开源版本 hadoop-2.7.5 + apache-hive-2.1.1 + spark-2.3.0-bin-hadoop2.7整合使用
一,开源软件版本:
hadoop版本 : hadoop-2.7.5
hive版本 :apache-hive-2.1.1
spark版本: spark-2.3.0-bin-hadoop2.7
各个版本到官网下载就ok,注意的是版本之间的匹配
机器介绍,三台机器,第一台canal1为主节点+工作节点,另两台为工作节点:
10.40.20.42 canal1
10.40.20.43 canal2
10.40.20.44 canal3
二.搭建hadoop集群
1.配置环境变量 vim /etc/profile
export HADOOP_HOME=/opt/hadoop-2.7.5
export PATH=$PATH:$HADOOP_HOME/bin
export HIVE_HOME=/opt/apache-hive-1.2.2
export PATH=$PATH:$HIVE_HOME/bin
export JAVA_HOME=/usr/java/jdk1.8.0_121
export PATH=$PATH:$JAVA_HOME/bin
export SPARK_HOME=/opt/spark-2.3.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
2.修改hadoop配置文件
core-site.xml
---------------------------------------------------
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://canal1:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
yarn-site.xml
---------------------------------------------------------------
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>canal1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
hdfs-site.xml
-------------------------------------------------------------------------
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred-site.xml
----------------------------------------------------------------------
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置好以上文件后,复制到所有节点的配置文件,然后格式化namenode
hadoop namenode -format;
创建相应目录:
1020 hdfs dfs -mkdir -p /user/hive/tmp
1021 hdfs dfs -mkdir -p /user/hive/log
1022 hdfs dfs -chmod -R 777 /user/hive/tmp
1023 hdfs dfs -chmod -R 777 /user/hive/log
至此,可以启动hadoop集群了(非ha),到hadoop安装目录执行./start-all.sh,根据输出可以看到启动了哪些角色:
[root@canal1 sbin]# ./start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [canal1]
canal1: starting namenode, logging to /opt/hadoop-2.7.5/logs/hadoop-root-namenode-canal1.out
canal1: starting datanode, logging to /opt/hadoop-2.7.5/logs/hadoop-root-datanode-canal1.out
canal2: starting datanode, logging to /opt/hadoop-2.7.5/logs/hadoop-root-datanode-canal2.out
canal3: starting datanode, logging to /opt/hadoop-2.7.5/logs/hadoop-root-datanode-canal3.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /opt/hadoop-2.7.5/logs/hadoop-root-secondarynamenode-canal1.out
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop-2.7.5/logs/yarn-root-resourcemanager-canal1.out
canal1: starting nodemanager, logging to /opt/hadoop-2.7.5/logs/yarn-root-nodemanager-canal1.out
canal3: starting nodemanager, logging to /opt/hadoop-2.7.5/logs/yarn-root-nodemanager-canal3.out
canal2: starting nodemanager, logging to /opt/hadoop-2.7.5/logs/yarn-root-nodemanager-canal2.out
三.搭建spark集群
1,将安装包解压到各个节点,更改配置文件,主要有slaves文件和spark-env.sh文件
[root@canal3 conf]# cat slaves
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# A Spark Worker will be started on each of the machines listed below.
canal1
canal2
canal3
-----------------------------------------------------------------------------------------------------------------------
已经将export SPARK_CLASSPATH=$HIVE_HOME/lib/mysql-connector-java-5.1.46-bin.jar加在spark-env.sh中
2.启动集群,spark中分为两种角色,master和worker,进程名字也是这个:
到spark安装目录下的sbin目录,启动 ./start-all.sh ,然后jps(spark默认为是在执行这个命令的节点上启动一个master,
其余都是workder,要想在其他节点也启动master,比如做 spark master的ha,可以执行 ./start-master.sh),然后jps
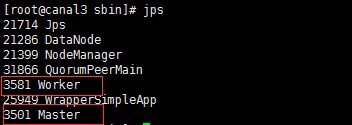
至此,spark集群也起来了;
四.安装hive,并整合到hadoop:
1.hive只要选一个节点,我这里是canal1节点,解压,安装,配置换机变量;
hive-site.xml
---------------------------------------------------------------------------------------------------
<configuration>
<property>
<name>hive.exec.scratchdir</name>
<value>hdfs://canal1:8020/user/hive/tmp</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>hdfs://canal1:8020/user/hive/warehouse</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>hdfs://canal1:8020/user/hive/log</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://canal2:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
</configuration>
------------------------------------------------------------------------------------------------------------------------------------------------------
编辑hive-env.sh,添加
export JAVA_HOME=/usr/java/jdk1.8.0_121 ##Java路径
export HADOOP_HOME=/opt/hadoop-2.7.5 ##Hadoop安装路径
export HIVE_HOME=/opt/apache-hive-2.1.1 ##Hive安装路径
2.添加hive连接mysql驱动:
下载 mysql-connector-java-5.1.46,解压,将mysql-connector-java-5.1.46-bin.jar复制到hive安装目录下的lib;
3.执行hive metastore database初始化:
schematool -initSchema -dbType mysql
4.启动hive
五.整合到spark
将hive-site.xml文件复制到所有spark安装目录下的conf文件夹
cp hive-site.xml /opt/spark-2.3.0-bin-hadoop2.7/conf/
scp hive-site.xml canal2:/opt/spark-2.3.0-bin-hadoop2.7/conf/
scp hive-site.xml canal3:/opt/spark-2.3.0-bin-hadoop2.7/conf/
至此,hadoop+hive+spark整合完毕
六,测试
在hive客户端创建表;
create table gong_from_hive(id int,name string,location string) row format delimited fields terminated by ",";
insert into gong_from_hive values(1,"gongxxxxxeng","shanghai");
转到sparlk下bin目录下,执行 ./spark-sql,show tables:
spark-sql> show tables;
2018-05-14 13:52:59 INFO HiveMetaStore:746 - 0: get_database: default
2018-05-14 13:52:59 INFO audit:371 - ugi=root ip=unknown-ip-addr cmd=get_database: default
2018-05-14 13:52:59 INFO HiveMetaStore:746 - 0: get_database: default
2018-05-14 13:52:59 INFO audit:371 - ugi=root ip=unknown-ip-addr cmd=get_database: default
2018-05-14 13:52:59 INFO HiveMetaStore:746 - 0: get_tables: db=default pat=*
2018-05-14 13:52:59 INFO audit:371 - ugi=root ip=unknown-ip-addr cmd=get_tables: db=default pat=*
default gong_from_hive false
default gong_from_spark false
Time taken: 0.071 seconds, Fetched 2 row(s)
2018-05-14 13:52:59 INFO SparkSQLCLIDriver:951 - Time taken: 0.071 seconds, Fetched 2 row(s)
可以看到在hive客户端创建的表,查询表:
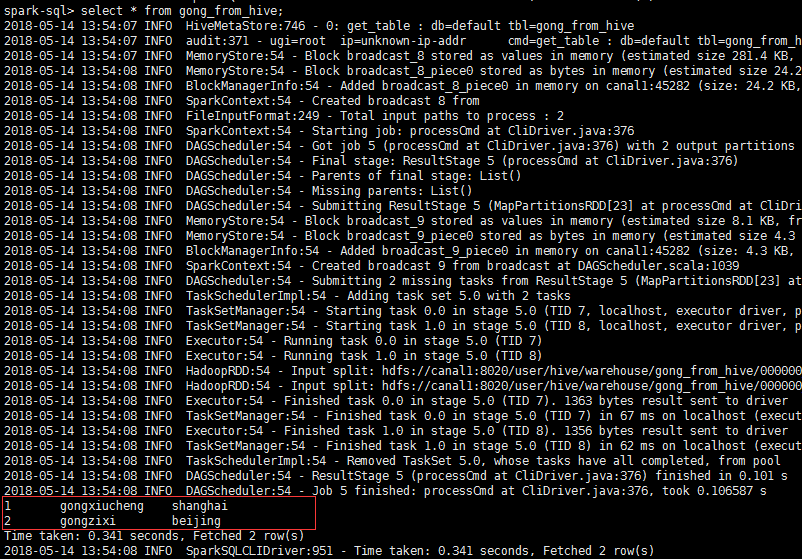
可以看到hive记录;
在spark sql客户端建表:
spark-sql> create table gong_from_spark(id int,name string,location string) row format delimited fields terminated by ",";
可以成功,测试插入也ok;
还可以去测试 spark-submit模式,spark-shell模式提交job运行情况;
七,报错问题总结:
1.java.net.ConnectException: Call From localhost/127.0.0.1 to localhost:8020 failed on connection
2.The specified datastore driver ("com.mysql.jdbc.Driver") was not found in the CLASSPATH 或
The specified datastore driver ("com.mysql.jdbc.Driver") was not found in the CLASSPATH. Please check your CLASSPATH specification, and the name of the driver.
找不到jdbc驱动;
3.hive默认数据库是derby,替换为mysql,解决只能一个客户端去连接的问题;
./spark-submit --master yarn --deploy-mode cluster --conf spark.driver.memory=4g --class org.apache.spark.examples.SparkPi --executor-cores 4 --queue myqueue ../examples/jars/spark-examples_2.11-2.3.0.jar 10
4.MetaException(message:Hive Schema version 2.1.0 does not match metastore's schema version 1.2.0 Metastore is not upgraded or corrupt
解决方案:
1.登陆mysql,修改hive metastore版本:
进行mysql:mysql -uroot -p (123456)
use hive;
select * from version;
update VERSION set SCHEMA_VERSION='2.1.0' where VER_ID=1;2.简单粗暴:在hvie-site.xml中关闭版本验证
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>开源版本 hadoop-2.7.5 + apache-hive-2.1.1 + spark-2.3.0-bin-hadoop2.7整合使用的更多相关文章
- 在Hadoop集群上的Hive配置
1. 系统环境Oracle VM VirtualBoxUbuntu 16.04Hadoop 2.7.4Java 1.8.0_111 hadoop集群master:192.168.19.128slave ...
- Hive JDBC:java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: root is not allowed to impersonate anonymous
今天使用JDBC来操作Hive时,首先启动了hive远程服务模式:hiveserver2 &(表示后台运行),然后到eclipse中运行程序时出现错误: java.sql.SQLExcepti ...
- 基于cdh5.10.x hadoop版本的apache源码编译安装spark
参考文档:http://spark.apache.org/docs/1.6.0/building-spark.html spark安装需要选择源码编译方式进行安装部署,cdh5.10.0提供默认的二进 ...
- Hive执行count函数失败,Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException)
Hive执行count函数失败 1.现象: 0: jdbc:hive2://192.168.137.12:10000> select count(*) from emp; INFO : Numb ...
- Hadoop第9周练习—Hive部署测试(含MySql部署)
1.1 2 :搭建Hive环境 内容 2.2 3 运行环境说明 1.1 硬软件环境 线程,主频2.2G,6G内存 l 虚拟软件:VMware® Workstation 9.0.0 build-8 ...
- Apache Hive 基本理论与安装指南
一.Hive的基本理论 Hive是在HDFS之上的架构,Hive中含有其自身的组件,解释器.编译器.执行器.优化器.解释器用于对脚本进行解释,编译器是对高级语言代码进行编译,执行器是对java代码的执 ...
- 【大数据系列】apache hive 官方文档翻译
GettingStarted 开始 Created by Confluence Administrator, last modified by Lefty Leverenz on Jun 15, 20 ...
- Apache Hive 安装文档
简介: Apache hive 是基于 Hadoop 的一个开源的数据仓库工具,可以将结构化的数据文件映射为一张数据库表, 并提供简单的sql查询功能,将 SQL 语句转换为 MapReduce 任务 ...
- 大数据Hadoop生态圈:Pig和Hive
前言 Pig最早是雅虎公司的一个基于Hadoop的并行处理架构,后来Yahoo将Pig捐献给Apache的一个项目,由Apache来负责维护,Pig是一个基于 Hadoop的大规模数据分析平台. Pi ...
随机推荐
- 为什么使用中间件下载时总是收到警告消息Object is in status Wait
在使用中间件从ERP下载对象时,正常情况下应该看到如下提示消息: 然而有时遇到的是黄色的警告消息:Object is in status Wait. 如何自己排错呢?在函数SMOF0_INIT_DNL ...
- A potentially dangerous Request.Form value was detected from the client的解决办法
网上找了这么多,这条最靠谱,记录下来,以备后用 <httpRuntime requestValidationMode="2.0"/> <pages validat ...
- Django:Django中的ORM
一.Django项目使用MySQL数据库 1,在Django项目的settings.py,文件中,配置数据库连接信息: DATABASES = { "default": { &qu ...
- hdu 6243,6247
题意:n只狗,n个笼子,每个笼子只能有一只,求不在自己笼子的狗的数量的期望. 分析:概率是相等的,可以直接用方案数代替,k 不在自己的笼子的方案数是 n!- (n-1)!,这样的k有n个,总的方案数n ...
- Sublime Text 3的安装,卸载,更新,激活
安装: 下载安装包:建议到官方网站下载,网址:http://www.sublimetext.com/3 . 卸载 在Finder中进入“/Users/用户名/Library/Application S ...
- Android学习笔记_64_手机安全卫士知识点归纳(4) 流量统计 Log管理 混淆打包 加入广告 自动化测试 bug管理
android 其实就是linux 上面包装了一个java的框架. linux 系统下 所有的硬件,设备(网卡,显卡等) 都是以文件的方式来表示. 文件里面包含的有很多设备的状态信息. 所有的流量相关 ...
- mui的事件实现(持续更新)
长按事件: mui('.mui-scroll').on('longtap', '.index-tab-item', function(e) { alert("长按生效") }); ...
- Java数据结构——二叉树 增加、删除、查询
//二叉树系统 public class BinarySystem { public static void main(String[] args) { BinaryDomain root = nul ...
- 菜鸟笔记 -- Chapter 6 面向对象
在Java语言中经常被提到的两个词汇是类与对象,实质上可以将类看作是对象的载体,它定义了对象所具有的功能.学习Java语言必须要掌握类与对象,这样可以从深层次去理解Java这种面向对象语言的开发理念, ...
- 什么是OR映射?
实体对象采用的是面向对象技术,它表达实体的关系是用关联.继承.而RDBMS 是遵循关系的范式理论构建的二维表,主要采用主键和外键的关联方式.因此,对象模型与数据库模型是不一致的,需要在两者之间进行变换 ...