索引法则--LIKE以%开头会导致索引失效进而转向全表扫描(使用覆盖索引解决)
===============
1 准备数据
1.1 建表
DROP TABLE IF EXISTS staff;
CREATE TABLE IF NOT EXISTS staff (
id INT PRIMARY KEY auto_increment,
name VARCHAR(50),
age INT,
pos VARCHAR(50) COMMENT '职位',
salary DECIMAL(10,2)
);
1.2 插入数据
INSERT INTO staff(name, age, pos, salary) VALUES('Alice', 22, 'HR', 5000);
2 测试&Explain分析
2.1 有索引的情况下%的影响(提出问题)
2.1.1 建立索引
CREATE INDEX idx_nameAgePos ON staff(name, age, pos);
2.1.2 测试&Explain分析
Case#1:两边都是%
EXPLAIN SELECT * FROM staff WHERE name LIKE '%Alice%';

结果:type=all,全表扫描
Case#2:左边是%
EXPLAIN SELECT * FROM staff WHERE name LIKE '%Alice';

结果:type=all,全表扫描
Case#3:右边是%
EXPLAIN SELECT * FROM staff WHERE name LIKE 'Alice%';

结果:type=range,效果还可以。
对上面三个例子的总结:
- 都是 SELECT *
- %在左边,即使有索引,也会失效
- 只有当%在右边时,才会生效
但问题是,生产环境中,就是要支持模糊查询(%在右边是不够的),一定要两边都是%来查询,这可咋办?
2.2 无索引情况下的查询汇总
2.2.1 删除索引
DROP INDEX idx_nameAgePos ON staff;
2.2.2 测试&Explain分析(主要为了和 2.3.2 节做对比测试)
Case#4:查询Id
EXPLAIN SELECT id FROM staff WHERE name LIKE '%Alice%';

Case#5:查询name
EXPLAIN SELECT name FROM staff WHERE name LIKE '%Alice%';

Case#6:查询age
EXPLAIN SELECT age FROM staff WHERE name LIKE '%Alice%';

Case#7:查询 id & name
EXPLAIN SELECT id, name FROM staff WHERE name LIKE '%Alice%';

Case#8:查询 name & age
EXPLAIN SELECT name, age FROM staff WHERE name LIKE '%Alice%';

Case#9:查询 id & name & age
EXPLAIN SELECT id, name, age FROM staff WHERE name LIKE '%Alice%';

Case#10:查询 id & name & age & salary (提示:salary 不在索引列中,后面会用上)
EXPLAIN SELECT id, name, age, salary FROM staff WHERE name LIKE '%Alice%';

Case#11:查询 *
EXPLAIN SELECT * FROM staff WHERE name LIKE '%Alice%';

从 Case#4 到 Case#11 可以看出,在没有索引的情况下,两边都使用 % 来查询,不管想查询哪个字段(包括查询Id),全部都是全表扫描。
2.3 有索引情况下的查询汇总
2.3.1 建立索引
CREATE INDEX idx_nameAgePos ON staff(name, age, pos);
2.3.2 测试&Explain分析
IndexCase#4:查询Id
EXPLAIN SELECT id FROM staff WHERE name LIKE '%Alice%';
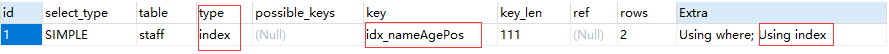
结果:使用上了索引(因为 name 有索引,同时查询的 Id 是主键肯定也有索引)
IndexCase#5:查询name
EXPLAIN SELECT name FROM staff WHERE name LIKE '%Alice%';

结果:使用上了索引(因为查询条件和查询字段都是有索引的 name)
IndexCase#6:查询age
EXPLAIN SELECT age FROM staff WHERE name LIKE '%Alice%';

结果:使用上了索引(因为查询条件的 name 以及查询字段的 age 都有索引)
IndexCase#7:查询 id & name
EXPLAIN SELECT id, name FROM staff WHERE name LIKE '%Alice%';

结果:使用上了索引(因为查询条件的 name 以及查询字段的 id & name 都有索引)
IndexCase#8:查询 name & age
EXPLAIN SELECT name, age FROM staff WHERE name LIKE '%Alice%';
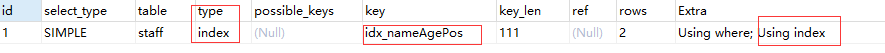
结果:使用上了索引(因为查询条件的 name 以及查询字段的 name & age 都有索引)
IndexCase#9:查询 id & name & age
EXPLAIN SELECT id, name, age FROM staff WHERE name LIKE '%Alice%';

结果:使用上了索引(因为查询条件的 name 以及查询字段的 id & name & age 都有索引)
IndexCase#10:查询 id & name & age & salary (提示:salary 不在索引列中)
EXPLAIN SELECT id, name, age, salary FROM staff WHERE name LIKE '%Alice%';

结果:没有索引,type=all,全表扫描!(因为查询字段中多了个 salary 而 salary 不在索引列中)
IndexCase#11:查询 *
EXPLAIN SELECT * FROM staff WHERE name LIKE '%Alice%';

结果:没有索引,type=all,全表扫描!(因为 * 包含 salary 而 salary 不在索引列中)
通过 IndexCase#4 到 IndexCase#11 可以看出,当真的需要两边都使用%来模糊查询时,只有当这个作为模糊查询的条件字段(例子中的name)以及所想要查询出来的数据字段(例子中的 id & name & age)都在索引列上时,才能真正使用索引,否则,索引失效全表扫描(比如多了一个 salary 字段)。我想,这应该就是 ‘覆盖索引(索引覆盖)’ 的本质吧。同时,这也能很好的证实 “尽量避免SELECT * 而是一一罗列出所需要查询的字段” 的道理吧,因为,搞不好 SELECT * 就多了一个字段,就导致了全表扫描。
3 结论
LIKE以%开头会导致索引失效;使用覆盖索引解决之
索引法则--LIKE以%开头会导致索引失效进而转向全表扫描(使用覆盖索引解决)的更多相关文章
- 陷阱~SQL全表扫描与聚集索引扫描
SqlServer中在查询时,我们为了优化性能,通常会为where条件的字段建立索引,如果条件比较固定还会建立组合索引,接下来,我们来看一下索引与查询的相关知识及相关陷阱. SQL表自动为主键加聚集索 ...
- SQL SERVER中关于OR会导致索引扫描或全表扫描的浅析
在SQL SERVER的查询语句中使用OR是否会导致不走索引查找(Index Seek)或索引失效(堆表走全表扫描 (Table Scan).聚集索引表走聚集索引扫描(Clustered Index ...
- SQL SERVER中关于OR会导致索引扫描或全表扫描的浅析 (转载)
在SQL SERVER的查询语句中使用OR是否会导致不走索引查找(Index Seek)或索引失效(堆表走全表扫描 (Table Scan).聚集索引表走聚集索引扫描(Clustered Index ...
- SQL 数据优化索引建suo避免全表扫描
首先什么是全表扫描和索引扫描?全表扫描所有数据过一遍才能显示数据结果,索引扫描就是索引,只需要扫描一部分数据就可以得到结果.如果数据没建立索引. 无索引的情况下搜索数据的速度和占用内存就会比用索引的检 ...
- sql语句优化:尽量使用索引避免全表扫描
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- 【翻译自mos文章】SYS_OP_C2C 导致的全表扫描(fts)/全索引扫描
SYS_OP_C2C 导致的全表扫描(fts)/全索引扫描 參考原文: SYS_OP_C2C Causing Full Table/Index Scans (Doc ID 732666.1) 适用于: ...
- 如何优雅的使用 参数 is null而不导致全表扫描(破坏索引)
相信大家在很多实际业务中(特别是后台系统)会使用到各种筛选条件来筛选结果集 首先添加测试数据 ), Age INT) go CREATE INDEX idx_age ON TempList (Age) ...
- mysql不会使用索引,导致全表扫描情况
不会使用索引,导致全表扫描情况 1.不要使用in操作符,这样数据库会进行全表扫描,推荐方案:在业务密集的SQL当中尽量不采用IN操作符 2.not in 使用not in也不会走索引推荐方案:用not ...
- MYSQL的全表扫描,主键索引(聚集索引、第一索引),非主键索引(非聚集索引、第二索引),覆盖索引四种不同查询的分析
文章出处:http://inter12.iteye.com/blog/1430144 MYSQL的全表扫描,主键索引(聚集索引.第一索引),非主键索引(非聚集索引.第二索引),覆盖索引四种不同查询的分 ...
随机推荐
- Mysql数据库mys和ora库的备份与恢复脚本
!/bin/bash Time=$(date +%Y%md%H%M%S) Back_dir="$HOME/mysqlback/${Time}" function Detect_u_ ...
- docker注意事项
当你最后投入容器的怀抱,发现它能解决很多问题,而且还具有众多的优点: 第一:它是不可变的 – 操作系统,库版本,配置,文件夹和应用都是一样的.您可以使用通过相同QA测试的镜像,使产品具有相同的表现 ...
- tornado解决高并发的初步认识牵扯出的一些问题
#!/bin/env python # -*- coding:utf-8 -*- import tornado.httpserver import tornado.ioloop import torn ...
- 三、如何使用QtDesigner
三.如何使用QtDesigner 启动 QtDesigner,创建一个PyQt项目 拖动Label到主窗体,双击并输入自己想输入的文字 并保持为 HelloWorld.ui 此时在你Python项目下 ...
- anguar使用指令写选项卡
今天,我们来学习一下angular中怎么使用指令来实现两个选项卡的问题. 首先,要先引入jQuery文件与angularjs文件. <!DOCTYPE html><html lang ...
- React-Native(四):React Native之View学习
React Native实现以下布局效果:携html5(http://m.ctrip.com/html5/) 基于HelloWord修改项目代码: /** * Sample React Native ...
- Django之auth模块(用户认证)
auth模块简介 auth模块是对登录认证方法的一种封装,之前我们获取用户输入的用户名及密码后需要自己从user表里查询有没有用户名和密码符合的对象, 而有了auth模块之后就可以很轻松的去验证用户的 ...
- 1.0 添加WEB API项目并按注释生成文档(多项目结构)
1.新建ASP.NET 项目,模板选择如图 2.选择Web API,并选择不进行身份验证方式 成功后我们看到这个结果. 至于其它三种身份验证方式,不太适合我的使用.而且这种方式也可以在代码里去实现身份 ...
- Java中List集合的三种遍历方式(全网最详)
List集合在Java日常开发中是必不可少的,只要懂得运用各种各样的方法就可以大大提高我们开发的效率,适当活用各种方法才会使我们开发事半功倍. 我总结了三种List集合的遍历方式,下面一一来介绍. 首 ...
- Treap讲解
Treap讲解 上一篇blog提出了Treap这个算法,在这里我就要详细讲解. 首先,我们可以从字面上理解这个算法,Treap这个单词是由Tree和Heap两个单词构成的,所以它的性质就很好理解了,明 ...