Python一键获取日漫Top100榜单电影信息
最近看到一个 UP 主做的视频,使用可视化动态图,把目前播放量最多的 UP 主一一列出来,结果第一名是哔哩哔哩番剧,第一名的播放量是第二名近 10 倍。
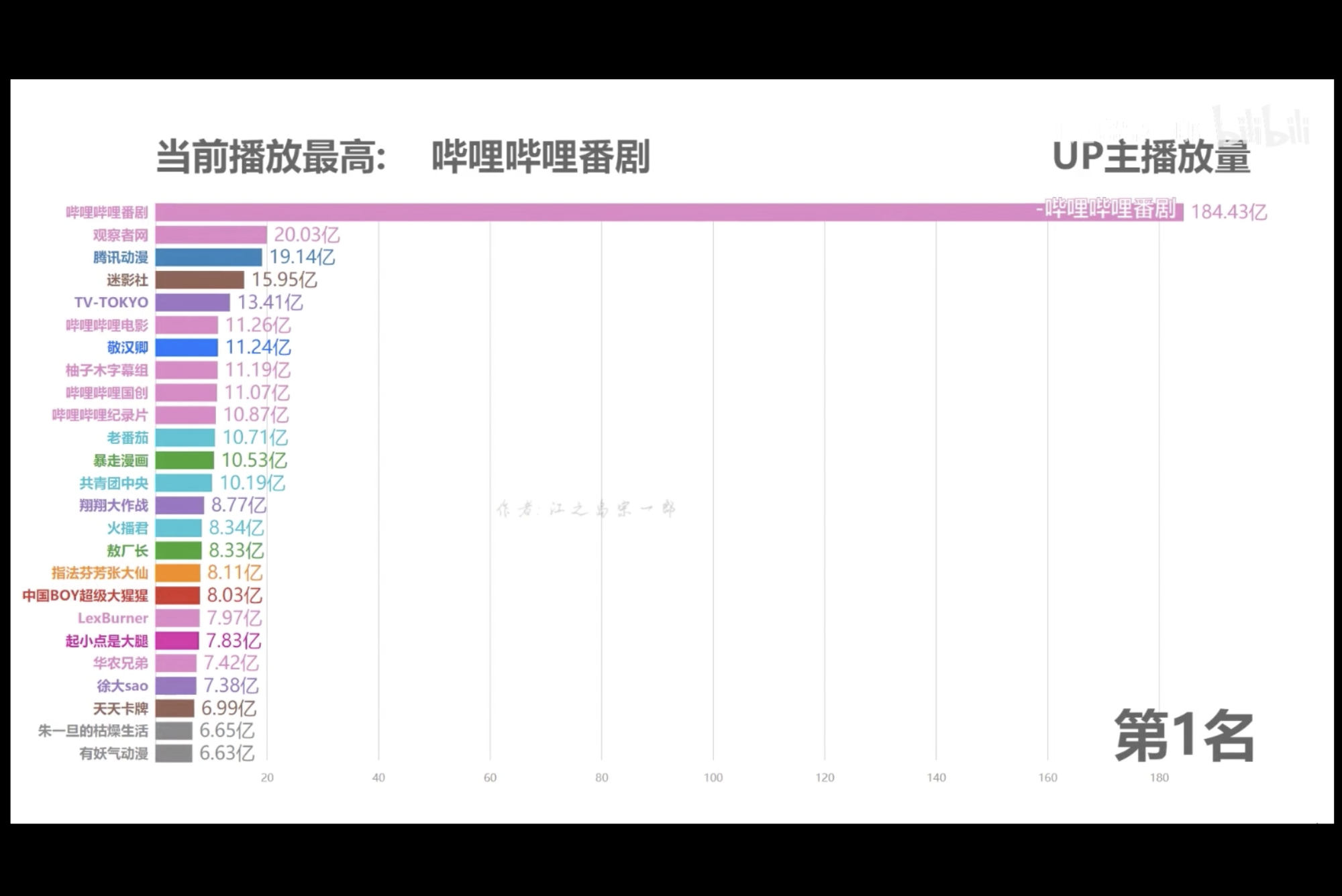
B站的番剧数量,也是相对其他平台比较多的,而且质量都还不错。说实话,刚开始用哔哩哔哩的时候,就是为了看番剧。作为一个喜欢看番剧的 pk 哥,我决定用爬虫爬取一下日本动漫电影 TOP100 都有哪些?网上看了一下,时光网正好有这个排行榜,而且信息相对来说比较全。
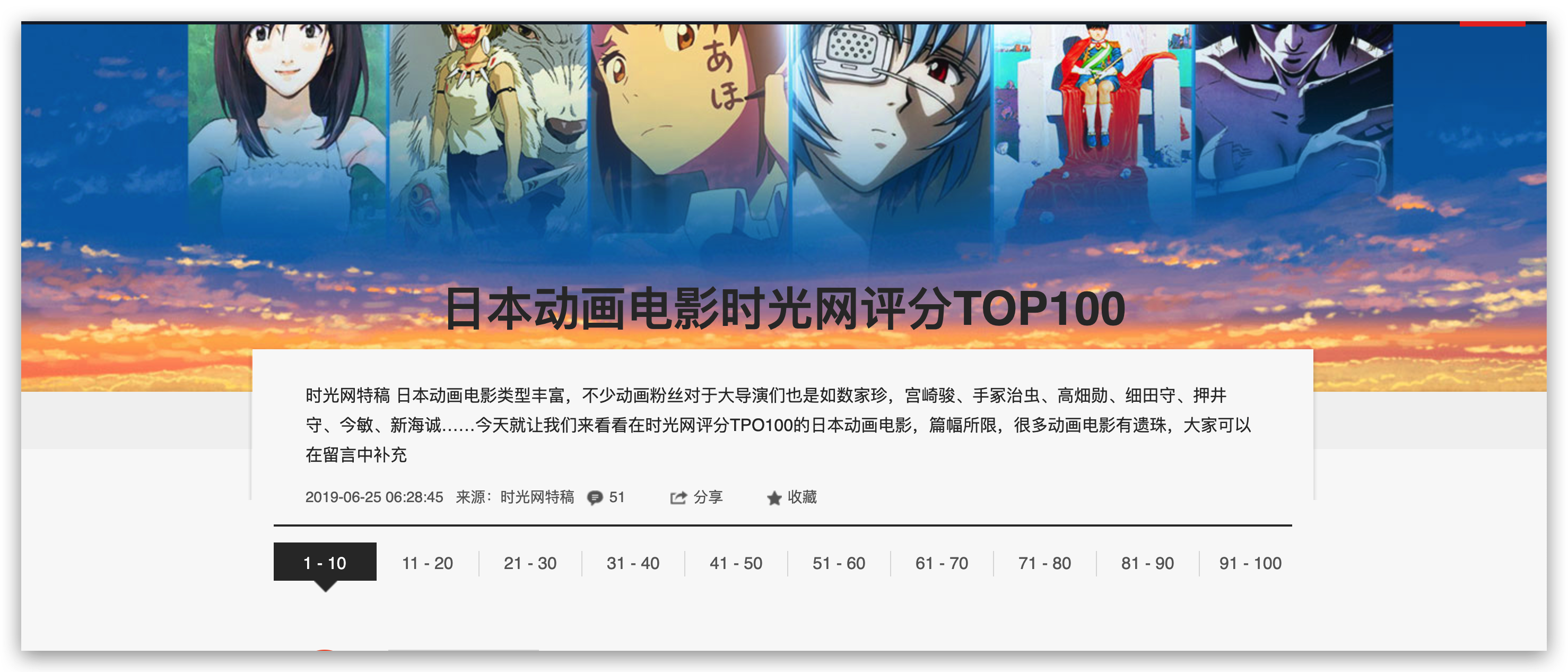
所以我决定用爬虫把这个榜单上 Top100 的所有电影信息全部保存为 csv 文件放在本地,看有没有之前我遗漏的经典动漫电影。
以下是保存的效果。保存的列包括电影名称、导演编剧、发行公司、更多片名、评分、首日票房、总票房。有些电影没有评分和票房信息的就直接显示为空。

获取电影ID信息
本次爬虫项目主要分为三个部分。第一部分我们要获取电影的 Id信息,因为我们需要保存的所有信息,都和这个有关。Id从哪里获取呢?我们打开这个榜单页面的源代码。源代码中我们可以看到,id都在链接后面。

为了缩小范围,我们发现这些链接都在 class=top_nlist 里面,我们用 beautifulsoup 库提取属性 class= top_nlist 所有的元素。然后用正则表达式,提取出每页的 id信息。
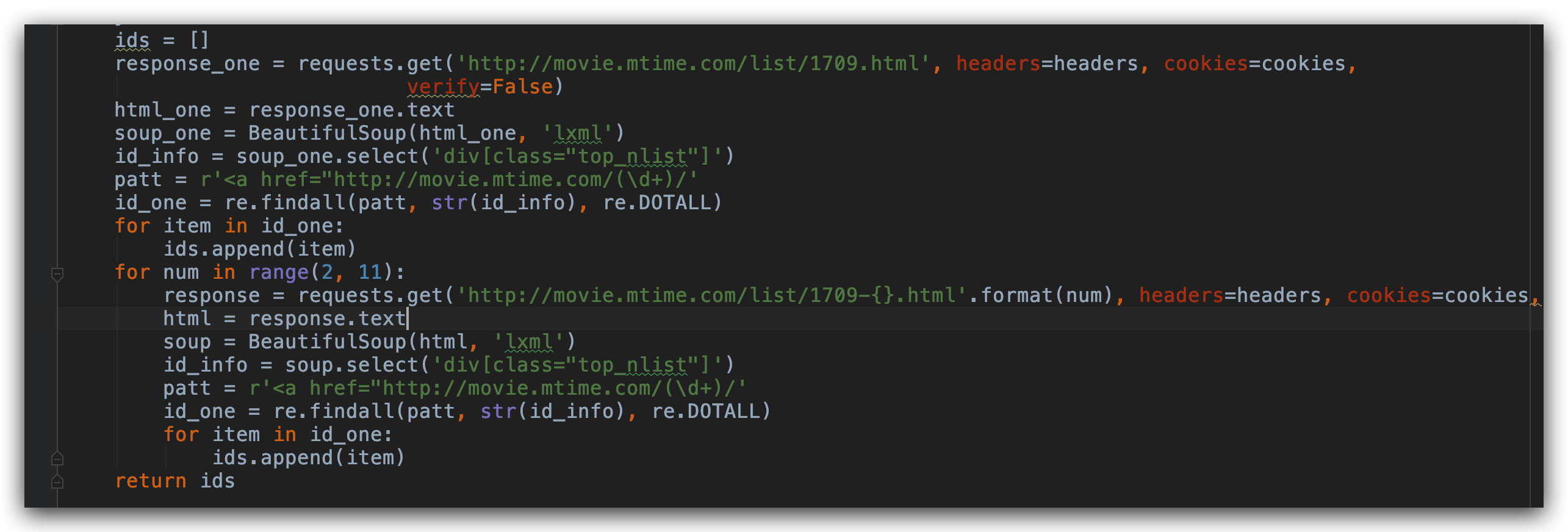
这里第 1 个页面需要特殊处理一下,因为第 2 个页面到第 10 个页面后面都是直接带的数字,第 1 个页面直接我在后面加 -1 的话会报 404,所以这个页面单独拿出来提取页面信息。然后再把 ID 信息全部加到空列表里面。
提取评分和票房信息
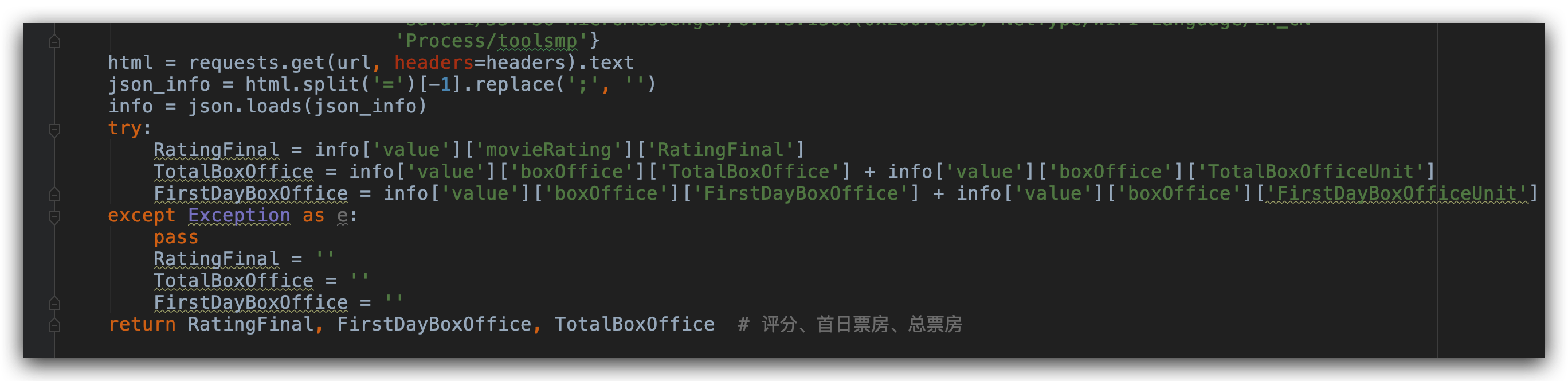
ID 信息获取了,接下来我们通过 ID 信息来获取电影的评分和票房信息。通过 F12 调试我们可以看到。评分和票房信息在 js 里面。

请求链接里变化的就是电影的 ID ,其他的保持不变就好。
我们对返回信息通过简单的处理转换为 Json 格式。之后我们就可以直接通过 key 值提取 value 值了。这里主要提取的信息有:评分、首日票房和总票房。
提取其他电影详细信息
接下来我们需要通过 ID 信息获取对应电影的名称和导演编剧等详细信息。这些信息在源代码中,可以直接通过正则表达式来提取。
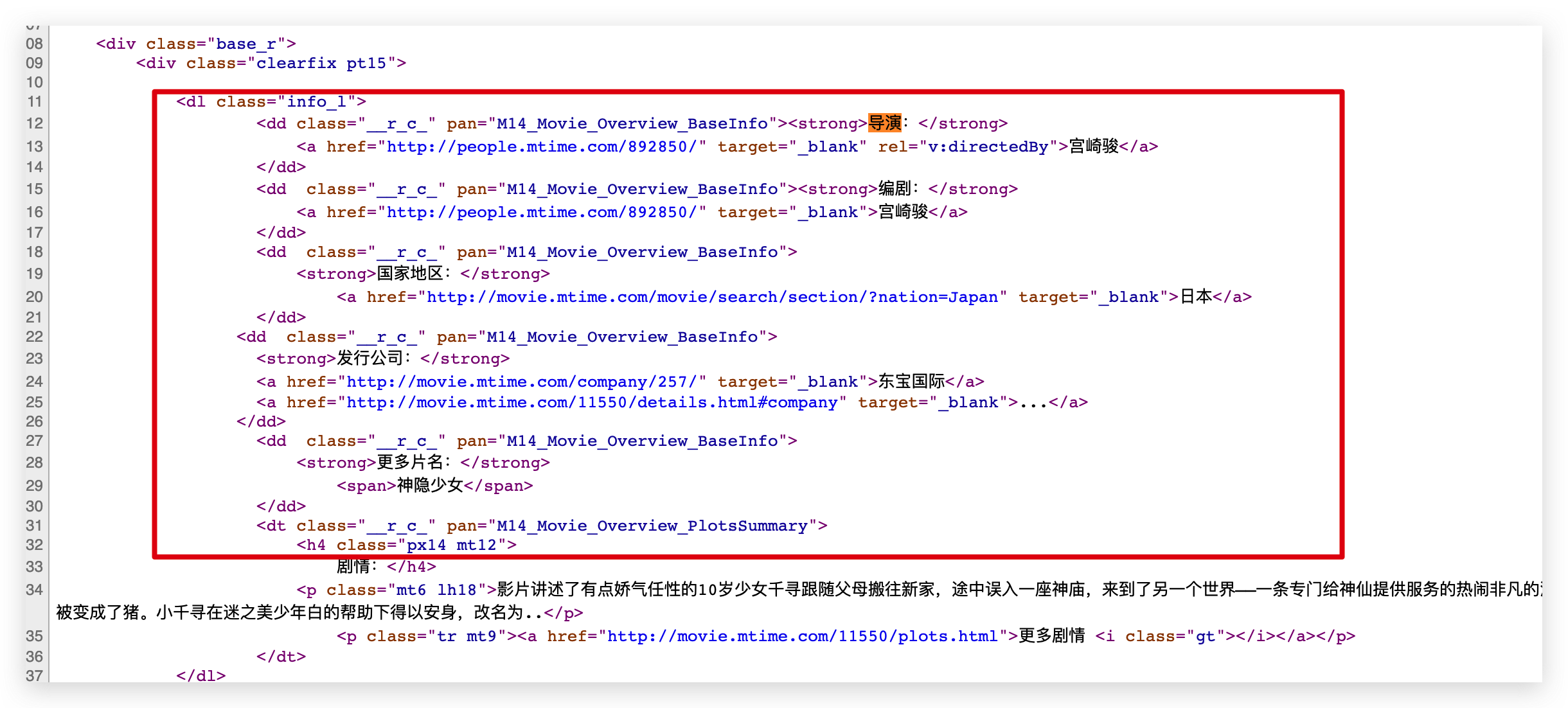
用正则表达式提取信息的前提是我们要找到信息的规律。这样通过正则表达式提取就又快又准。

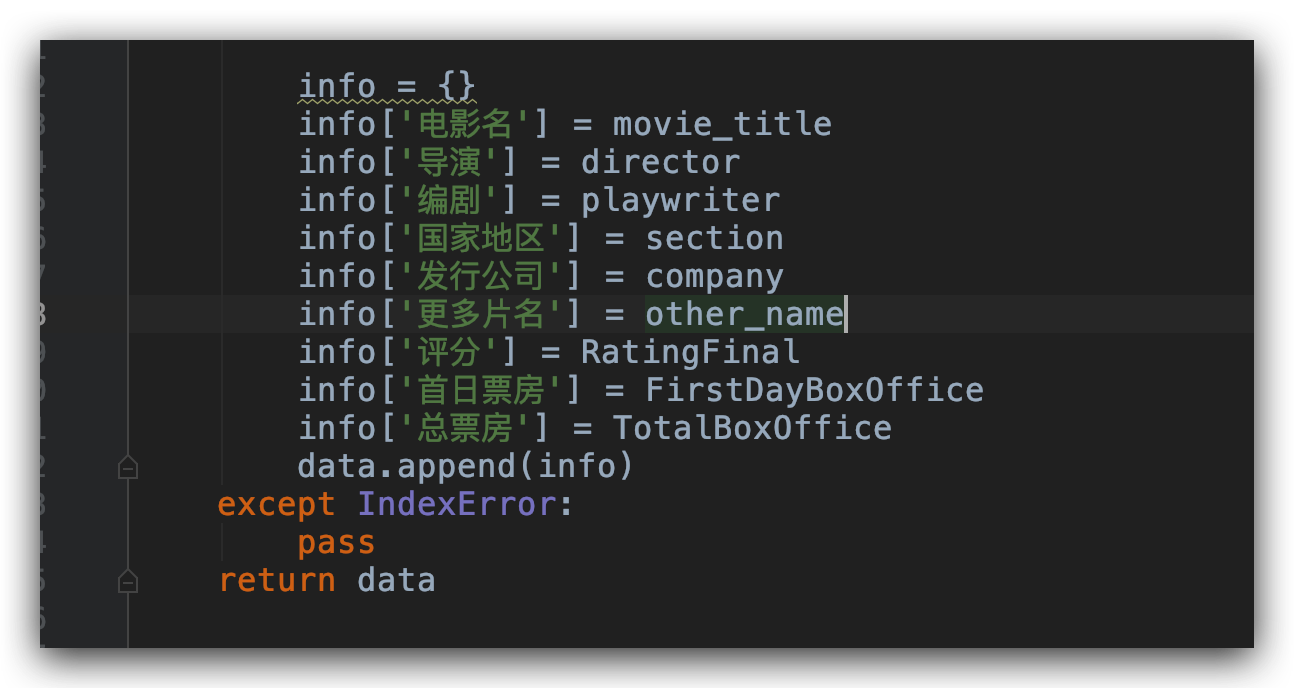
提取了这些信息之后,我们把它保存在 list 列表中,这样做的目的是为了后面我们保存为 csv 文件做准备。
保存为csv文件
每页的信息获取了之后,我们就可以把这些信息追加保存到 csv 文件中。每保存一部电影信息,保存下一部电影信息就进行追加保存。为了避免保存后的 csv 文件打开出现乱码,我们需要将编码形式设置为 encoding='utf-8' 格式。
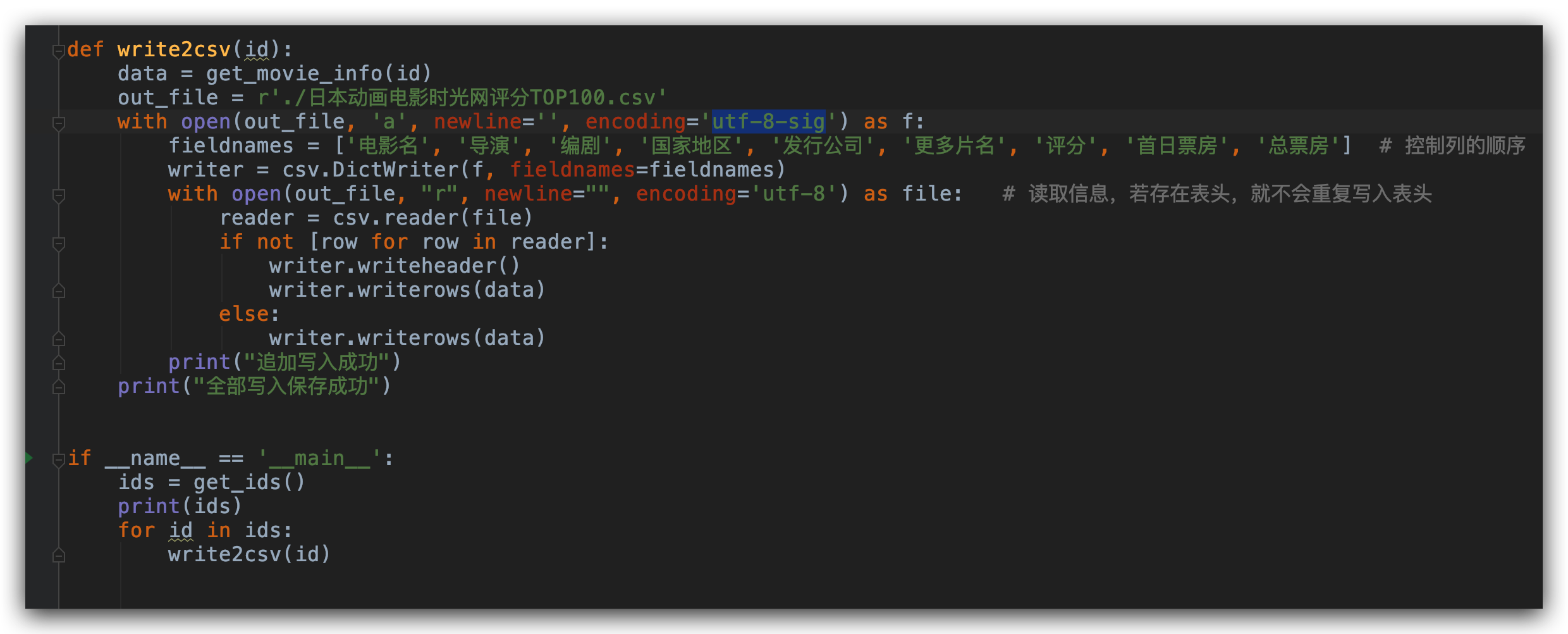
通过这三步,这个 Top100 排行榜中的所有动漫电影信息都全部保存在本地的 csv 文件中啊。那我们就可以更方便的浏览这些电影信息。这样我们就可以更好的追番了。本文所有的代码信息可在公众号「Python知识圈」后台回复「动漫电影」获取。
Python一键获取日漫Top100榜单电影信息的更多相关文章
- 微信小程序 TOP100 榜单
8 月 12 日,阿拉丁数据统计平台发布了国内第一份小程序 TOP100 榜单,摩拜单车成为全榜第一! 该榜单数据来源于阿拉丁小程序统计平台检测.合作.如有赞等,并经过企业电话调研和实地走访企业等校准 ...
- 2016中国银行Top100榜单发布 工行排首位
2016中国银行Top100榜单发布 工行排首位 2016-07-09 15:13:19 第一财经 2016年7月8日,中国银行业协会在京召开“<中国银行业发展报告(2016)>发布会 ...
- 使用requests爬取猫眼电影TOP100榜单
Requests是一个很方便的python网络编程库,用官方的话是"非转基因,可以安全食用".里面封装了很多的方法,避免了urllib/urllib2的繁琐. 这一节使用reque ...
- Python学习--猫眼电影TOP100榜单抓取
import requests import re import json import time def get_one_page(url): headers={'User-Agent':'Mozi ...
- python 爬取猫眼下的榜单(一)--单个页面
#!/usr/bin/env python # -*- coding: utf- -*- # @Author: Dang Kai # @Date: -- :: # @Last Modified tim ...
- 2019年微信小程序1月TOP100榜单
- python+requests+re匹配抓取猫眼上映电影信息
python+requests抓取猫眼中上映电影,re正则匹配获取对应电影的排名,图片地址,片名,主演及上映时间和评分 import requests import re, json def get_ ...
- Python爬虫项目--爬取猫眼电影Top100榜
本次抓取猫眼电影Top100榜所用到的知识点: 1. python requests库 2. 正则表达式 3. csv模块 4. 多进程 正文 目标站点分析 通过对目标站点的分析, 来确定网页结构, ...
- 重磅榜单!互联网金融Top100总估值超1.1万亿,27家独角兽上榜!
时隔4个月,爱分析的“中国互联网金融企业估值排行榜”更新了! 在这4个月当中,我们调研了数十位企业创始人.专业投资人以及资深行业专家,尤其针对金服集团.消费金融.财富管理.征信等领域进行了深入研究.因 ...
随机推荐
- C++--浅谈开发系统的经验
最近写了不少类了,从垃圾代码爬坑,虽然还是很垃圾,但是照葫芦画瓢,有几分神韵.在这里总结一下,写类的经验教训. 第一步 分析: 当拿到一个要求时,要先去考虑怎样一个类到底该实现什么样的功能,有什么样的 ...
- muduo网络库源码学习————线程类
muduo库里面的线程类是使用基于对象的编程思想,源码目录为muduo/base,如下所示: 线程类头文件: // Use of this source code is governed by a B ...
- Python爬虫(三)爬淘宝MM图片
直接上代码: # python2 # -*- coding: utf-8 -*- import urllib2 import re import string import os import shu ...
- Thinkphp 缓存RCE
5.0.0<=ThinkPHP5<=5.0.10 . 漏洞利用条件: 1.基于tp5开发的代码中使用了Cache::set 进行缓存 2.在利用版本范围内 3.runtime目录可以 ...
- Jetson AGX Xavier/Ubuntu更改pip3源
pip3换源: 修改~/.pip/pip.conf,如果没有这个文件,就创建一个. 内容如下: [global]index-url = https://pypi.tuna.tsinghua.edu.c ...
- js和jq的获取焦点失去焦点写法
- 李婷华 201771010113 《面向对象程序设计(java)》第一周学习总结
第一部分:课程准备部分 填写课程学习 平台注册账号, 平台名称 注册账号 博客园:www.cnblogs.com 薄荷蓝莓 程序设计评测:https://pintia.cn/ 1957877441@q ...
- 【Spark】部署流程的深度了解
文章目录 Spark核心组件 Driver Executor Spark通用运行流程图 Standalone模式运行机制 Client模式流程图 Cluster模式流程图 On-Yarn模式运行机制 ...
- Android广播机制(1)
目录 简介 发送广播和接收广播方式 广播类型 接收系统广播 动态注册监听网络变化 步骤 优化 静态注册实现开机启动 步骤 注意 简介 就是因为安卓中的每个应用程序都可以对自己感兴趣的广播进行注册,这样 ...
- 安装Kibana出现的问题
安装Kibana出现的问题 前言 该问题的出现是在安装配置完成之后,也就是说下载好了kibana的相关包,在启动过程中出现的错误,该错误是在centos6的机器上引发的,是因为系统中的GLIBC_2. ...