spark系列-4、spark序列化方案、GC对spark性能的影响
一、spark的序列化
1.1、官网解释
http://spark.apache.org/docs/2.1.1/tuning.html#data-serialization
序列化在任何分布式应用程序的性能中起着重要作用。将对象序列化或消耗大量字节的速度慢的格式将大大减慢计算速度。通常,这将是您应该优化Spark应用程序的第一件事。Spark旨在在便利性(允许您使用操作中的任何Java类型)和性能之间取得平衡。它提供了两个序列化库:
- Java序列化:默认情况下,Spark使用Java ObjectOutputStream框架序列化对象,并且可以与您创建的任何类一起使用java.io.Serializable。您还可以通过扩展来更紧密地控制序列化的性能 java.io.Externalizable。Java序列化是灵活的,但通常很慢,并导致许多类的大型序列化格式。
- Kryo序列化:Spark还可以使用Kryo库(版本2)更快地序列化对象。Kryo比Java序列化(通常高达10倍)显着更快,更紧凑,但不支持所有Serializable类型,并且需要您提前注册您将在程序中使用的类以获得最佳性能。
1.2、Serializable方案
- Serializable方案:你的对象必须继承Serializable接口,类中的属性如果有实例那也必须是继承Serializable 可序列化的。
- 无法序列化:用transient修饰的。java是在修饰属性的最前面使用transient关键字,scala是在修饰属性的最前面使用@transient
- transient的作用是在Serializable序列化的时候,声明某个属性不参与序列化,带来的问题就是如果声明了不参与序列化,那这个属性存储的数据也带不过去了。
1.3、kryo方案
能用于广播变量和shuffle数据传输时候的序列化,外部变量和算子中的代码必须用Serializable
- 设置spark的全序列化:conf.set("spark.serializer", classOf[KryoSerializer].getName)
- 这时spark的全局序列化工具就变成了KryoSerializer而不是默认的Serializable方案了
- 当不设置conf.set("spark.kryo.registrationRequired","true")时,spark的所有对象都默认使用KryoSerializer序列化
- 当设置了conf.set("spark.kryo.registrationRequired","true")时,spark中自定义的类想被KryoSerializer序列化的对象必须得进行注册。
val classes: Array[Class[_]] = Array[Class[_]](classOf[ORCUtil],classOf[StructObjectInspector],classOf[OrcStruct]) //classOf[OrcStruct] OrcStruct:注册的类
conf.set("spark.serializer", classOf[KryoSerializer].getName)
conf.set("spark.kryo.registrationRequired","true")
conf.registerKryoClasses(classes)
如果对象很大,则可能还需要增加
spark.kryoserializer.bufferconfig。该值必须足够大以容纳要序列化的最大对象。
二、GC对spark性能的影响
2.1、频繁GC的影响

2.2、task运行期间动态创建的对象使用的Jvm堆内存的情况
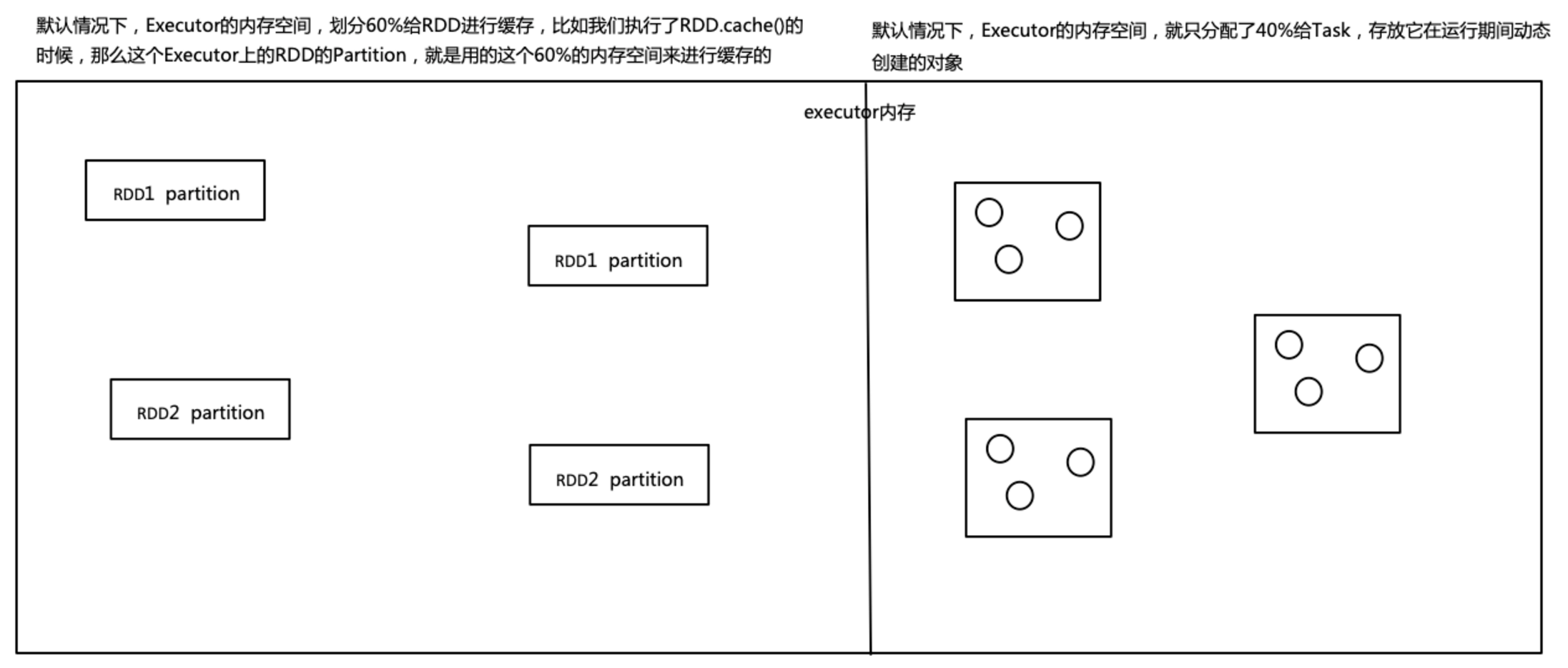
在默认情况下,就是分配给Task运行期间动态创建的内存空间有点小了,就很可能会发生full gc
因为内存小了就会导致,创建的对象很快就把内存空间填满了,然后就会GC了,就是JVM尝试找到那些不再被使用的对象,然后将其回收掉,清除出内存,腾出空间,给Task以后创建的新对象来使用和存放
所以说,如果给Task分配的内存空间小了,可能会频繁的发生GC,从而导致频繁的Task工作线程的停止,从而降低Spark应用程序的性能
解决方法:
- 可以通过调整比例,比如将RDD缓存空间占比调为40%,分配给Task的空间就变为60%,这样的话,至少可以降低GC发生的频率
- 还可以配合降低RDD的使用内存的空间,比如调节序列化的级别为MEMORY_DISK_SER或MEMORY_ONLY_SER,让RDD的partition序列化成一个字节的数组
- 还可以使用Kryo序列化类库,进行序列化,因为kryo序列化方法可以进一步的降低RDD的parition的内存占用量
2.3、JVM的minor gc(小级别)与full gc(大级别)原理
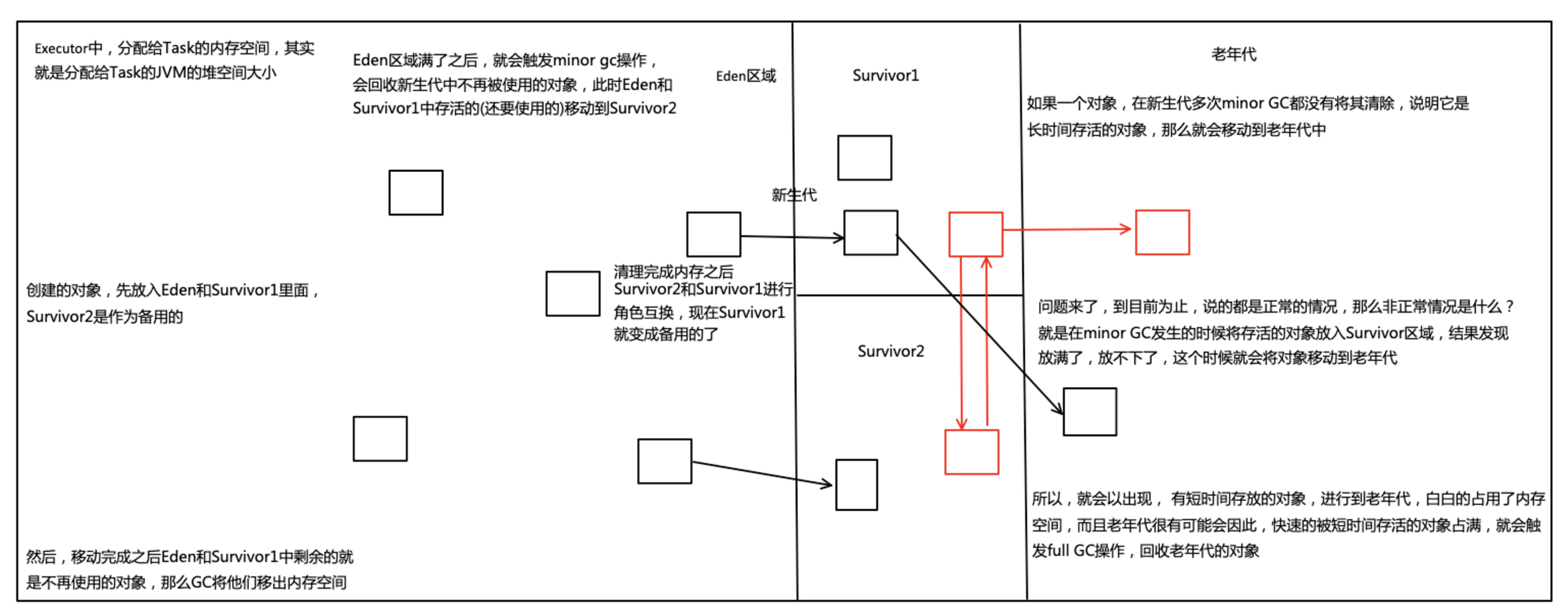
总结:
- 内存分为新生代和老年代,新生代分为Eden和Survivor(有2个)
- 创建的对象,首先放入Eden和Survivor1(可能是短时间)的
- 当Eden满了会启动minor gc,回收新生代中不再使用的对象,还要用的就放到Survivor2中
- 移完之后eden和Survivor1中省下的就是不再使用的对象,就将他们清理掉
- Survivor1和Survivor2交换角色。那就是原来的Survivor1成了备用的了,也就是原来的Survivor2
- 多次在Survivor区没有被清理掉的,说明它是长时间使用的,那么将它移动到老年代,到目前为止世界一切和平
- 由于对象越New越多,minor时发生备用的Survivor区满了,放不进去了,怎么办呢?这个本来可能是短时间生存的对象被放入老年代
- 短时间生存的对象,很可能快速的给老年代占满,白白的浪费老年代的空间,就会触发Full GC,回收老年代的对象
spark系列-4、spark序列化方案、GC对spark性能的影响的更多相关文章
- Spark 系列(七)—— 基于 ZooKeeper 搭建 Spark 高可用集群
一.集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop0 ...
- 在Spark中自定义Kryo序列化输入输出API(转)
原文链接:在Spark中自定义Kryo序列化输入输出API 在Spark中内置支持两种系列化格式:(1).Java serialization:(2).Kryo serialization.在默认情况 ...
- 几种Android数据序列化方案
一.引言 数据的序列化在Android开发中占据着重要的地位,无论是在进程间通信.本地数据存储又或者是网络数据传输都离不开序列化的支持.而针对不同场景选择合适的序列化方案对于应用的性能有着极大的影响. ...
- spark系列-7、spark调优
官网说明:http://spark.apache.org/docs/2.1.1/tuning.html#data-serialization 一.JVM调优 1.1.Java虚拟机垃圾回收调优的背景 ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- Spark 系列(十六)—— Spark Streaming 整合 Kafka
一.版本说明 Spark 针对 Kafka 的不同版本,提供了两套整合方案:spark-streaming-kafka-0-8 和 spark-streaming-kafka-0-10,其主要区别如下 ...
- Spark 系列(三)—— 弹性式数据集RDDs
一.RDD简介 RDD 全称为 Resilient Distributed Datasets,是 Spark 最基本的数据抽象,它是只读的.分区记录的集合,支持并行操作,可以由外部数据集或其他 RDD ...
- Spark入门实战系列--7.Spark Streaming(下)--实时流计算Spark Streaming实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .实例演示 1.1 流数据模拟器 1.1.1 流数据说明 在实例演示中模拟实际情况,需要源源 ...
- Spark系列之二——一个高效的分布式计算系统
1.什么是Spark? Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有H ...
随机推荐
- 家庭记账本app进度之ui相关概念控制ui界面与布局管理
ui就是用户界面设计的意思. 首先是view,view相当于窗户上的玻璃. 1.android:id属性.android:id="@+id/user".他的id是user前面的@+ ...
- websocket聊天室
目录 websocket方法总结 群聊功能 基于websocket聊天室(版本一) websocket方法总结 # 后端 3个 class ChatConsumer(WebsocketConsumer ...
- 一口气说出 4种 LBS “附近的人” 实现方式,面试官笑了
引言 昨天一位公众号粉丝和我讨论了一道面试题,个人觉得比较有意义,这里整理了一下分享给大家,愿小伙伴们面试路上少踩坑.面试题目比较简单:"让你实现一个附近的人功能,你有什么方案?" ...
- 小猪佩奇C代码实现
// ASCII Peppa Pig by Milo Yip #include <stdio.h> #include <math.h> #include <stdlib. ...
- public、private、protected继承区别
- Netty:ChannelFuture
上一篇我们完成了对Channel的学习,这一篇让我们来学习一下ChannelFuture. ChannelFuture的简介 ChannelFuture是Channel异步IO操作的结果. Netty ...
- Netperf网络性能测试工具详解教程
本文下载链接: [学习笔记]Netperf网络性能测试工具.pdf 一.Netperf工具简介 1.什么是Netperf ? (1)Netperf是由惠普公司开发的一种网络性能测量工具,主要针对基于T ...
- 【转】解决存储过程执行快,但C#程序调用执行慢的问题
这两天遇到一个问题令人比较郁闷,一个大概120行左右的存储过程在SQL Server2012的查询分析器里面执行,速度非常理想,1秒不到,即可筛选抓取到大概500条数据记录.但在C#程序代码里调用,就 ...
- c++ string类的一些使用
初始化: string类的初始化是不可以用字符进行的,如; string str='c'; string str('c');必须传递字符串字面量作为参数:string本身是用模板类进行实例化的类. s ...
- Daily Scrum 12/23/2015
Process: Zhaoyang: Compile the Caffe IOS version and make it run in the IOS9. Yandong: Finish the Az ...