Spark 系列(七)—— 基于 ZooKeeper 搭建 Spark 高可用集群
一、集群规划
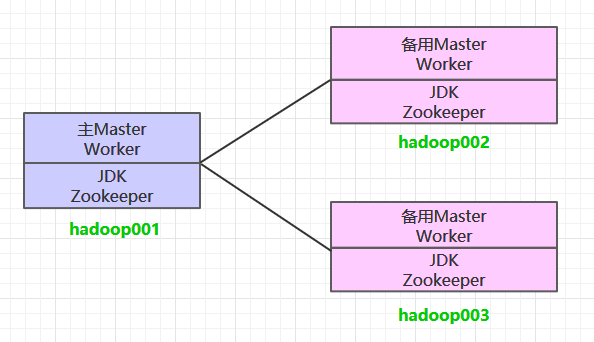
这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务。同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop002 和 hadoop003 上分别部署备用的 Master 服务,Master 服务由 Zookeeper 集群进行协调管理,如果主 Master 不可用,则备用 Master 会成为新的主 Master。
二、前置条件
搭建 Spark 集群前,需要保证 JDK 环境、Zookeeper 集群和 Hadoop 集群已经搭建,相关步骤可以参阅:
三、Spark集群搭建
3.1 下载解压
下载所需版本的 Spark,官网下载地址:http://spark.apache.org/downloads.html
下载后进行解压:
# tar -zxvf spark-2.2.3-bin-hadoop2.6.tgz3.2 配置环境变量
# vim /etc/profile添加环境变量:
export SPARK_HOME=/usr/app/spark-2.2.3-bin-hadoop2.6
export PATH=${SPARK_HOME}/bin:$PATH使得配置的环境变量立即生效:
# source /etc/profile3.3 集群配置
进入 ${SPARK_HOME}/conf 目录,拷贝配置样本进行修改:
1. spark-env.sh
cp spark-env.sh.template spark-env.sh# 配置JDK安装位置
JAVA_HOME=/usr/java/jdk1.8.0_201
# 配置hadoop配置文件的位置
HADOOP_CONF_DIR=/usr/app/hadoop-2.6.0-cdh5.15.2/etc/hadoop
# 配置zookeeper地址
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop001:2181,hadoop002:2181,hadoop003:2181 -Dspark.deploy.zookeeper.dir=/spark"2. slaves
cp slaves.template slaves配置所有 Woker 节点的位置:
hadoop001
hadoop002
hadoop0033.4 安装包分发
将 Spark 的安装包分发到其他服务器,分发后建议在这两台服务器上也配置一下 Spark 的环境变量。
scp -r /usr/app/spark-2.4.0-bin-hadoop2.6/ hadoop002:usr/app/
scp -r /usr/app/spark-2.4.0-bin-hadoop2.6/ hadoop003:usr/app/四、启动集群
4.1 启动ZooKeeper集群
分别到三台服务器上启动 ZooKeeper 服务:
zkServer.sh start4.2 启动Hadoop集群
# 启动dfs服务
start-dfs.sh
# 启动yarn服务
start-yarn.sh4.3 启动Spark集群
进入 hadoop001 的 ${SPARK_HOME}/sbin 目录下,执行下面命令启动集群。执行命令后,会在 hadoop001 上启动 Maser 服务,会在 slaves 配置文件中配置的所有节点上启动 Worker 服务。
start-all.sh分别在 hadoop002 和 hadoop003 上执行下面的命令,启动备用的 Master 服务:
# ${SPARK_HOME}/sbin 下执行
start-master.sh4.4 查看服务
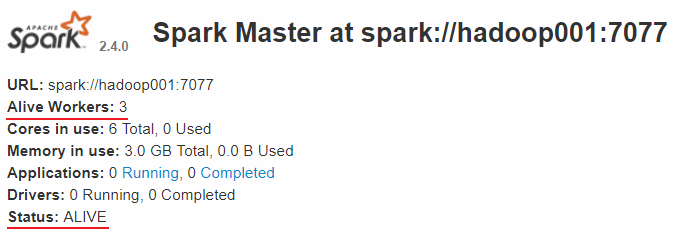
查看 Spark 的 Web-UI 页面,端口为 8080。此时可以看到 hadoop001 上的 Master 节点处于 ALIVE 状态,并有 3 个可用的 Worker 节点。
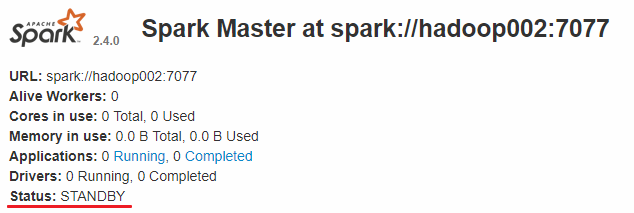
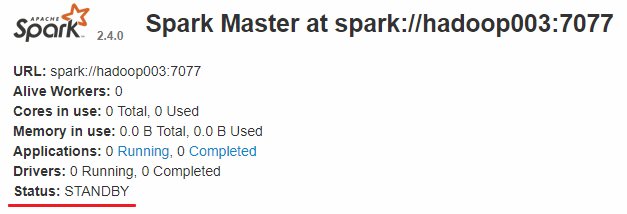
而 hadoop002 和 hadoop003 上的 Master 节点均处于 STANDBY 状态,没有可用的 Worker 节点。
五、验证集群高可用
此时可以使用 kill 命令杀死 hadoop001 上的 Master 进程,此时备用 Master 会中会有一个再次成为 主 Master,我这里是 hadoop002,可以看到 hadoop2 上的 Master 经过 RECOVERING 后成为了新的主 Master,并且获得了全部可以用的 Workers。
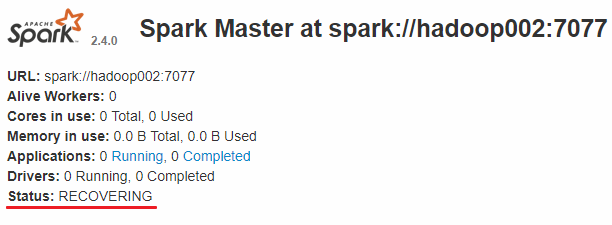
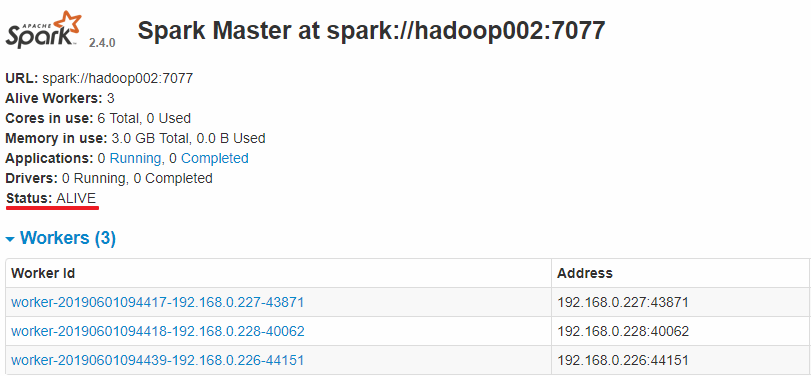
Hadoop002 上的 Master 成为主 Master,并获得了全部可以用的 Workers。
此时如果你再在 hadoop001 上使用 start-master.sh 启动 Master 服务,那么其会作为备用 Master 存在。
六、提交作业
和单机环境下的提交到 Yarn 上的命令完全一致,这里以 Spark 内置的计算 Pi 的样例程序为例,提交命令如下:
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--executor-memory 1G \
--num-executors 10 \
/usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar \
100更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
Spark 系列(七)—— 基于 ZooKeeper 搭建 Spark 高可用集群的更多相关文章
- Hadoop 系列(八)—— 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- Kafka 系列(二)—— 基于 ZooKeeper 搭建 Kafka 高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本 Zooke ...
- 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 二.集群规划 三.前置条件 四.集群配置 五.启动集群 六.查看集群 七.集群的二次启动 一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS ...
- Hadoop 学习之路(八)—— 基于ZooKeeper搭建Hadoop高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- Kafka —— 基于 ZooKeeper 搭建 Kafka 高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本Zookeep ...
- Kafka 学习之路(二)—— 基于ZooKeeper搭建Kafka高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本Zookeep ...
- 入门大数据---基于Zookeeper搭建Kafka高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本 Zooke ...
- 基于keepalived搭建MySQL高可用集群
MySQL的高可用方案一般有如下几种: keepalived+双主,MHA,MMM,Heartbeat+DRBD,PXC,Galera Cluster 比较常用的是keepalived+双主,MHA和 ...
- 基于Docker-compose搭建Redis高可用集群-哨兵模式(Redis-Sentinel)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_110 我们知道,Redis的集群方案大致有三种:1)redis cluster集群方案:2)master/slave主从方案:3) ...
- 基于docker实现redis高可用集群
基于docker实现redis高可用集群 yls 2019-9-20 简介 基于docker和docker-compose 使用redis集群和sentinel集群,达到redis高可用,为缓存做铺垫 ...
随机推荐
- BZOJ 3990 排序
[题目描述]: 小A有一个1~2N的排列A[1..2N],他希望将数组A从小到大排序.小A可以执行的操作有N种,每种操作最多可以执行一次.对于所有的i(1<=i<=N),第i种操作为:将序 ...
- Codeforces 730J:Bottles(背包dp)
http://codeforces.com/problemset/problem/730/J 题意:有n个瓶子,每个瓶子有一个当前里面的水量,还有一个瓶子容量,问要把所有的当前水量放到尽量少的瓶子里至 ...
- .Net 通过设置Access-Control-Allow-Origin来实现跨域访问
目录 # 前言 # 为每个API接口单独添加响应头 1.针对 ASP.NET MVC 项目的Controllers 2.针对 ASP.NET Web API项目的Controllers 3.针对ASP ...
- 实现markdown功能
前言 由于个人一直想弄一个博客网站,所以写博客的功能也就必须存在啦,而之前想过用富文本编辑器来实现的.但是接触了markdown后,发现真的是太好玩了,而且使用markdown的话可以在博客园.CSD ...
- ServiceFabric极简文档-2 部署环境搭建-配置文件
类型:ClusterConfig.Unsecure.MultiMachine 说明:至少3台机子 { "name": "SampleCluster", &quo ...
- [记录]python异步编程async/await实现
from selectors import DefaultSelector, EVENT_READ, EVENT_WRITE import socket from types import corou ...
- sudo ln -sf libhiredis.so.0.10 libhiredis.so.0
which ldconfig sudo ln -sf libhiredis.so.0.10 libhiredis.so.0
- [leetcode] 20. Valid Parentheses (easy)
原题链接 匹配括号 思路: 用栈,遍历过程中,匹配的成对出栈:结束后,栈空则对,栈非空则错. Runtime: 4 ms, faster than 99.94% of Java class Solut ...
- Surging实践经验
背景 在去年9月份的时候,我入职一家做航空软件产品的公司.当时公司部门领导决定构建一个技术平台(或称为技术中台),通过该技术平台进而孵化各个业务系统.说白了就是需要通过一个分布式框架或是微服务框架提高 ...
- LiteDB源码解析系列(3)索引原理详解
在这一章,我们将了解LiteDB里面几个基本数据结构包括索引结构和数据块结构,我也会试着说明前辈数据之巅在博客中遇到的问题,最后对比mysql进一步深入了解LiteDB的索引原理. 1.LiteDB的 ...