pytorch预训练
Pytorch预训练模型以及修改
pytorch中自带几种常用的深度学习网络预训练模型,torchvision.models包中包含alexnet、densenet、inception、resnet、squeezenet、vgg等常用网络结构,并且提供了预训练模型,可通过调用来读取网络结构和预训练模型(模型参数)。往往为了加快学习进度,训练的初期直接加载pretrain模型中预先训练好的参数。加载model如下所示:
import torchvision.models as models
1.加载网络结构和预训练参数:resnet34 = models.resnet34(pretrained=True)
2.#只加载网络结构,不加载预训练参数,即不需要用预训练模型的参数来初始化:
resnet18 = models.resnet18(pretrained=False) #pretrained参数默认是False,为了代码清晰,最好还是加上参数赋值.
print resnet18 #打印网络结构
resnet18.load_state_dict(torch.load(path_params.pkl))#其中,path_params.pkl为预训练模型参数的保存路径。加载预先下载好的预训练参数到resnet18,用预训练模型的参数初始化resnet18的层,此时resnet18发生了改变。调用model的load_state_dict方法用预训练的模型参数来初始化自己定义的新网络结构,这个方法就是PyTorch中通用的用一个模型的参数初始化另一个模型的层的操作。load_state_dict方法还有一个重要的参数是strict,该参数默认是True,表示预训练模型的层和自己定义的网络结构层严格对应相等(比如层名和维度)。故,当新定义的网络(model_dict)和预训练网络(pretrained_dict)的层名不严格相等时,需要先将pretrained_dict里不属于model_dict的键剔除掉 :
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict} ,再用预训练模型参数更新model_dict,最后用load_state_dict方法初始化自己定义的新网络结构。
print resnet18 #打印的还是网络结构
注意: cnn = resnet18.load_state_dict(torch.load( path_params.pkl )) #是错误的,这样cnn将是nonetype
pre_dict = resnet18.state_dict() #按键值对将模型参数加载到pre_dict
print for k, v in pre_dict.items(): # 打印模型参数
for k, v in pre_dict.items():
print k #打印模型每层命名
#model是自己定义好的新网络模型,将pretrained_dict和model_dict中命名一致的层加入pretrained_dict(包括参数)。
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
预训练模型的修改(具体要求不同,则用到的修改方式不同。)
1. 参数修改
对于简单的参数修改,这里以resnet预训练模型举例,resnet源代码在Github。 resnet网络最后一层分类层fc是对1000种类型进行划分,对于自己的数据集,如果只有9类,修改的代码如下:
# coding=UTF-8
import torchvision.models as models
#调用模型
model = models.resnet50(pretrained=True)
#提取fc层中固定的参数
fc_features = model.fc.in_features
#修改类别为9
model.fc = nn.Linear(fc_features, 9)
2. 增减卷积层 (待补充)
前一种方法只适用于简单的参数修改,有时候往往要修改网络中的层次结构,这时只能用参数覆盖的方法,即自己先定义一个类似的网络,再将预训练中的参数提取到自己的网络中来。这里以resnet预训练模型举例。
3. 训练特定层,冻结其它层
另一种使用预训练模型的方法是对它进行部分训练。具体做法是,将模型起始的一些层的权重保持不变,重新训练后面的层,得到新的权重。在这个过程中,可多次进行尝试,从而能够依据结果找到frozen layers和retrain layers之间的最佳搭配。
如何使用预训练模型,是由数据集大小和新旧数据集(预训练的数据集和自己要解决的数据集)之间数据的相似度来决定的。
下图表展示了在各种情况下应该如何使用预训练模型: 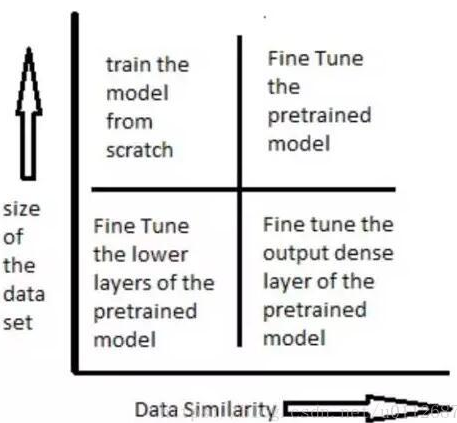
Pytorch保存与加载网络模型,有以下两种方式: (推荐第二种)
一、是保存整个神经网络的的结构信息和模型参数信息,save的对象是网络net;
torch.save(model_object, 'model.pkl') # 保存整个神经网络的结构和模型参数
重载:model = torch.load('model.pkl') #重载并初始化新的神经网络对象。
二、是只保存神经网络的训练模型参数,save的对象是net.state_dict()。
torch.save(model_object.state_dict(), 'params.pkl') # 只保存神经网络的模型参数
需要首先导入对应的网络,通过model_object.load_state_dict(torch.load('params.pkl'))完成模型参数的重载和初始化新定义的网络。
PyTorch中使用预训练的模型初始化网络的一部分参数
#首先自己新定义一个网络
class CNN(nn.Module):
def __init__(self, block, layers, num_classes=9): #自己新定义的CNN与继承的ResNet网络结构大体相同,即除了新增层,其他层的层名与ResNet的相同。
self.inplanes = 64
super(ResNet, self).__init__() #继承ResNet网络结构
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
#新增一个反卷积层
self.convtranspose1 = nn.ConvTranspose2d(2048, 2048, kernel_size=3, stride=1, padding=1, output_padding=0, groups=1, bias=False, dilation=1)
#新增一个最大池化层
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
#将原来的fc层改成fclass层
self.fclass = nn.Linear(2048, num_classes) #原来的fc层:self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules(): #
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels #
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = [ ]
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
#3个新加层的forward
x = x.view(x.size(0), -1) #因为接下来的self.convtranspose1层的输入通道是2048
x = self.convtranspose1(x)
x = self.maxpool2(x)
x = x.view(x.size(0), -1) #因为接下来的self.fclass层的输入通道是2048
x = self.fclass(x)
return x
#加载model
resnet50 = models.resnet50(pretrained=True)
cnn = CNN(Bottleneck, [3, 4, 6, 3]) #创建一个自己新定义的网络对象cnn。
pretrained_dict = resnet50.state_dict() #记录预训练模型的参数:resnet50.state_dict()。若已存在 resnet50.state_dict()对应的模型参数文件 'params.pkl',则此句代码等价于:pretrained_dict =torch.load(path_params.pkl) ?其中,path_params.pkl为' params.pkl '的保存路径。
model_dict = cnn.state_dict() #自己新定义网络的参数
# 将pretrained_dict里不属于model_dict的键剔除掉 ,因为后面的cnn.load_state_dict()方法有个重要参数是strict,默认是True,表示预训练模型的层和自己定义的网络结构层严格对应相等(比如层名和维度)。
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict} #只能对层名一致的层进行“层名:参数”键值对赋值。
# 更新现有的model_dict
model_dict.update(pretrained_dict)
# 加载我们真正需要的模型参数state_dict
cnn.load_state_dict(model_dict) #cnn.load_state_dict()方法对cnn初始化,其一个重要参数strict,默认为True,表示预训练模型(model_dict)的层和自己定义的网络结构(cnn)的层严格对应相等(比如层名和维度)。
print(cnn)
后续在此基础上继续重新进行训练,如下面即将介绍的: 选择特定的层进行finetune 。
选择特定的层进行finetune
先使用Module.children()方法查看网络的直接子模块,将不需要调整的模块中的参数设置为param.requires_grad = False,同时用一个list收集需要调整的模块中的参数。具体代码为:
count = 0
para_optim = []
for k in model.children():
count += 1
if count > 6: # 6 should be changed properly
for param in k.parameters():
para_optim.append(param)
else:
for param in k.parameters():
param.requires_grad = False
optimizer = optim.RMSprop(para_optim, lr)#只对特定的层的参数进行优化更新,即选择特定的层进行finetune。
到此我们实现了PyTorch中使用预训练的模型初始化网络的一部分参数。
此部分主要参考PyTorch教程的Autograd machnics部分
1.在PyTorch中,每个Variable数据含有两个flag(requires_grad和volatile)用于指示是否计算此Variable的梯度。设置requires_grad = False,或者设置volatile=True,即可指示不计算此Variable的梯度:
for param in model.parameters():
param.requires_grad = False
注意,在模型测试时,对input_data设置volatile=True,可以节省测试时的显存 。
2.PyTorch的Module.modules()和Module.children()
参考PyTorch document和discuss
在PyTorch中,所有的neural network module都是class torch.nn.Module的子类,在Modules中可以包含其它的Modules,以一种树状结构进行嵌套。当需要返回神经网络中的各个模块时,Module.modules()方法返回网络中所有模块的一个iterator,而Module.children()方法返回所有直接子模块的一个iterator。具体而言:
list ( nn.Sequential(nn.Linear(10, 20), nn.ReLU()).modules() )
Out[9]:
[Sequential (
(0): Linear (10 -> 20)
(1): ReLU ()
), Linear (10 -> 20), ReLU ()]
In [10]: list( nn.Sequential(nn.Linear(10, 20), nn.ReLU()) .children() )
Out[10]: [Linear (10 -> 20), ReLU ()]
举例:Faster-RCNN基于vgg19提取features,但是只使用了vgg19一部分模型提取features。
步骤:
下载vgg19的pth文件,在anaconda中直接设置pretrained=True下载一般都比较慢,在model_zoo里面有各种预训练模型的下载链接:
model_urls = {
'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth',
'vgg11_bn': 'https://download.pytorch.org/models/vgg11_bn-6002323d.pth',
'vgg13_bn': 'https://download.pytorch.org/models/vgg13_bn-abd245e5.pth',
'vgg16_bn': 'https://download.pytorch.org/models/vgg16_bn-6c64b313.pth',
'vgg19_bn': 'https://download.pytorch.org/models/vgg19_bn-c79401a0.pth' }
下载好的模型,可以用下面这段代码看一下模型参数,并且改一下模型。在vgg19.pth同级目录建立一个test.py。
import torch
import torch.nn as nn
import torchvision.models as models
vgg16 = models.vgg16(pretrained=False)
#打印出预训练模型的参数
vgg16.load_state_dict(torch.load('vgg16-397923af.pth'))
print('vgg16:\n', vgg16)
modified_features = nn.Sequential(*list(vgg16.features.children())[:-1])
# to relu5_3
print('modified_features:\n', modified_features )#打印修改后的模型参数
修改好之后features就可以拿去做Faster-RCNN提取特征用了。
pytorch预训练的更多相关文章
- pytorch中如何使用预训练词向量
不涉及具体代码,只是记录一下自己的疑惑. 我们知道对于在pytorch中,我们通过构建一个词向量矩阵对象.这个时候对象矩阵是随机初始化的,然后我们的输入是单词的数值表达,也就是一些索引.那么我们会根据 ...
- PyTorch在NLP任务中使用预训练词向量
在使用pytorch或tensorflow等神经网络框架进行nlp任务的处理时,可以通过对应的Embedding层做词向量的处理,更多的时候,使用预训练好的词向量会带来更优的性能.下面分别介绍使用ge ...
- PyTorch ImageNet 基于预训练六大常用图片分类模型的实战
微调 Torchvision 模型 在本教程中,我们将深入探讨如何对 torchvision 模型进行微调和特征提取,所有这些模型都已经预先在1000类的Imagenet数据集上训练完成.本教程将深入 ...
- pytorch之对预训练的bert进行剪枝
大体过程 对层数进行剪枝 1.加载预训练的模型: 2.提取所需要层的权重,并对其进行重命名.比如我们想要第0层和第11层的权重,那么需要将第11层的权重保留下来并且重命名为第1层的名字: 3.更改模型 ...
- 最强 NLP 预训练模型库 PyTorch-Transformers 正式开源:支持 6 个预训练框架,27 个预训练模型
先上开源地址: https://github.com/huggingface/pytorch-transformers#quick-tour 官网: https://huggingface.co/py ...
- 学习TensorFlow,调用预训练好的网络(Alex, VGG, ResNet etc)
视觉问题引入深度神经网络后,针对端对端的训练和预测网络,可以看是特征的表达和任务的决策问题(分类,回归等).当我们自己的训练数据量过小时,往往借助牛人已经预训练好的网络进行特征的提取,然后在后面加上自 ...
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史(转载)
转载 https://zhuanlan.zhihu.com/p/49271699 首发于深度学习前沿笔记 写文章 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 张 ...
- 【算法】Bert预训练源码阅读
Bert预训练源码 主要代码 地址:https://github.com/google-research/bert create_pretraning_data.py:原始文件转换为训练数据格式 to ...
- 【译】深度双向Transformer预训练【BERT第一作者分享】
目录 NLP中的预训练 语境表示 语境表示相关研究 存在的问题 BERT的解决方案 任务一:Masked LM 任务二:预测下一句 BERT 输入表示 模型结构--Transformer编码器 Tra ...
随机推荐
- flex 垂直居中、两列对齐、自适应宽
flex 垂直居中 <div id="parent"> <div id="child"> </div> </div&g ...
- Cocos Creator学习三:生命周期回调函数
1.目的:学习生命周期回调函数以及回调顺序,更有利于我们逻辑的处理把控. 2.生命周期回调函数: 节点:指cc.Node:组件:指cc.Component. ①onLoad:脚本组件绑定的节点所在场景 ...
- C#_计算目前时间到指定的周X、指定的时间X 还有多少秒
比如:当前时间到下周二 05:00:00还剩下多少秒? /// <summary> /// 计算距离下一个 周XX XX时XX分XX秒,还剩下多少秒 /// </summary> ...
- [Ubuntu] 运行.AppImage格式文件
右键Properties, Permissions勾选Allow executing file as program,如图
- 使用http服务提供yum源
1.安装httpd yum -y install httpd systemctl start httpd systemctl enable httpd 2.镜像资源目录拷贝至http的网站根目录 /v ...
- git checkout branch
git fetch origin feature/banch1:feature/banch1 git checkout feature/banch1 git branch -u origin/feat ...
- 亚马逊VE账号运营
VE劲爆内幕大揭秘!“仿牌+Amazon VE”跟卖之路 Amazon Vendor Express 是Amazon.com2015年下旬推出的新的供应商平台,商家通过这个平台可以把产品卖给Amazo ...
- textarea跟随内容自动伸缩高度实现方案
监听input事件,然后将textarea的style.height设置为最低高度(19px),进而获取到元素的scrollHeight,然后将scroolHeight设置为style.height
- JQuery的常用选择器 转
JQuery的常用选择器 刚开始学JQuery写的如有错误欢迎批评指正 JQuery拥有的选择器可以让我们更快更方便找到想要的元素,然后对相应的元素进行操作 简单介绍一下一些常用的选择器: 1.基本选 ...
- VSCode 启动 Vue 项目 npm install 报错
1. 报错后,查看了版本. 查看node版本:node -v 查看npm版本:npm -v 查看Augular版本:ng --version 2. 感觉 Augular CLI版本太低,使用以下方 ...