SparkConf加载与SparkContext创建(源码阅读一)
即日起开始spark源码阅读之旅,这个过程是相当痛苦的,也许有大量的看不懂,但是每天一个方法,一点点看,相信总归会有极大地提高的。那么下面开始:
创建sparkConf对象,那么究竟它干了什么了类,从代码层面,我们可以看到我们需要setMaster啊,setAppName啊,set blabla啊。。。等等~
val sparkConf = new SparkConf().setMaster("local").setAppName("TopActiveLocations").set("spark.executor.memory", "3g")
那么我们就一点一点看一下,SparkConf是怎么实现的:
class SparkConf(loadDefaults: Boolean) extends Cloneable with Logging {
import SparkConf._
/** Create a SparkConf that loads defaults from system properties and the classpath */
def this() = this(true)
private val settings = new ConcurrentHashMap[String, String]()
if (loadDefaults) {
// Load any spark.* system properties
for ((key, value) <- Utils.getSystemProperties if key.startsWith("spark.")) {
set(key, value)
}
}
/** Set a configuration variable. */
def set(key: String, value: String): SparkConf = {
if (key == null) {
throw new NullPointerException("null key")
}
if (value == null) {
throw new NullPointerException("null value for " + key)
}
logDeprecationWarning(key)
settings.put(key, value)
this
}
你会发现,它声明了一个settings的ConcurrentHashMap,用的正是 java.util.concurrent.ConcurrentHashMap,从ConcurrentHashMap代码中可以看出,它引入了一个“分段锁”的概念,具体可以理解为把一个大的Map拆分成N个小的HashTable,根据key.hashCode()来决定把key放到哪个HashTable中。。。。额。。。我们是在玩spark,言归正传。
然后呢在声明对象是,SparkConf传入的是一个boolean类型的变量,这个变量的作用是是否加载Spark的conf下的配置信息,这个从def this() = this(true)可以看出,默认是为true的,这也就是为什么我们代码中提交集群,不用去专门set配置项的原因,而且大部分伙计不知道这里还可以传值~
随后,如果为true的情况下,它会去getSystemProperties进行加载。
def getSystemProperties: Map[String, String] = {
System.getProperties.stringPropertyNames().asScala
.map(key => (key, System.getProperty(key))).toMap
}
/**
* Enumerates all key/value pairs in the specified hashtable
* and omits the property if the key or value is not a string.
* @param h the hashtable
*/
private synchronized void enumerateStringProperties(Hashtable<String, String> h) {
if (defaults != null) {
defaults.enumerateStringProperties(h);
}
for (Enumeration e = keys() ; e.hasMoreElements() ;) {
Object k = e.nextElement();
Object v = get(k);
if (k instanceof String && v instanceof String) {
h.put((String) k, (String) v);
}
}
}
最终都存入了之前的map中,我们继续深入创建sparkContext对象。
val sc = new SparkContext(sparkConf)
然后我发现 它干了一大堆一大堆的变态的事情,首先我们看一下sparkContext的构造器:
class SparkContext(config: SparkConf) extends Logging with ExecutorAllocationClient {
// The call site where this SparkContext was constructed.
private val creationSite: CallSite = Utils.getCallSite()
// If true, log warnings instead of throwing exceptions when multiple SparkContexts are active
private val allowMultipleContexts: Boolean =
config.getBoolean("spark.driver.allowMultipleContexts", false)
// In order to prevent multiple SparkContexts from being active at the same time, mark this
// context as having started construction.
// NOTE: this must be placed at the beginning of the SparkContext constructor.
SparkContext.markPartiallyConstructed(this, allowMultipleContexts)
val startTime = System.currentTimeMillis()
首先,创建了CallSite对象,那么这个对象是干什么的呢,它存储了线程栈中最靠近栈顶的用户类及最靠近栈底的Scala或者Spark核心类信息。
这里,config.getBoolean("spark.driver.allowMultipleContexts", false)默认为false,曾经我以为只能在spark中创建一个Sparkcontext对象,其实可以创建多个(我勒个去啊,那是不是说明可以同时创建streaming对象以及sparkContext对象,将streaming与sparksql同时声明,一起做数据处理了,有待验证) 如果需要创建多个,就在配置参数中设置为true. markPartiallyConstructed会确保其唯一性。
接下来呢会拷贝config,并且进行默认值赋值,与为空判断,这里可以看到spark.master 和spark.app.name 是必须设置的,否则会抛出。
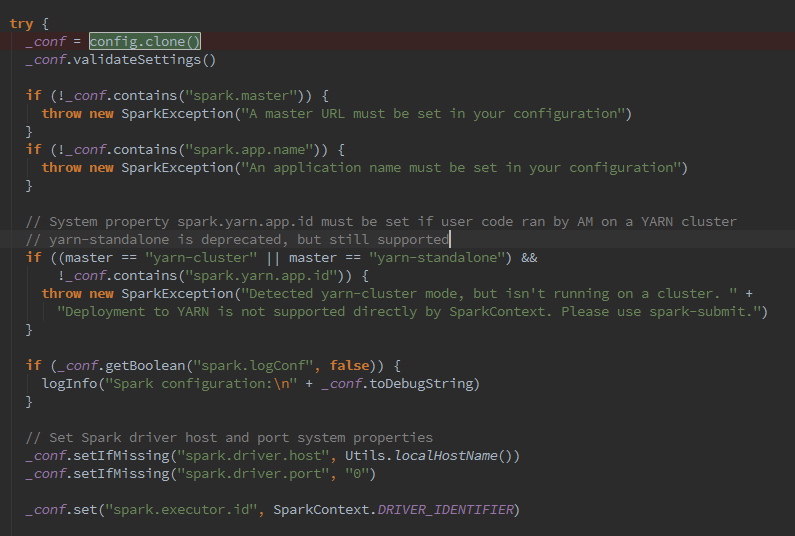
随之调用
SparkEnv.createDriverEnv(conf, isLocal, listenerBus, SparkContext.numDriverCores(master))方法,创建SparkEnv.查阅资料,SparkEnv呢,又干了N多事情如下:
1.创建安全管理器SecurityManager;
SecurityManager主要对权限、账号进行设置,如果使用Hadoop YARN作为集群管理器,则需要使用证书生成secret key登录,最后给当前系统设置默认的口令认证实例。

2.基于Akka的分布式消息系统ActorSystem
Scala认为Java线程通过共享数据以及通过锁来维护共享数据的一致性是糟糕的做法,容易引起锁的争用,降低并发程序的性能,甚至会引入死锁的问题。在Scala中只需要自定义类型继承Actor,并且提供act方法,就如同Java里实现Runnable接口,需要实现run方法一样。但是不能直接调用act方法,而是通过发送消息的方式(Scala发送消息是异步的)传递数据。
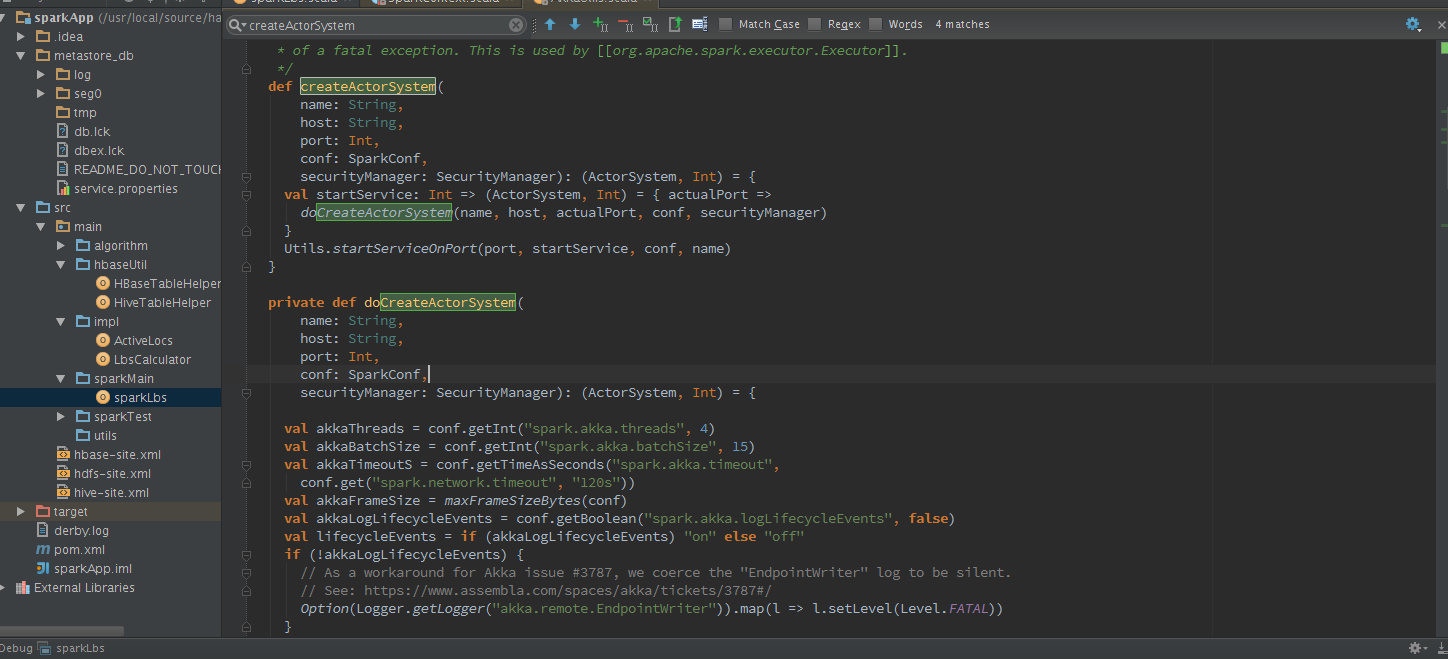
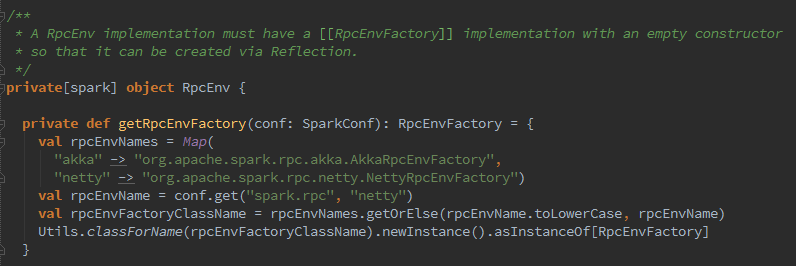
3.下来呢,该创建MapOutputTrackerMaster或MapOutputTrackerWorker,那么他俩是什么呢?map任务的状态正是由Executor向持有的MapOutputTracker-MasterActor发送消息,将map任务状态同步到mapOutputTracker的mapStatuses,Executor究竟是如何找到MapOutputTrackerMasterActor的?registerOrLookup方法通过调用AkkaUtils.makeDriverRef找到MapOutputTrackerMasterActor,利用ActorSystem提供的分布式消息机制实现的.
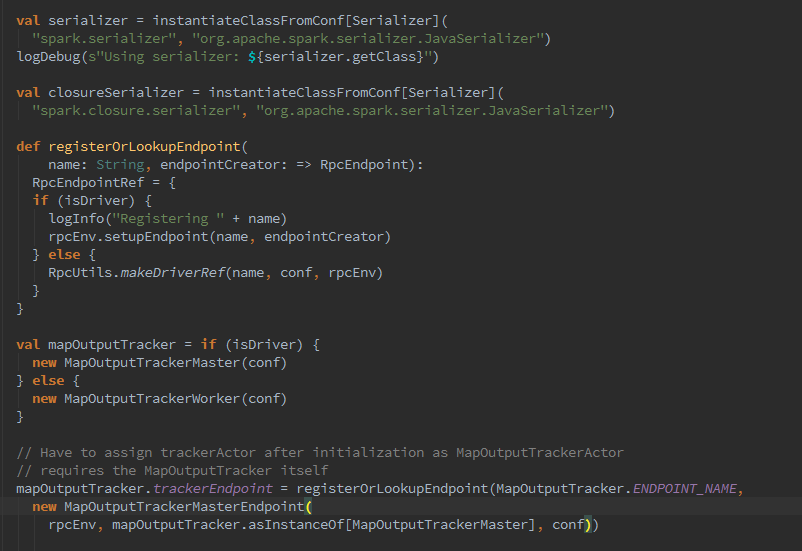
4.随之开始对ShuffleManager实例进行创建及加载。
ShuffleManager默认为通过反射方式生成的SortShuffleManager的实例,可以修改属性spark.shuffle.manager为hash来显式控制使用HashShuffleManager。这里再说明下,什么是shuffle?shuffle就是个混洗的过程,同一个作业会被划分为多个任务在多个节点上并行执行,reduce的输入可能存在于多个节点上,需要通过“洗牌”将所有reduce的输入汇总起来,这个过程就是shuffle。 那么spark是通过反射,来加载对应配置项的实体类:

ShuffleMemoryManager负责管理shuffle线程占有内存的分配与释放,并通过thread-Memory:mutable.HashMap[Long,Long]缓存每个线程的内存字节数。出,shuffle所有线程占用的最大内存的计算公式为:
Java运行时最大内存*Spark的shuffle最大内存占比*Spark的安全内存占比,可以配置属性spark.shuffle.memoryFraction修改Spark的shuffle最大内存占比,配置属性spark.shuffle.safetyFraction修改Spark的安全内存,如下代码:
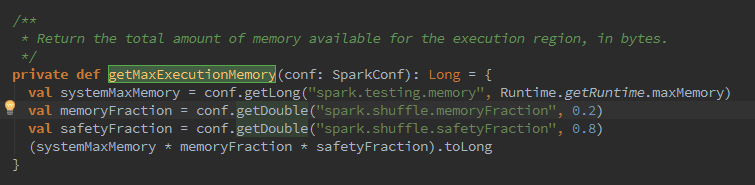
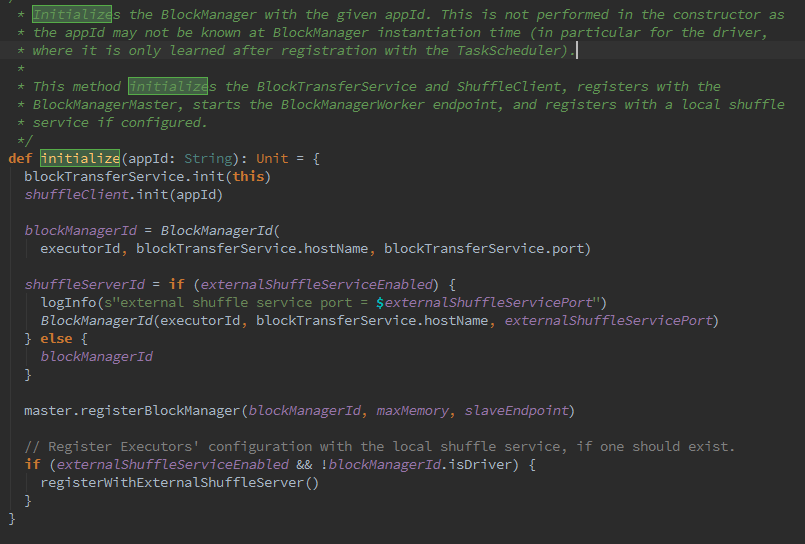
5.下来,创建BlockManager,BlockManager负责对Block的管理,只有在BlockManager的初始化方法initialize被调用后,它才是有效的。BlockManager作为存储系统的一部分。这么就继续深入,围绕BlockManager进行阅读。
查阅资料,BlockManager主要由以下部分组成:
·shuffle客户端ShuffleClient;
·BlockManagerMaster(对存在于所有Executor上的BlockManager统一管理);
·磁盘块管理器DiskBlockManager
·磁盘存储DiskStore;
·Tachyon存储TachyonStore;
·非广播Block清理器metadataCleaner和广播Block清理器broadcastCleaner;
·压缩算法实现
ShuffleServerId默认使用当前BlockManager的BlockManagerId。BlockManager的初始化:
那么BlockManager的实质运行机制如下图:
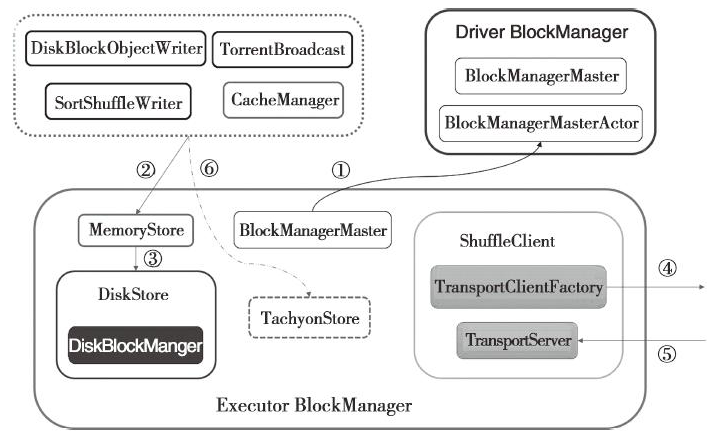
(1)表示Executor 的BlockManager中的BlockManagerMaster与Driver的BlockManagerActor进行消息通信,比如注册BlockManager、更新Block的信息、获取Block所在的BlockManager、删除Executor等。
(2)是shuffleRead与shufflewrite过程,也是BlockManager的读写操作。
(3)当内存不足时,写入磁盘,写入磁盘的数据也是由DiskBlockManager进行管理。
(4)通过访问远端节点的Executor的BlockManager中的TransportServer提供的RPC服务下载或者上传Block;
(5)远端节点的Executor的BlockManager访问本地Executor的BlockManager中的TransportServer提供的RPC服务下载或者上传Block;
(6)当存储体系选择Tachyon作为存储时,对于BlockManager的读写操作实际调用了TachyonStore的putBytes、putArray、putIterator、getBytes、getValues等。
以上过程就发生在我们提交jar包或启动thriftServer的时候,只要注意看日志就会发现。好了,今天就到这里,明天继续玩~

参考文献:《深入理解Spark核心思想与源码解析》
SparkConf加载与SparkContext创建(源码阅读一)的更多相关文章
- SparkConf加载与SparkContext创建(源码阅读四)
sparkContext创建还没完呢,紧接着前两天,我们继续探索..作死... 紧接着前几天我们继续SparkContext的创建: 接下来从这里我们可以看到,spark开始加载hadoop的配置信息 ...
- SparkConf加载与SparkContext创建(源码阅读二)
紧接着昨天,我们继续开搞了啊.. 1.下面,开始创建BroadcastManager,就是传说中的广播变量管理器.BroadcastManager用于将配置信息和序列化后的RDD.Job以及Shuff ...
- Android 图片加载框架Glide4.0源码完全解析(二)
写在之前 上一篇博文写的是Android 图片加载框架Glide4.0源码完全解析(一),主要分析了Glide4.0源码中的with方法和load方法,原本打算是一起发布的,但是由于into方法复杂性 ...
- Android必学-异步加载+Android自定义View源码【申明:来源于网络】
Android必学-异步加载+Android自定义View源码[申明:来源于网络] 异步加载地址:http://download.csdn.net/detail/u013792369/8867609 ...
- ArcGIS紧凑型切片读取与应用2-webgis动态加载紧凑型切片(附源码)
1.前言 上篇主要讲了一下紧凑型切片的的解析逻辑,这一篇主要讲一下使用openlayers动态加载紧凑型切片的web地图服务. 2.代码实现 上篇已经可以通过切片的x.y.z得对应的切片图片,现在使用 ...
- Android 图片加载框架Glide4.0源码完全解析(一)
写在之前 上一篇博文写的是Picasso基本使用和源码完全解析,Picasso的源码阅读起来还是很顺畅的,然后就想到Glide框架,网上大家也都推荐使用这个框架用来加载图片,正好我目前的写作目标也是分 ...
- Spring Boot JDBC:加载DataSource过程的源码分析及yml中DataSource的配置
装载至:https://www.cnblogs.com/storml/p/8611388.html Spring Boot实现了自动加载DataSource及相关配置.当然,使用时加上@EnableA ...
- 【Android初级】如何实现一个“模拟后台下载”的加载效果(附源码)
在Android里面,后台的任务下载功能是非常常用的,比如在APP Store里面下载应用,下载应用时,需要跟用户进行交互,告诉用户当前正在下载以及下载完成等. 今天我将通过使用Android的原生控 ...
- Spring 加载Controller逻辑的源码笔记
org.springframework.web.servlet.handler.AbstractHandlerMethodMapping#initHandlerMethods 进行加载Controll ...
随机推荐
- 第三个Sprint冲刺事后诸葛亮报告
用户反馈:还好吧. 用户数量:4 团队改进建议:思维局限太大,技术需要革新. 1.每个成员第一个sprint阶段有何需要改进? 成员 需要改进 邵家文 需要提高自己的工作效率,与创新能力,解决问题的能 ...
- 页码条--字符串拼接--重写HtmlHelper
public static HtmlString ShowPageNavigate(this HtmlHelper htmlHelper, int currentPage, int pageSize, ...
- 瀑布流布局(jq实现)
参考刘晓帆大神的瀑布流效果 自己也写了个 希望能给打算写这个效果的朋友一点点思路,也希望朋友们批评指正! html代码: <!DOCTYPE html> <html> < ...
- Chp11 11.7
<Java语言程序设计>P327 题目要求使用数组来模拟实现ArrayList的一些方法,并要求可以根据实际长度来实现数组自动增长,这里只贴出LikeArrayList.java 测试方法 ...
- MySQL集群在断网后再启动报"Unable to start missing node group"问题处理
总所周知,MySQL集群又名ndb cluster,而ndb就是network based database的简称,数据库节点之间依靠网络来通信和保证数据分块间的一致性.今天由于机房交换机损坏,导致集 ...
- php + sqlserver
Dbconn <?php class DbConn{ private $conn; private $rs; private function __construct(){ $serverNam ...
- html中的空格显示问题
像这种,从后台查询出来的数据中间有好几个空格,但在页面上显示的时候就只剩一个空格了,这种显示肯定是不合适的,相关的html代码如下: <c:forEach items="${list} ...
- 《Android深度探索HAL与驱动开发》第一章阅读心得
首先了解到Android系统架构是由四层构成:其中第一层是Linux内核,他的作用是负责Linux的驱动程序以及内存.进程.电源等管理操作:第二层是C/C++代码库,也就是Linux下.so的文件:第 ...
- uart启示2_异步操作的bug
发现代码中的隐藏bug真的是一件令人振奋的事情,当然也会疲倦那么一下午! 这个bug只有在一种在一个2604计数周期的一种情况下发生,所以即使是大量的仿真,未必也会发现的了,只有在以后的设计过程中,遇 ...
- 11个提问频率最高的PHP面试题
问题:请用最简单的语言告诉我PHP是什么? 回答:PHP全称:Hypertext Preprocessor,是一种用来开发动态网站的服务器脚本语言. 问题:什么是MVC? 回答:MVC由Model(模 ...