python2下经典爬虫(第一卷)
python2.7的爬虫个人认为比较经典在此我将会用书中的网站http://example.webscraping.com作为案例
爬虫第一步:进行背景调研
了解网站的结构资源在网站的robots.txt和Sitemap文件上,下面了解一下robot.txt文件:
robots.txt是一个纯文本文件,在这个文件中网站管理者可以声明该网站中不想被搜索引擎访问的部分,或者指定搜索引擎只收录指定的内容
当一个搜索引擎(又称搜索机器人或蜘蛛程序)访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,那么搜索机器人就沿着链接抓取
robots.txt的作用:
1、引导搜索引擎蜘蛛抓取指定栏目或内容;
2、网站改版或者URL重写优化时候屏蔽对搜索引擎不友好的链接;
3、屏蔽死链接、404错误页面;
4、屏蔽无内容、无价值页面;
5、屏蔽重复页面,如评论页、搜索结果页;
6、屏蔽任何不想被收录的页面;
7、引导蜘蛛抓取网站地图;
举个例子:
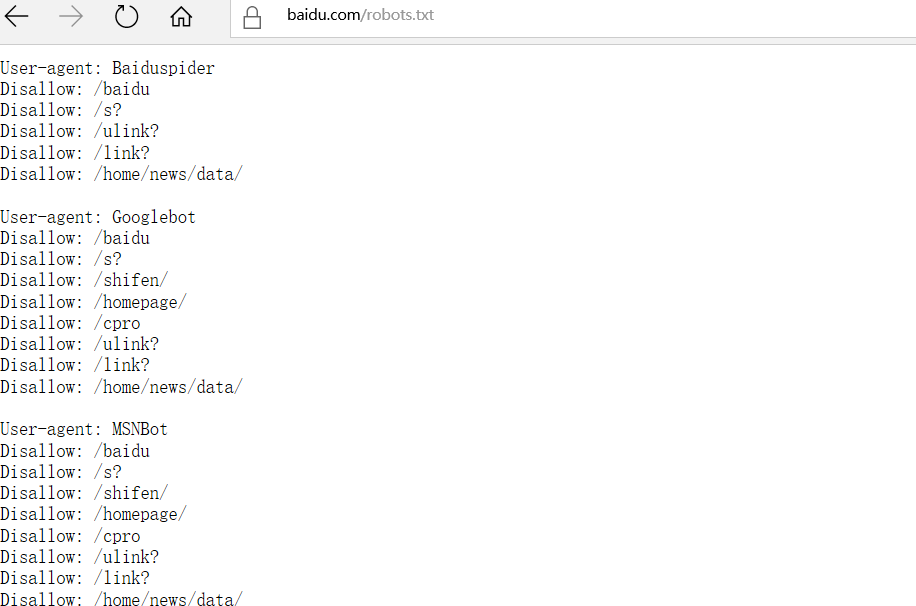
我访问了百度的robots文件
User-agent:表示针对的搜索引擎
Disallow:用来定义禁止蜘蛛爬取的页面或目录
Allow:用来定义允许蜘蛛爬取的页面或子目录
一般还会有网站的robots.txt给出Crawl-delay:5,意味着5秒内连续抓取就会禁止抓取一定时间
sitemap文件经常缺失所以在此处就不细讲
估算网站的大小
识别网站技术:
用builtwith模块

识别网站所有者,根据网站所有者的类型来设置爬虫速度
用whois模块

以上就是普通的准备工作
python2下经典爬虫(第一卷)的更多相关文章
- python3下scrapy爬虫(第一卷:安装问题)
一般爬虫都是用urllib包,requests包 配合正则.beautifulsoup等包混合使用,达到爬虫效果,不过有框架谁还用原生啊,现在我们来谈谈SCRAPY框架爬虫, 现在python3的兼容 ...
- 2018-02-03-PY3下经典数据集iris的机器学习算法举例-零基础
---layout: posttitle: 2018-02-03-PY3下经典数据集iris的机器学习算法举例-零基础key: 20180203tags: 机器学习 ML IRIS python3mo ...
- (5)分布式下的爬虫Scrapy应该如何做-windows下的redis的安装与配置
软件版本: redis-2.4.6-setup-64-bit.exe — Redis 2.4.6 Windows Setup (64-bit) 系统: win7 64bit 本篇的内容是为了给分布式下 ...
- (4)分布式下的爬虫Scrapy应该如何做-规则自动爬取及命令行下传参
本次探讨的主题是规则爬取的实现及命令行下的自定义参数的传递,规则下的爬虫在我看来才是真正意义上的爬虫. 我们选从逻辑上来看,这种爬虫是如何工作的: 我们给定一个起点的url link ,进入页面之后提 ...
- 【css】回想下经典的布局
看到这张图相信大多数人都很熟悉,这曾经是一种经典的布局方式,一道经典的面试题,一般形如"实现一个布局,左右固定宽度,中间自适应".随着岁月的流转,时光的交替(颇有一种“天下风云出我 ...
- [Selenium2+python2.7][Scrap]爬虫和selenium方式下拉滚动条获取简书作者目录并且生成Markdown格式目录
预计阅读时间: 15分钟 环境: win7 + Selenium2.53.6+python2.7 +Firefox 45.2 (具体配置参考 http://www.cnblogs.com/yoyok ...
- ubuntu14.04下安装爬虫工具scrapy
scrapy是目前准备要学习的爬虫框架,其在ubuntu14.04下的安装过程如下: ubuntu14.04下默认安装了2.7的python以及setuptools,若未安装,可通过下面指令安装: s ...
- Python2和Python3 爬虫 转换
由于Python3的不断完善,很多新入Python的小伙伴选择了Python3的阵营,很多人选择了爬虫这一热门话题,但是网络上大部分教程都是Python2 教程,Python3这一块做了些许的改动,对 ...
- mac 关于默认python2下的pip,和python3下pip 的坑
pip是常用的python包管理工具,类似于java的maven.用python的同学,都离不开pip. 1.在Python2.7的安装包中,easy_install.py是默认安装的,而pip需要手 ...
随机推荐
- os简介
1. 操作系统(Operation System,OS) 操作系统作为接口的示意图  没有安装操作系统的计算机,通常被称为 裸机 如果想在 裸机 上运行自己所编写的程序,就必须用机器语言书写程序 如 ...
- 在storyboard中给控制器添加导航栏控制器和标签控制器
1.选中目标控制器 2.选择xcode的工具栏中的"Editor"->"Embed in"->"Navigation Controller ...
- 堆排序算法以及python实现
堆满足的条件:1,是一颗完全二叉树.2,大根堆:父节点大于各个孩子节点.每个节点都满足这个道理.小根堆同理. parent = (i-1)/2 #i为当前节点 left = 2*i+1 righ ...
- java学习——内部类(二)
使用内部类 内部类一共有三种使用方法: 1.在外部类中使用内部类 在外部类中使用内部类,与平常使用内部类没有区别,可以直接通过内部类的类名来定义变量,通过new调用内部类的构造方法来创建实例. 唯一的 ...
- UML-如何画常用UML交互图?
1.生命线框图(参与者) 2.消息表达式
- 2×c列联表|多组比例简式|卡方检验|χ2检验与连续型资料假设检验
第四章 χ2检验 χ2检验与连续型资料假设检验的区别? 卡方检验的假设检验是什么? 理论值等于实际值 何条件下卡方检验的需要矫正?如何矫正? 卡方检验的自由度如何计算? Df=k-1而不是n-1 卡方 ...
- Django专题-中间件
前戏 我们给视图函数加装饰器来判断是用户是否登录,把没有登录的用户请求跳转到登录页面.我们通过给几个特定视图函数加装饰器实现了这个需求.但是以后添加的视图函数可能也需要加上装饰器,这样是不是稍微有点繁 ...
- opencv模板匹配查找图像(python)
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import cv2 import numpy as np from cv2 import COLOR_B ...
- python学习笔记(25)-继承
#继承 class RobotOne: #第一代机器人 def __init__(self,year,name): self.year=year self.name=name def walking_ ...
- springboot多数据源+jta事务管理配置
1.创建一个maven项目,导入相关配置: <?xml version="1.0" encoding="UTF-8"?> <project x ...