HDFS 客户端读写操作详情
1. 写操作

- 客户端向namenode发起上传请求
- namenode检查datanode是否已经存有该文件,并且检查客户端的权限
- 确认可以上传后,根据文件块数返回datanode栈
注:namenode触发副本放置策略,如果客户端在集群内的某一台机器,那么副本第一块放置在该服务器上,然后再另外挑两台服务器;如果在集群外,namenode会根据策略先找一个机架选出一个datanode,然后再从另外的机架选出另外两个datanode,然后namenode会将选出的三个datanode按距离组建一个顺序,然后将顺序返回给客户端- 客户端pop()栈顶的第一个节点,建立socket连接,然后第一个节点与第二个节点,第二个节点与第三个节点...依次建立socket连接
- datanode反顺序依次应答,直到应答给客户端
注:如果有datanode没有应答,客户端重新向namenode请求- 客户端向datanode上传文件块
- 上传文件块后,各datanode会通过心跳将位置信息汇报给namenode
注:如果上传文件块时,某个datanode节点挂掉了,该节点的上节点直接连接该节点的下游节点继续传输,最终在第7步汇报后,namenode会发现副本数不足,触发datanode复制更多副本- 客户端重复上传操作,逐一将文件块上传,同时dataNode汇报块的位置信息,时间线重叠
- 所有块上传完毕后,namenode将所有信息存在元数据中,客户端关闭输出流
2. 读操作
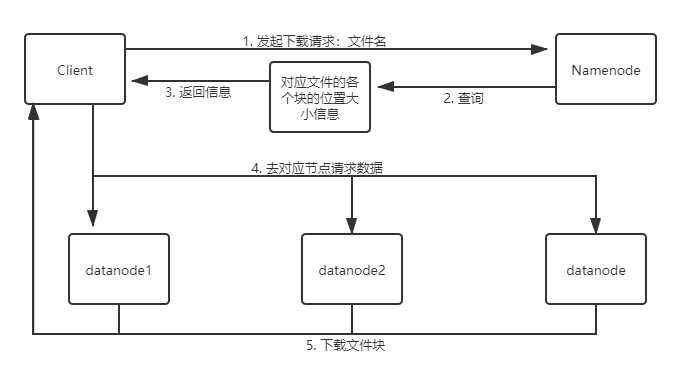
- 用户操作客户端查看文件,客户端带着文件名向namenode发起下载请求
- namenode在元数据中查找该文件对应各个块的大小位置信息,返回给客户端
- namenode向位置datanode节点发起下载请求
- datanode向客户端传输块数据
- 客户端下载完成所有块后会验证datanode中的MD5,保证块数据的完整性,最后关闭输入流
3. 读写过程中的数据单位
3.1 block
文件上传前需要分块,这个块就是block,一般为128MB。因为块太小:寻址时间占比过高。块太大:Map任务数太少,作业执行速度变慢。它是最大的一个单位。
3.2 packet
packet是第二大的单位,它是client端向datanode,或datanode的PipLine之间传数据的基本单位,默认64KB。
3.3 chunk
chunk是最小的单位,它是client向datanode,或datanode的PipLine之间进行数据校验的基本单位,默认512Byte,因为用作校验,故每个chunk需要带有4Byte的校验位。所以实际每个chunk写入packet的大小为516Byte。由此可见真实数据与校验值数据的比值约为128 : 1。(即64*1024 / 512)
HDFS 客户端读写操作详情的更多相关文章
- 大数据系列2:Hdfs的读写操作
在前文大数据系列1:一文初识Hdfs中,我们对Hdfs有了简单的认识. 在本文中,我们将会简单的介绍一下Hdfs文件的读写流程,为后续追踪读写流程的源码做准备. Hdfs 架构 首先来个Hdfs的架构 ...
- HDFS文件读写操作(基础基础超基础)
环境 OS: Ubuntu 16.04 64-Bit JDK: 1.7.0_80 64-Bit Hadoop: 2.6.5 原理 <权威指南>有两张图,下次po上来好好聊一下 实测 读操作 ...
- 大数据学习之HDFS基本API操作(下)06
hdfs文件流操作方法一: package it.dawn.HDFSPra; import java.io.BufferedReader; import java.io.FileInputStream ...
- Hadoop JAVA HDFS客户端操作
JAVA HDFS客户端操作 通过API操作HDFS org.apache.logging.log4jlog4j-core2.8.2org.apache.hadoophadoop-common${ha ...
- 客户端操作 2 HDFS的API操作 3 HDFS的I/O流操作
2 HDFS的API操作 2.1 HDFS文件上传(测试参数优先级) 1.编写源代码 // 文件上传 @Test public void testPut() throws Exception { Co ...
- ASP.NET MVC Filters 4种默认过滤器的使用【附示例】 数据库常见死锁原因及处理 .NET源码中的链表 多线程下C#如何保证线程安全? .net实现支付宝在线支付 彻头彻尾理解单例模式与多线程 App.Config详解及读写操作 判断客户端是iOS还是Android,判断是不是在微信浏览器打开
ASP.NET MVC Filters 4种默认过滤器的使用[附示例] 过滤器(Filters)的出现使得我们可以在ASP.NET MVC程序里更好的控制浏览器请求过来的URL,不是每个请求都会响 ...
- Hadoop之HDFS客户端操作
1. HDFS 客户端环境准备 1.1 windows 平台搭建 hadoop 2.8.5 2. 创建Maven工程 # pom.xml <dependencies> <depend ...
- HDFS 文件读写过程
HDFS 文件读写过程 HDFS 文件读取剖析 客户端通过调用FileSystem对象的open()来读取希望打开的文件.对于HDFS来说,这个对象是分布式文件系统的一个实例. Distributed ...
- 在windows下的hdfs客户端编写
在windows下的hdfs客户端编写 新建一个工程,右键 properties -> java build path -> libraries 和之前一样的操作,这次 new 一个 us ...
随机推荐
- UFT参数化
1.Resources-Record and Run Settings 2.打开程序进行录制操作 3.对Fly from和Fly to进行参数化 4.选中点击 5.输入名称,点击OK 6.在Data加 ...
- 如何使用iTunes制作iPhone铃声
新版iTunes(iTunes11)推出以后,界面上发生了一些改变,给人带来一种面貌一新的感觉,但也给许多朋友带来一些操作上的不太适应.下面就大家比较关心的iPhone的铃声制作方法,我在iTunes ...
- mysql配置白名单
1. 测试是否允许远程连接 $ telnet 192.168.1.8 3306 host 192.168.1.4 is not allowed to connect to this mysql ser ...
- deeplearning.ai 卷积神经网络 Week 3 目标检测
本周的主题是对象检测(object detection):不但需要检测出物体(image classification),还要能定位出在图片的具体位置(classification with loca ...
- [LC] 80. Remove Duplicates from Sorted Array II
Given a sorted array nums, remove the duplicates in-place such that duplicates appeared at most twic ...
- windows 不能在本地计算机启动apache2。有关更多信息,查阅系统事件日志。如果这是非Microsoft服务,请与服务厂商联系,并参考特定服务错误代码1
今天使用apache的时候又无法启动了,之前也遇到过,这次重点说这一次的情况,其他情况可以查看博主apache相关的其他博文:网上关于apache服务端的设置的很多,但是都不适合我的情况: 一般使用a ...
- motionbuilder安装未完成,某些产品无法安装的解决方法
motionbuilder提示安装未完成,某些产品无法安装该怎样解决呢?,一些朋友在win7或者win10系统下安装motionbuilder失败提示motionbuilder安装未完成,某些产品无法 ...
- redis的管理和监控工具treeNMS
TreeNMS可以帮助您搭建起一套用于redis的监控管理系统,也支持Memcached,让您可以通过web的方式对数据库进行管理,有了它您就可以展示NOSQL数据库.编辑修改内容,另外还配备了sql ...
- unittest(2)-加载用例的3种方式-输出测试报告
# 导入测试类执行测试用例 import unittest from day_20191202.class_unittest import TestMathMethod, TestMulti # fr ...
- 吴裕雄--天生自然python编程:实例(3)
# 返回 x 在 arr 中的索引,如果不存在返回 -1 def binarySearch (arr, l, r, x): # 基本判断 if r >= l: mid = int(l + (r ...