kmeans聚类中的坑 基于R shiny 可交互的展示
龙君蛋君
2015年5月24日
1.背景介绍
最近公司在用R 建模,老板要求用shiny 展示结果,建模的过程中用到诸如kmean聚类,时间序列分析等方法。由于之前看过一篇讨论kmenas聚类针对某一特定数据类型,聚类结果非常不靠谱的文章,于是这个周末突发奇想,用shiny可交互的展示kmeans聚类中的坑。。。这篇博文就当是记录学习shiny和加深对kmeans、层次聚类的理解吧。
2.知识引用与学习
2)Shiny Gallery-This gallery contains useful examples to learn from
3.代码与图形展示
一个完整的shiny app 包含两个.R文件,ui.R和server.R。园主大人的这篇文章Shiny的架构浅析解释的很详细,可帮助理解shiny。
part 1 : ui.R
library(shiny)
library(dplyr)
library(broom)
shinyUI(
pageWithSidebar(
# Application title
headerPanel("kmeans VS hclust"),
sidebarPanel(
numericInput('n', 'Number of obs', 500 ,min=200 ,max=1000),
selectInput("type", "Select a clust approach:",c("kmeans","hclust"),"kmeans") ),
mainPanel(plotOutput("plot"))
)
)
part 2 : server.R
library(shiny)
library(dplyr)
library(broom)
shinyServer(function(input, output,session) {
#----data 1 for kmeans clust----
set.seed(500)
selectedData <- reactive({ rbind(
data_frame(x = rnorm(input$n), y = rnorm(input$n)),
data_frame(r = rnorm(input$n, 5, .25), theta = runif(input$n, 0, 2 * pi),
x = r * cos(theta), y = r * sin(theta)) %>%
dplyr::select(x, y)
)
})
#----data2 for hclust use----
selectedData_clust <- reactive({
cbind(selectedData(),hclust_assignments=selectedData() %>% dist() %>% hclust(method = "single") %>% cutree(2) %>% factor()%>%as.data.frame()
)
}) #-----plot-----
output$plot <- renderPlot({ switch(input$type,
"kmeans" =( plot(selectedData(),
col = kmeans(selectedData(),2)$cluster,
pch = 20, cex = 1)
), "hclust" = (plot(selectedData_clust()[,1:2],
col = selectedData_clust()[,3],
pch = 20, cex = 1)
)
)
})
#----end---
})
先解释下,用k-means进行聚类,常常假定数据是球状的,code中生成的数据集是非球状的,以便证明kmeans针对这种非球状数据集,会给出坑爹的结果。参考大数据分析之——k-means聚类中的坑。
part 3 :看图,也就是shiny的展示。
图1-kmeans聚类:
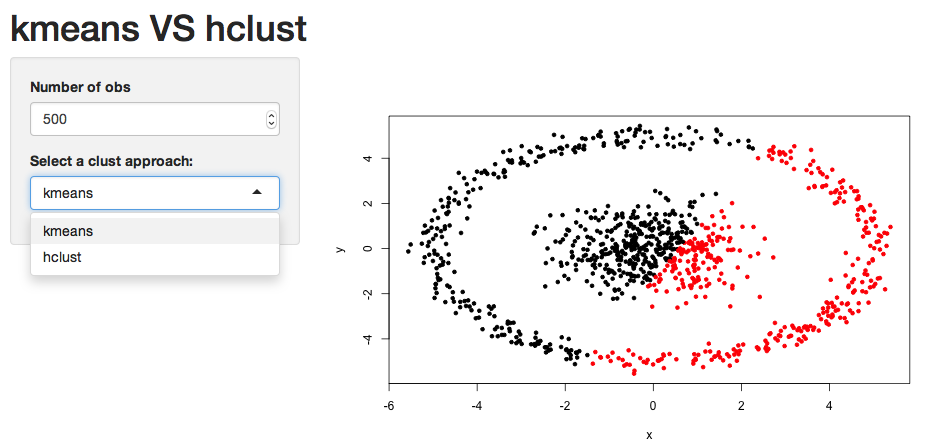
图2-hclust聚类(Hierarchical Clustering):

明显这种数据集,用层次聚类得出的结果才是正确的。
4.总结
1)要勤写博客,不能太懒!
2)Shiny Gallery-This gallery contains useful examples to learn from 这里有很多shiny 的例子,学习shiny的绝佳之地。
3)再推荐一个博客,r-bloggers 最前沿的R资讯分享,hadley都在上面写文章的哦!
4)Rstudio 真是个伟大的公司,开发了那么多好用,好玩的东西。
以上。
kmeans聚类中的坑 基于R shiny 可交互的展示的更多相关文章
- 用肘方法确定 kmeans 聚类中簇的最佳数量
说明: KMeans 聚类中的超参数是 K,需要我们指定.K 值一方面可以结合具体业务来确定,另一方面可以通过肘方法来估计.K 参数的最优解是以成本函数最小化为目标,成本函数为各个类畸变程度之和,每个 ...
- (数据科学学习手札12)K-means聚类实战(基于R)
上一篇我们详细介绍了普通的K-means聚类法在Python和R中各自的实现方法,本篇便以实际工作中遇到的数据集为例进行实战说明. 数据说明: 本次实战样本数据集来自浪潮集团提供的美团的商家信息,因涉 ...
- K-Means 聚类
机器学习中的算法主要分为两类,一类是监督学习,监督学习顾名思义就是在学习的过程中有人监督,即对于每一个训练样本,有对应的标记指明它的类型.如识别算法的训练集中猫的图片,在训练之前会人工打上标签,告诉电 ...
- 机器学习-K-means聚类及算法实现(基于R语言)
K-means聚类 将n个观测点,按一定标准(数据点的相似度),划归到k个聚类(用户划分.产品类别划分等)中. 重要概念:质心 K-means聚类要求的变量是数值变量,方便计算距离. 算法实现 R语言 ...
- k-means+python︱scikit-learn中的KMeans聚类实现( + MiniBatchKMeans)
来源:, init='k-means++', n_init=10, max_iter=300, tol=0.0001, precompute_distances='auto', verbose=0, ...
- 基于R实现k-means法与k-medoids法
k-means法与k-medoids法都是基于距离判别的聚类算法.本文将使用iris数据集,在R语言中实现k-means算法与k-medoids算法. k-means聚类 首先删去iris中的Spec ...
- (数据科学学习手札11)K-means聚类法的原理简介&Python与R实现
kmeans法(K均值法)是麦奎因提出的,这种算法的基本思想是将每一个样本分配给最靠近中心(均值)的类中,具体的算法至少包括以下三个步骤: 1.将所有的样品分成k个初始类: 2.通过欧氏距离将某个样品 ...
- (数据科学学习手札10)系统聚类实战(基于R)
上一篇我们较为系统地介绍了Python与R在系统聚类上的方法和不同,明白人都能看出来用R进行系统聚类比Python要方便不少,但是光介绍方法是没用的,要经过实战来强化学习的过程,本文就基于R对2016 ...
- 机器学习中K-means聚类算法原理及C语言实现
本人以前主要focus在传统音频的软件开发,接触到的算法主要是音频信号处理相关的,如各种编解码算法和回声消除算法等.最近切到语音识别上,接触到的算法就变成了各种机器学习算法,如GMM等.K-means ...
随机推荐
- 电量分析工具 Battery Historian 的配置及使用
1.Building from source code(通过各种配置后从源码构建) 官方流程看似很麻烦,但一上手,很快就搞定,让我情何以堪. ps:以下均是参考官方及网友做的 copy https:/ ...
- Ubuntu 16.04系统上NFS的安装与使用
摘要:本文介绍了NFS服务器的安装过程.配置文件和常用命令行工具,以及NFS客户端上如何安装常用工具,介绍如何挂载共享目录,并通过实验进行验证. 一.服务器端: 1.1安装NFS服务: #执行以下命令 ...
- Java基础14-多维数组
1.二位数组可以看成以数组为元素的数组 2.java中多维数组的声明和初始化一样,应该从高维到低维的顺序进行,例如 int[][] a=new int[3][]; a[0]=new int[2]; a ...
- python3.4 x86_64-linux-gnu-gcc Error
running install running build running build_py creating build creating build/lib.linux-x ...
- 我使用的brackets插件
livereload atom dark theme autoprefixer auto save files on window blur beautify brackets file icons ...
- FlashFXP出现“数据Socket错误,连接超时”解决方案
把FlashFXP选项中的"使用被动模式"的勾去掉就正常了. 或者在路由上映射服务端设定的被动模式所使用的所有端口,server-u就10个左右,微软的ftp是多少个,偶就不清楚了 ...
- DEDE SQL标签可以获取文档静态链接地址
在DedeCMS的系统里面,我可以通过由使用SQL语句来配合织梦标签进行更多的个性化调用.比如:推荐会员.推荐企业等.但是我们发现文档链接的底层模板地址的是动态的,那么我们要如何来进行转换,让他链接到 ...
- 【转】android ViewPager,ViewFlipper,ViewFlow实现左右滑动
转自:http://blog.csdn.net/zhouyuanjing/article/details/8290454 开篇 首页只是作为ViewPager,ViewFlipper,ViewFlow ...
- Git GUI基本操作
一.Git GUI基本操作 1.版本库初始化 gitpractise文件夹就变成了Git可以管理的仓库,目录下多了一个.git文件夹,此目录是Git用于管理版本库的,不要擅自改动里面的文件,这样会破坏 ...
- Ajax Jq Razor语句
1.JS刷新当前页面: window.location.reload(); 2.JSon成功后转向其他页面: window.location.href="要转向页面的地址(一般格式:/页面所 ...