deeplearning.ai课程学习(2)
第二周:神经网络的编程基础(Basics of Neural Network programming)
1、逻辑回归的代价函数(Logistic Regression Cost Function)
逻辑回归需要注意的两个点是,sigmoid函数和log损失函数。

sigmoid函数的函数表达式为
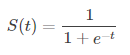
作为线性函数后的非线性转化,使得逻辑回归有别于硬分类的算法,例如SVM。逻辑回归对于分类的输出结果是[0,1]之间的一个值。
逻辑回归使用的损失函数(用于更新梯度)是 log损失函数,具体公式如下
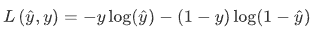
y^和y分别代表预测值和真实值。
对于log损失函数的解释,可以如下考虑:
当y=1时损失函数L= - log(y^),如果想要损失函数 L 尽可能得小,那么 y^ 就要尽可能大,因为sigmoid函数取值[0,1],所以 y^ 会无限接近于1。
当y=0时损失函数L = - log(1-y^),如果想要损失函数 L 尽可能得小,那么 y^ 就要尽可能小,因为sigmoid函数取值[0,1],所以 y^ 会无限接近于0。
2、使用计算图求导数(Derivatives with a Computation Graph)
通过计算图的形式理解前向传播和反向传播。
前向(正向)传播:
假设,我们需要去求解 J(a,b,c)=3(a+b*c),我们将它拆成 几个步骤,则如下图所示
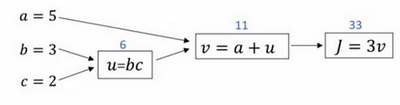
1、计算 u = b*c = 3 * 2 = 6
2、计算 v = a + u = 5 + 6 = 11
3、计算 J = 3 * v = 3 * 11 = 33
在这后面再加上,激活函数的转化,误差的计算就是完整的前向传播过程了。
反向传播:
所谓的反向传播,就是假设我们已经进行过了一次前向传播的过程,也就是得到了预测值与实际值之间的误差,
我们想通过这个误差来调整输入的值(a,b,c),使得他们在前向计算得到的预测值能够更加的接近实际值。

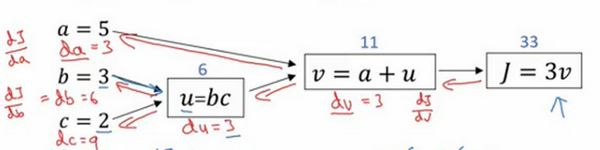
1、计算 dJ / dv = 3
2、计算 dv / da = 1以及 dv / du = 1
3、计算 du / db = c = 2 , du / dc = b = 3
至此,我们计算了图中所有可见项的导数,那么我们需要计算的 dJ / da,dJ / db,dJ / dc就可以通过链式求导法则得到。
4、dJ / da = (dJ / dv) * (dv / da) = 3 * 1 = 3 ; dJ / db = (dJ / dv) * (dv / du) * (du / db) = 3 * 1 * 2 = 2;
dJ / dc = (dJ / dv) * (dv / du) * (du / dc) = 3 * 1 * 3 = 3。
即如下图的过程。
在第二周,吴恩达首先介绍了逻辑回归算法(以及其损失函数),将逻辑回归算法看成一个神经网络,介绍了梯度下降和计算图,利用计算图更直观的介绍了反向传播的原理以及实现。
参考文献:
[1]. 课程视频:Coursera-deeplearning.ai / 网易云课堂
[2]. 深度学习笔记
deeplearning.ai课程学习(2)的更多相关文章
- deeplearning.ai课程学习(1)
本系列主要是我对吴恩达的deeplearning.ai课程的理解和记录,完整的课程笔记已经有很多了,因此只记录我认为重要的东西和自己的一些理解. 第一门课 神经网络和深度学习(Neural Netwo ...
- deeplearning.ai课程学习(3)
第三周:浅层神经网络(Shallow neural networks) 1.激活函数(Activation functions) sigmoid函数和tanh函数两者共同的缺点是,在z特别大或者特别小 ...
- deeplearning.ai课程学习(4)
第四周:深层神经网络(Deep Neural Networks) 1.深层神经网络(Deep L-layer neural network) 在打算使用深层神经网络之前,先去尝试逻辑回归,尝试一层然后 ...
- Deeplearning.ai课程笔记--汇总
从接触机器学习就了解到Andrew Ng的机器学习课程,后来发现又出来深度学习课程,就开始在网易云课堂上学习deeplearning.ai的课程,Andrew 的课真是的把深入浅出.当然学习这些课程还 ...
- Deeplearning.ai课程笔记-神经网络和深度学习
神经网络和深度学习这一块内容与机器学习课程里Week4+5内容差不多. 这篇笔记记录了Week4+5中没有的内容. 参考笔记:深度学习笔记 神经网络和深度学习 结构化数据:如数据库里的数据 非结构化数 ...
- Deeplearning.ai课程笔记-改善深层神经网络
目录 一. 改善过拟合问题 Bias/Variance 正则化Regularization 1. L2 regularization 2. Dropout正则化 其他方法 1. 数据变形 2. Ear ...
- 机器学习策略——DeepLearning.AI课程总结
一.什么是ML策略 假设你正在训练一个分类器,你的系统已经达到了90%准确率,但是对于你的应用程序来说还不够好,此时你有很多的想法去继续改善你的系统: 收集更多训练数据 训练集的多样性不够,收集更多的 ...
- Deeplearning.ai课程笔记-结构化机器学习项目
目录 一. 正交化 二. 指标 1. 单一数字评估指标 2. 优化指标.满足指标 三. 训练集.验证集.测试集 1. 数据集划分 2. 验证集.测试集分布 3. 验证集.测试集大小 四. 比较人类表现 ...
- Coursera深度学习(DeepLearning.ai)编程题&笔记
因为是Jupyter Notebook的形式,所以不方便在博客中展示,具体可在我的github上查看. 第一章 Neural Network & DeepLearning week2 Logi ...
随机推荐
- Mybatis中使用UpdateProvider注解实现根据主键批量更新
Mapper中这样写: @UpdateProvider(type = SjjcSqlProvider.class, method = "updateTaskStatusByCBh" ...
- Dockerfile中npm中Error: could not get uid/gid问题的解决方法
dockerfile 中 使用 npm 的时候报错: 解决办法:https://github.com/tootsuite/mastodon/issues/802
- 【基于不同设备厂商在处理vlan之间通信配置例子】
H3C: Dot1q子接口实现vlan之间的通信 一:根据项目需求搭建好拓扑图如下: 二:配置 HUAWEI: CISCO
- JDK7 新特性
JDK7新特性的目录导航: 二进制字面值 switch 语句支持 String try-with-resources catch 多个类型异常 字面值中使用下划线 类型推断 改进泛型类型可变参数 其它 ...
- PC时代 常用搜索引擎高级指令 勿忘
PC时代,高级指令辅助检索,高效输出既定的需求,被广泛运用于Search Engine. 布局search入口的平台,高级指令都不可或缺.现今,高级指令的高效性,仍然主要体现在搜索引擎检索过程中. i ...
- PHP实现SMTP邮件的发送实例
当你还在纠结php内置的mail()函数不能发送邮件时,那么你现在很幸运,此时的这篇文章可以帮助到你! php利用smtp类来发邮件真是屡试不爽,我用过很久了,基本上没出过问题.本博客后台,当博主回复 ...
- Hive优化之谓词下推
Hive优化之谓词下推 解释 Hive谓词下推(Predicate pushdown) 关系型数据库借鉴而来,关系型数据中谓词下推到外部数据库用以减少数据传输 基本思想:尽可能早的处理表达式 属于逻辑 ...
- python -pickle模块、re模块学习
pickel模块 import pickle #pickle可以将任何数据类型序列化,json只能列表字典字符串数字等简单的数据类型,复杂的不可以 #但是pickle只能在python中使用,json ...
- sqli-labs 1-20实验记录
1. less1 首先输入?id=1 查找是否有注入点. 输入单引号 回显报错 说明有注入漏洞 而且是数字型 输入 1’ or 1=1 order by 1 猜测列名# 这里发现#不能变成url编码 ...
- 学会了 python 的pip方法安装第三方库
超级开心啊!!!!!!!!!!!!! win10 打开cmd Installing with get-pip.py To install pip, securely download get-pip. ...