用了BN,是结果提升了2%。
- High Resolution Classifier
- 基于ImageNet数据集预训练模型,大部分类器输入图像尺寸小于256x256;
- 在YOLO v2中,首先采用448*448分辨率的ImageNet数据fine tune使网络适应高分辨率 输入;
- 然后将该网络用于目标检测任务finetune。高分辨率输入使结果提升了4%mAP。
- Convolutional With Anchor Boxes
- 借鉴了Faster R-CNN中的anchor思想,用anchor boxes来预测bounding boxes。准确率只有小幅度的下降,而召回率则提升了7%。
- Dimension Clusters
- 使用了K-means聚类方法类训练bounding boxes,可以自动找到更好的boxes宽高维度。
- Multi-Scale Training
- 模型只包含卷积层和pooling层,因此可以随时改变输入尺寸。每经过10次训练,就会随机选择新的图片尺寸进行训练。
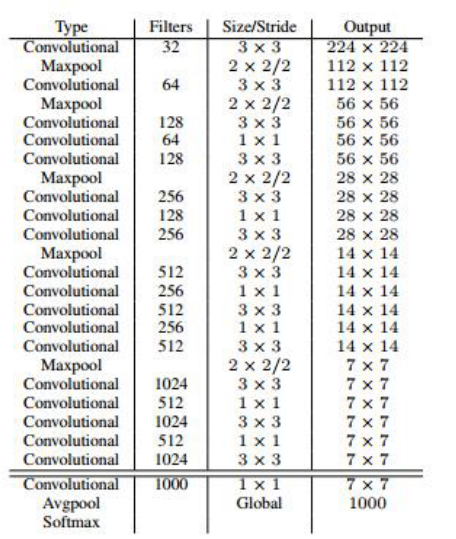
YOLO v2的基础模型是Darknrt-19:
使用较多的3*3卷积核,在每一次池化操作后把通道数翻倍。
网络使用了全局平均池化,把1*1的卷积核置于3*3的卷积核之间,用来压缩特征。
使用了BN稳定模型训练。
4、YOLO v3
YOLO v3中使用了一个53层的卷积网络,这个网络由残差单元叠加而成。
YOLO v3使用逻辑回归预测每个边界框的分数。
为了实现多标签分类,模型不再使用softmax函数作为最终的分类器,而是使用binary cross-entropy作为损失函数。
多尺度预测:YOLO v3从三种不同尺度夫人特征图谱上进行预测任务。
- 在Darknet-53得到的特征图的基础上,经过7个卷积得到第一个特征图谱,在这个特征图谱上做第一次预测。
- 然后从后向前获得倒数第3个卷积层的输出,进行一次卷积一次x2上采样,将上采样特征与第43个卷积特征连接,经过7个卷积得到第二个特征t图谱,在这个特征图谱上做第二次预测。
- 然后从后向前获得倒数第3个卷积层的输出,进行一次卷积一次x2上采样,将上采样特征与第26个卷积特征连接,经过7个卷积得到第三个特征图谱,在这个特征图谱上做第三次预测。
第四节,目标检测---YOLO系列的更多相关文章
- 小白也能弄得懂的目标检测YOLO系列之YOLOv1网络训练
上期给大家介绍了YOLO模型的检测系统和具体实现,YOLO是如何进行目标定位和目标分类的,这期主要给大家介绍YOLO是如何进行网络训练的,话不多说,马上开始! 前言: 输入图片首先被分成S*S个网格c ...
- 小白也能弄懂的目标检测YOLO系列之YOLOV1 - 第二期
上期给大家展示了用VisDrone数据集训练pytorch版YOLOV3模型的效果,介绍了什么是目标检测.目标检测目前比较流行的检测算法和效果比较以及YOLO的进化史,这期我们来讲解YOLO最原始V1 ...
- 深度学习笔记之目标检测算法系列(包括RCNN、Fast RCNN、Faster RCNN和SSD)
不多说,直接上干货! 本文一系列目标检测算法:RCNN, Fast RCNN, Faster RCNN代表当下目标检测的前沿水平,在github都给出了基于Caffe的源码. • RCNN RCN ...
- [目标检测]YOLO原理
1 YOLO 创新点: 端到端训练及推断 + 改革区域建议框式目标检测框架 + 实时目标检测 1.1 创新点 (1) 改革了区域建议框式检测框架: RCNN系列均需要生成建议框,在建议框上进行分类与回 ...
- 目标检测-yolo
论文下载:http://arxiv.org/abs/1506.02640 代码下载:https://github.com/pjreddie/darknet 1.创新点 端到端训练及推断 + 改革区域建 ...
- (四)目标检测算法之Fast R-CNN
系列博客链接: (一)目标检测概述 https://www.cnblogs.com/kongweisi/p/10894415.html (二)目标检测算法之R-CNN https://www.cnbl ...
- [目标检测]RCNN系列原理
1 RCNN 1.1 训练过程 (1) 训练时采用fine-tune方式: 先用Imagenet(1000类)训练,再用PASCAL VOC(21)类来fine-tune.使用这种方式训练能够提高8个 ...
- 目标检测YOLO进化史之yolov1
yolov3在目标检测领域可以算得上是state-of-art级别的了,在实时性和准确性上都有很好的保证.yolo也不是一开始就达到了这么好的效果,本身也是经历了不断地演进的. yolov1 测试图片 ...
- 目标检测YOLO算法-学习笔记
算法发展及对比: 17年底,mask-R CNN YOLO YOLO最大的优势就是快 原论文中流程,可以检测出20类物体. 红色网格-张量,在这样一个1×30的张量中保存的数据 横纵坐标中心点缩放到0 ...
随机推荐
- 好程序员web前端开发测验之css部分
好程序员web前端开发测验之css部分Front End Web Development Quiz CSS 部分问题与解答 Q: CSS 属性是否区分大小写? <p><font si ...
- MySQL 8.0.x for Windows 解压缩版配置安装
一.官网下载MySQL8.0.16 直达官网下载Community版:https://dev.mysql.com/downloads/mysql/ 然后拉倒下方点击对应版本位数下载 二.创建my.in ...
- Unit 6.标准文档流,浮动,清除浮动以及margin塌陷问题
一. 什么是标准文档流 文本流其实就是文档的读取和输出顺序,也就是我们通常看到的由左到右.由上而下的读取和输出形式,在网页中每个元素都是按照这个顺序进行排序和显示的,而float和position两个 ...
- Linux 学习 (六) 关机与重启命令
Linux达人养成计划 I 学习笔记 shutdown [选项] 时间 -c:取消前一个关机命令 -h:关机 -r:重启 shutdown命令会在关机或重启时自动保存系统中正在运行的服务,最安全的关机 ...
- iOS 高德自定义坐标轨迹绘制动画 类似与Keep的轨迹绘制
2. 自定义 线的图片,只需要在 rendererForOverlay 方法中,设置: polylineRenderer.strokeImage = [UIImage imageNamed:@&quo ...
- jsp篇 之 基本概念
Jsp概念: 1.jsp是什么 jsp全称Java Server Pages,是一种[动态网页开发技术]. .html文件是静态页面 .jsp 文件是动态页面 jsp页面允许我们在html代码中[嵌入 ...
- Html | Vue | Element UI——引入使用
前言 做个项目,需要一个效果刚好Element UI有,就想配合Vue和Element UI,放在tp5.1下使用,但是引入在线的地址各种报错,本地引入就完美的解决了问题! 代码 __STATIC_J ...
- 初学cdq分治学习笔记(可能有第二次的学习笔记)
前言骚话 本人蒟蒻,一开始看到模板题就非常的懵逼,链接,学到后面就越来越清楚了. 吐槽,cdq,超短裙分治....(尴尬) 正片开始 思想 和普通的分治,还是分而治之,但是有一点不一样的是一般的分治在 ...
- beam 的异常处理 Error Handling Elements in Apache Beam Pipelines
Error Handling Elements in Apache Beam Pipelines Vallery LanceyFollow Mar 15 I have noticed a defici ...
- 第七篇--ubuntu18.04下面特殊符号
按住键盘win键,在搜索框输入“字符”,弹出来的工具点进去 需要什么符号就找什么符号,然后点击它复制就好.