第六章——决策树(Decision Trees)
决策树是强大的,多功能的机器学习算法。
6.1 训练和可视化一个决策树
在iris数据集训练DecisionTreeClassifier:
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
X = iris.data[:, 2:] # petal length and width
y = iris.target
tree_clf = DecisionTreeClassifier(max_depth=2)
tree_clf.fit(X, y)
可以将训练好的决策树打印出来:
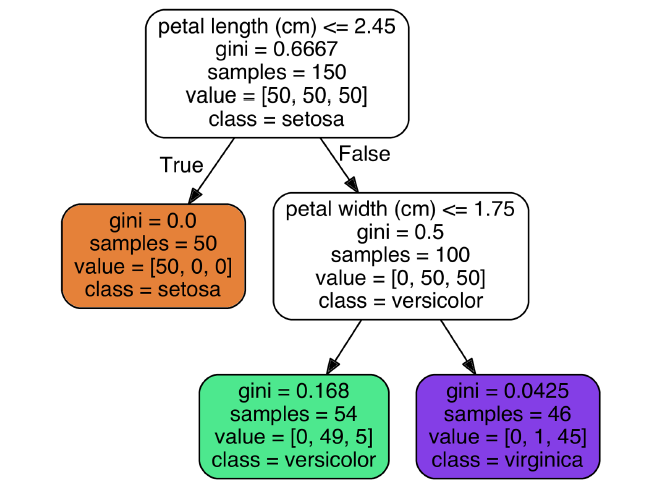
6.2 预测
从根节点开始,如果满足条件,则转向左子树,否则转向又子树。最终到达的叶子节点即为预测值。
决策树的一个优点是几乎不需要数据预处理,特别是不需要feature scaling或者centering。
基尼系数表示节点的纯洁度。如果gini=0,说明该节点是纯粹的,只包含一种类别。
第$i$个节点的Gini impurity:
$G_i = 1 - \sum_{k=1}^{n} p_{i,k}^2$
其中,$p_{i,k}$是类别$k$的样本数在节点$i$中样本总数所占的比例。
Scikit-Learn使用的是CART算法,产生的是二叉树:非叶子节点只有两个子节点。其它算法比如ID3可以生产具有更多子节点的决策树。
模型解释:白盒 Vs 黑盒:
决策树的可解释性很强,这被称作白盒模型。相应的,随机森林或者神经网络是黑盒模型。
6.3 评估类别概率(Estimating Class Probabilities)
类别的预测概率,就是叶子节点中该类别所占的比例。
6.4 CART训练算法
Scikit-Learn使用分类回归树(Classification And Regression Tree,CART)算法训练决策树。其思想很简单:使用属性$k$和相应的阈值$t_k$将训练集分为两个子集。搜索合适的$(k, t_k)$使得子集的纯净度最高。损失函数如下:
$J(k,t_k) = \frac{m_{left}}{m}G_{left} + \frac{m_{right}}{m}G_{right}$
其中,$G_{left}$、$G_{right}$是左、右子树的纯净度,$m_{left}$、$m_{right}$是左、右子树的样本数。
将训练集切分之后,会对子集继续切分,这是一个递归过程。如果达到最大深度就会停止(通过max_depth超参数控制),或者已经找不到可以增大纯净度的切分(比如已经完全纯净)。还有一些控制切分停止的超参数:min_samples_split, min_samples_leaf,min_weight_fraction_leaf, and max_leaf_nodes。
这是一个贪心算法,虽不能达到最优,但可以得到一足够优的结果。找到最优树属于NP完全(NP-Complete)问题,需要O(exp(m))时间,这使得即使是很小的训练集也难以求解。
6.5 计算复杂度
决策树预测过程,需要从根节点到达一个叶子节点,决策树一般是近似平衡的,这一过程复杂度为$O(log_2(m))$,与样本数无关。
训练过程需要比较所有的特征,训练复杂度是$(n times m log(m))$。
6.6 基尼系数还是熵(Gini Impurity or Entropy)?
熵:
$H_i = \sum_{k=1}^{n} p_{i,k}\ log(p_{i,k})$
二者差别不大,通常会得到相似的决策树。Gini impurity计算起来更快,所有它是默认的。如果非要说它们的区别,Gini impurity倾向于将最频繁的类别分在同一个分支,entropy倾向于生成更平衡的树。
6.7 正则化超参数(Regularization Hyperparameters)
决策树对训练数据几乎不做假设(与之相反,详细模型明显假设数据是线性的)。如果不进行约束,很容易造成过拟合。这种模型被称作无参数模型(nonparametric model),这并不是真的没有参数(通常有很多参数),而是参数个数不需要在训练之前确定下来,这就有很高的自由度去拟合训练数据。与之相反,比如线性模型这种参数模型,需要提前确定参数个数,所以其自由度是受限的,减少了过拟合的风险(但是增加了欠拟合的风险)。
为避免过拟合,需要在训练时现在决策树的自由度,这被称作正则化。正则化超参数跟算法有关,但一般情况下至少可以限制决策树的最大深度。在Scikit-Learn中这由max_depth超参数控制。
另外还有一些算法,不设限地训练决策树,训练完成后会修剪不必要的节点。如果一个节点的子节点都是叶子节点,对该节点的拆分带来的纯净度提升并不是统计学上有效的(statistically significant),那么其子节点就被认为是不必要的,会被删除掉。
6.7 回归
CART回归损失函数:
$J(k, t_k) = \frac{m_{left}}{m} MSE_{left} + \frac{m_{right}}{m} MSE_{right}$
其中,
$MSE_{node} = \sum_{i \in node}(\hat{y}_{node} - y_{(i)})^2$
$\hat{y}_{node} = \frac{1}{m_{node}}\sum_{i \in node}y^{(i)}$
6.8 不稳定性(Instability)
决策树虽然功能强大,但也有一些局限性。首先,决策树的决策边界都是正交直线(所有的切分都和某一个坐标轴垂直),这使得它们对数据集的旋转很敏感。例如,下图显示了简单的线性可分数据集,在左侧,决策树很容易将其切分。但是在右侧,数据集旋转45°,决策树出现了不必要的绕弯弯。尽管二者都很好地拟合了训练集,很明显右侧的模型难以很好地一般化。一个解决方案是使用PCA,它可以使训练集旋转到最好的方向。
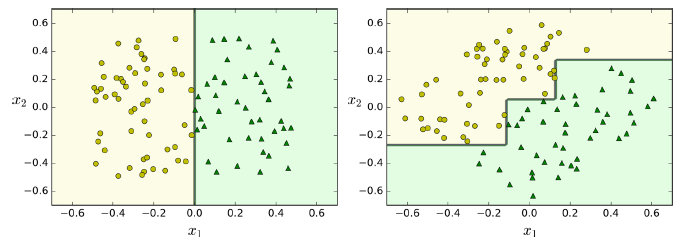
此外,决策树对训练数据集微小的变动也会很敏感。
随机森林通过许多决策树的预测平均值,可以避免这一不稳定性。
第六章——决策树(Decision Trees)的更多相关文章
- 海量数据挖掘MMDS week6: 决策树Decision Trees
http://blog.csdn.net/pipisorry/article/details/49445465 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- 决策树(Decision Trees)
简介 决策树是一个预测模型,通过坐标数据进行多次分割,找出分界线,绘制决策树. 在机器学习中,决策树学习算法就是根据数据,使用计算机算法自动找出决策边界. 每一次分割代表一次决策,多次决策而形成决策树 ...
- 【机器学习实战】第3章 决策树(Decision Tree)
第3章 决策树 <script type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/ ...
- Decision Trees 决策树
Decision Trees (DT)是用于分类和回归的非参数监督学习方法. 目标是创建一个模型,通过学习从数据特征推断出的简单决策规则来预测目标变量的值. 例如,在下面的例子中,决策树从数据中学习用 ...
- Facebook Gradient boosting 梯度提升 separate the positive and negative labeled points using a single line 梯度提升决策树 Gradient Boosted Decision Trees (GBDT)
https://www.quora.com/Why-do-people-use-gradient-boosted-decision-trees-to-do-feature-transform Why ...
- CatBoost使用GPU实现决策树的快速梯度提升CatBoost Enables Fast Gradient Boosting on Decision Trees Using GPUs
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频)https://study.163.com/course/introduction.htm?courseId=1005269003&ut ...
- 机器学习算法 --- Pruning (decision trees) & Random Forest Algorithm
一.Table for Content 在之前的文章中我们介绍了Decision Trees Agorithms,然而这个学习算法有一个很大的弊端,就是很容易出现Overfitting,为了解决此问题 ...
- Logistic Regression vs Decision Trees vs SVM: Part II
This is the 2nd part of the series. Read the first part here: Logistic Regression Vs Decision Trees ...
- Logistic Regression Vs Decision Trees Vs SVM: Part I
Classification is one of the major problems that we solve while working on standard business problem ...
随机推荐
- Media Player Classic - HC 源代码分析 7:详细信息选项卡(CPPageFileInfoDetails)
===================================================== Media Player Classic - HC 源代码分析系列文章列表: Media P ...
- PS 图像调整算法——阈值
PS里面这个算法,先将图像转成灰度图像,然后根据给定的阈值,大于该阈值的像素赋值为1,小于该阈值的赋值为0. if x>T, x=1; if x<T, x=0; 原图: 效果图:阈值为 1 ...
- hadoop的节点间的通信
一个DataNode上的Block是唯一的,多个DataNode可能有相同的Block. 2)通信场景: (1)NameNode的映射表上不永久保存每个DataNode所对应的block信息,而是通过 ...
- C语言之linux内核实现位数高低位互换
linux内核实在是博大精深,有很多优秀的算法,我之前在工作中就遇到过位数高低位交换的问题,那时候对于C语言还不是很熟练,想了很久才写出来.最近在看内核的时候看到有内核的工程师实现了这样的算法,和我之 ...
- 史上最全webview详解
本文来自:http://www.jianshu.com/users/320f9e8f7fc9/latest_articles WebView在现在的项目中使用的频率应该还是非常高的. 我个人总觉得HT ...
- web报表工具FineReport的SQL编辑框的语法简介
感谢大家捧场,这里继续分享关于SQL编辑框的一些语法心得总结,因为数据集定义的面板,也是FineReport报表中最常用的模块之一. 1.我理解的执行过程. 这里其实是生成一个字符串,FineRepo ...
- HFile
HFile存储格式 HBase中的所有数据文件都存储在Hadoop HDFS文件系统上,主要包括两种文件类型: 1. HFile, HBase中KeyValue数据的存储格式,HFile是Hadoop ...
- Mac OS 的属性列表文件plist装换
Mac OS系统自身包含有转换plist的工具:plutil.其中-p是以human可读方式显示plist文件,而convert就是转换参数,其中支持的格式有:xml,二进制和json.下面拿一个实际 ...
- Fullpage参数说明
参数说明 $(document).ready(function() { $('#fullpage').fullpage({ //Navigation menu: false,//绑定菜单,设定的相关属 ...
- 春天JDBC事务管理
JDBC事务管理 春天提供编程式的事务管理(编程式事务管理)与声明式的事务管理(声明式事务management),为不同的事务实现提供了一致的编程模型,这节以JDBC事务为例,介绍Spring的事务管 ...