Hadoop 三剑客之 —— 分布式文件存储系统 HDFS
一、介绍
HDFS (Hadoop Distributed File System)是Hadoop下的分布式文件系统,具有高容错、高吞吐量等特性,可以部署在低成本的硬件上。
二、HDFS 设计原理
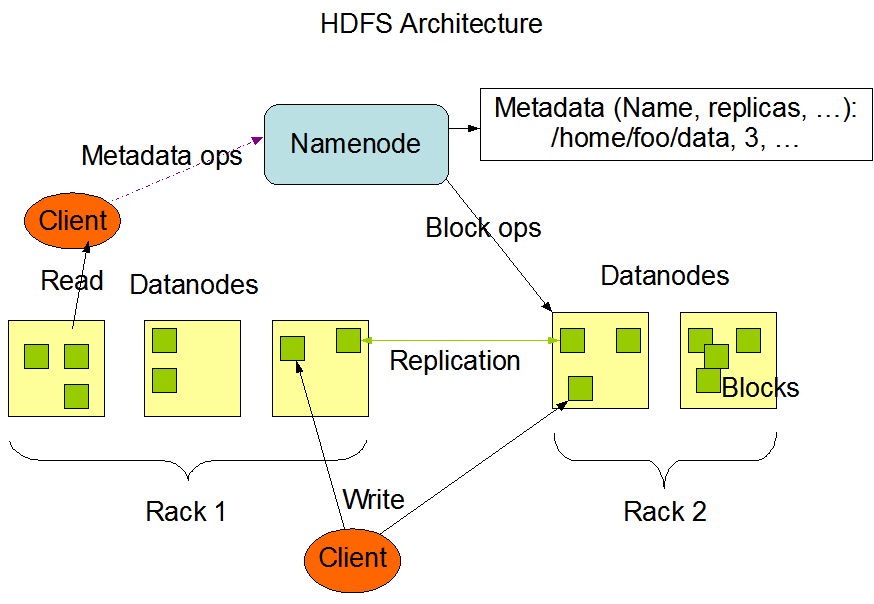
2.1 HDFS 架构
HDFS 遵循主/从架构,由单个NameNode(NN)和多个DataNode(DN)组成:
- NameNode : 负责执行有关
文件系统命名空间的操作,例如打开,关闭、重命名文件和目录等。它同时还负责集群元数据的存储,记录着文件中各个数据块的位置信息。 - DataNode:负责提供来自文件系统客户端的读写请求,执行块的创建,删除等操作。
2.2 文件系统命名空间
HDFS的文件系统命名空间的层次结构与大多数文件系统类似(如Linux), 支持目录和文件的创建、移动、删除和重命名等操作,支持配置用户和访问权限,但不支持硬链接和软连接。NameNode负责维护文件系统名称空间,记录对名称空间或其属性的任何更改。
2.3 数据复制
由于Hadoop被设计运行在廉价的机器上,这意味着硬件是不可靠的,为了保证容错性,HDFS提供了数据复制机制。HDFS 将每一个文件存储为一系列块,每个块由多个副本来保证容错,块的大小和复制因子可以自行配置(默认情况下,块大小是128M,默认复制因子是3)。
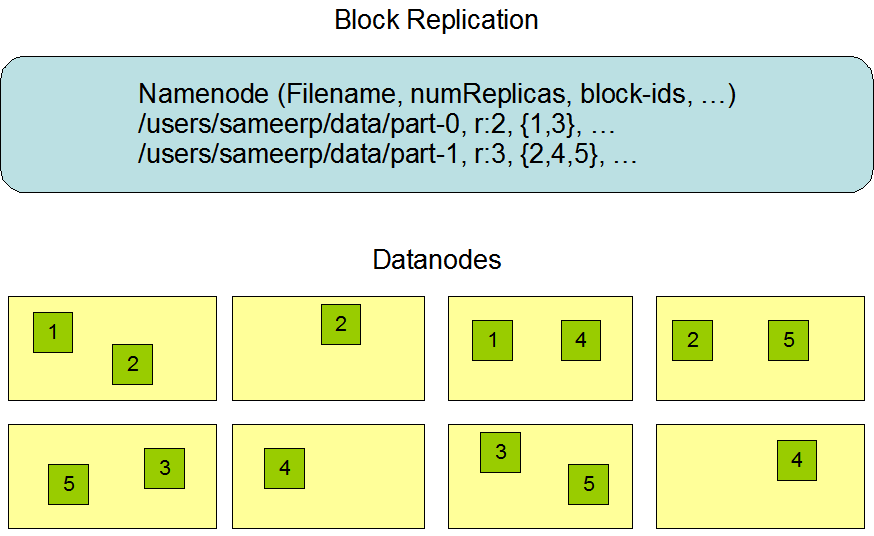
2.4 数据复制的实现原理
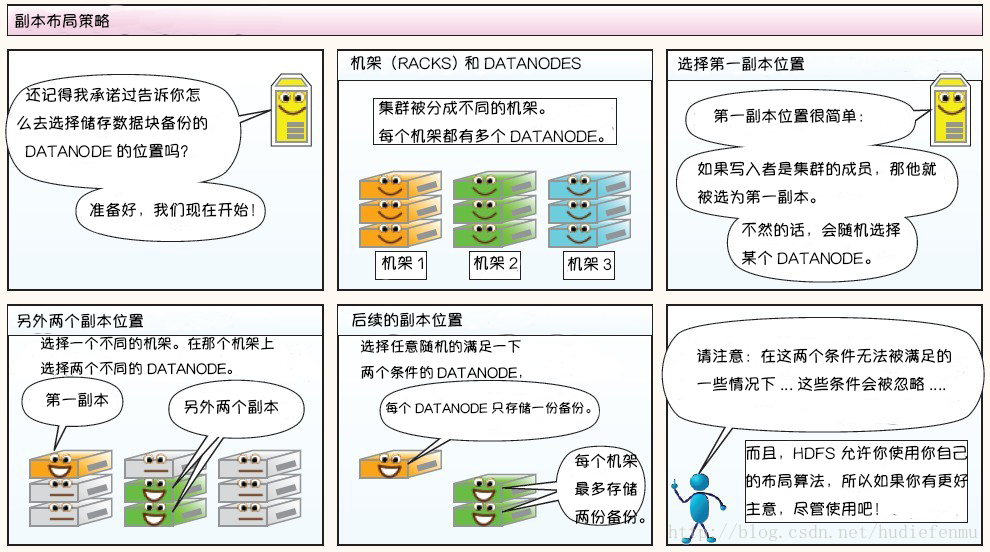
大型的HDFS实例在通常分布在多个机架的多台服务器上,不同机架上的两台服务器之间通过交换机进行通讯。在大多数情况下,同一机架中的服务器间的网络带宽大于不同机架中的服务器之间的带宽。因此HDFS采用机架感知副本放置策略,对于常见情况,当复制因子为3时,HDFS的放置策略是:
在写入程序位于datanode上时,就优先将写入文件的一个副本放置在该datanode上,否则放在随机datanode上。之后在另一个远程机架上的任意一个节点上放置另一个副本,并在该机架上的另一个节点上放置最后一个副本。此策略可以减少机架间的写入流量,从而提高写入性能。
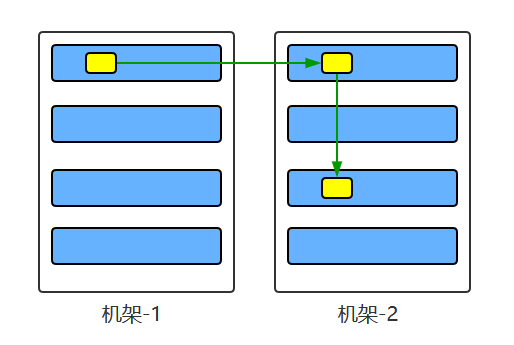
如果复制因子大于3,则随机确定第4个和之后副本的放置位置,同时保持每个机架的副本数量低于上限,上限值通常为(复制系数 - 1)/机架数量 + 2,需要注意的是不允许同一个dataNode上具有同一个块的多个副本。
2.5 副本的选择
为了最大限度地减少带宽消耗和读取延迟,HDFS在执行读取请求时,优先读取距离读取器最近的副本。如果在与读取器节点相同的机架上存在副本,则优先选择该副本。如果HDFS群集跨越多个数据中心,则优先选择本地数据中心上的副本。
2.6 架构的稳定性
1. 心跳机制和重新复制
每个DataNode定期向NameNode发送心跳消息,如果超过指定时间没有收到心跳消息,则将DataNode标记为死亡。NameNode不会将任何新的IO请求转发给标记为死亡的DataNode,也不会再使用这些DataNode上的数据。 由于数据不再可用,可能会导致某些块的复制因子小于其指定值,NameNode会跟踪这些块,并在必要的时候进行重新复制。
2. 数据的完整性
由于存储设备故障等原因,存储在DataNode上的数据块也会发生损坏。为了避免读取到已经损坏的数据而导致错误,HDFS提供了数据完整性校验机制来保证数据的完整性,具体操作如下:
当客户端创建HDFS文件时,它会计算文件的每个块的校验和,并将校验和存储在同一HDFS命名空间下的单独的隐藏文件中。当客户端检索文件内容时,它会验证从每个DataNode接收的数据是否与存储在关联校验和文件中的校验和匹配。如果匹配失败,则证明数据已经损坏,此时客户端会选择从其他DataNode获取该块的其他可用副本。
3.元数据的磁盘故障
FsImage和EditLog是HDFS的核心数据,这些数据的意外丢失可能会导致整个HDFS服务不可用。为了避免这个问题,可以配置NameNode使其支持FsImage和EditLog多副本同步,这样FsImage或EditLog的任何改变都会引起每个副本FsImage和EditLog的同步更新。
4.支持快照
快照支持在特定时刻存储数据副本,在数据意外损坏时,可以通过回滚操作恢复到健康的数据状态。
三、HDFS 的特点
3.1 高容错
由于HDFS 采用数据的多副本方案,所以部分硬件的损坏不会导致全部数据的丢失。
3.2 高吞吐量
HDFS设计的重点是支持高吞吐量的数据访问,而不是低延迟的数据访问。
3.3 大文件支持
HDFS适合于大文件的存储,文档的大小应该是是GB到TB级别的。
3.3 简单一致性模型
HDFS更适合于一次写入多次读取(write-once-read-many)的访问模型。支持将内容追加到文件末尾,但不支持数据的随机访问,不能从文件任意位置新增数据。
3.4 跨平台移植性
HDFS具有良好的跨平台移植性,这使得其他大数据计算框架都将其作为数据持久化存储的首选方案。
附:图解HDFS存储原理
说明:以下图片引用自博客:翻译经典 HDFS 原理讲解漫画
1. HDFS写数据原理
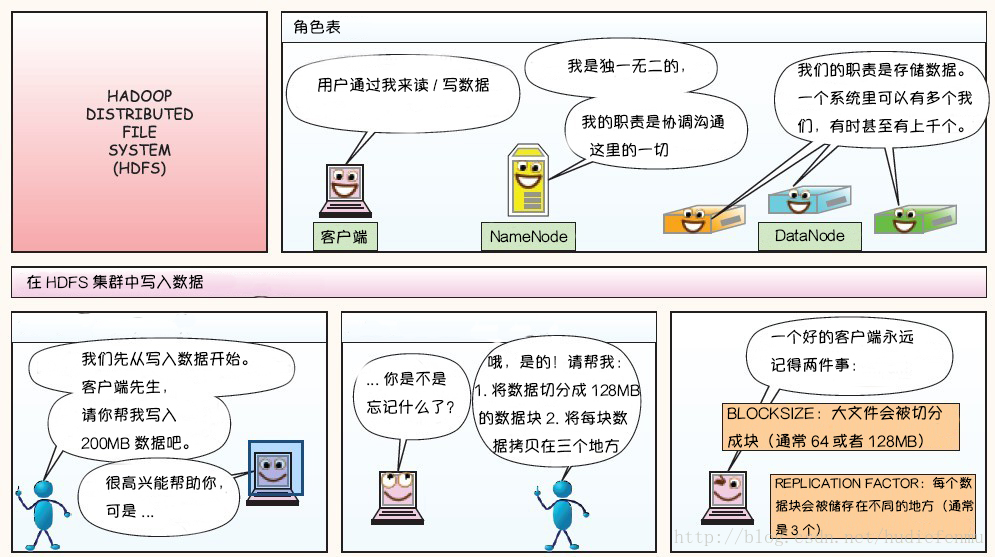
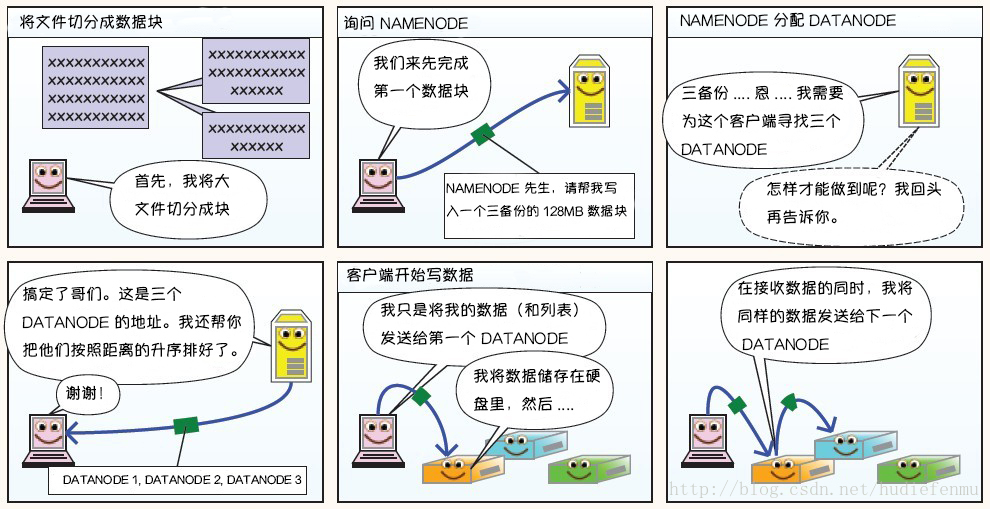
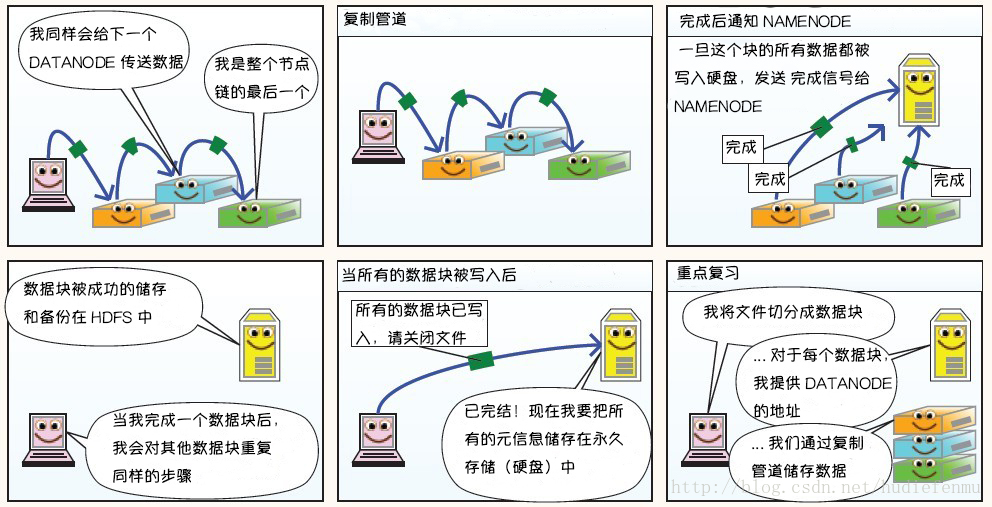
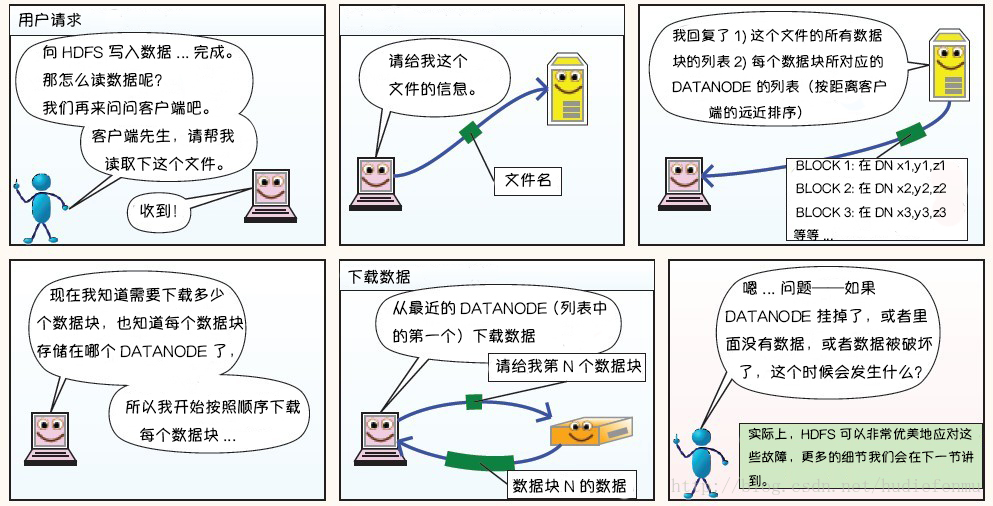
2. HDFS读数据原理
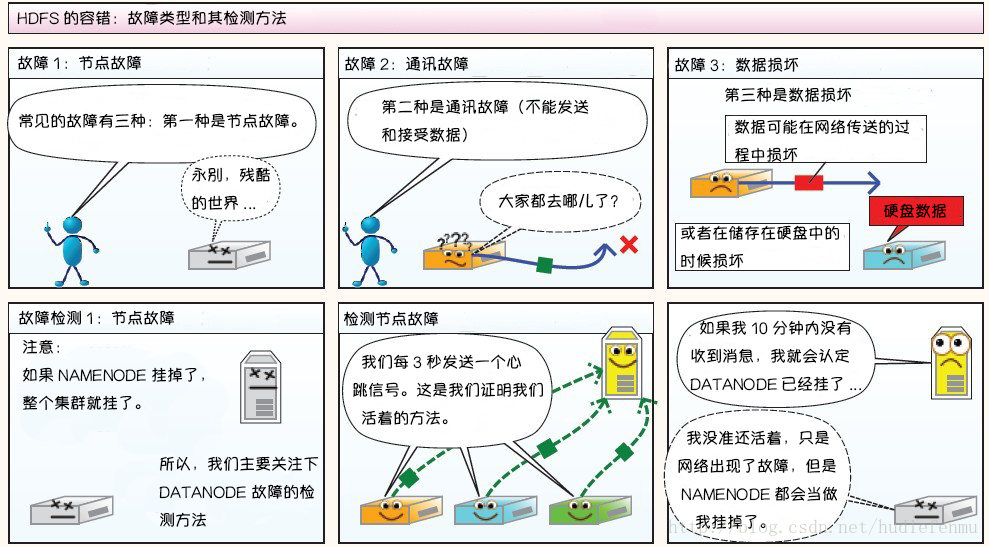
3. HDFS故障类型和其检测方法
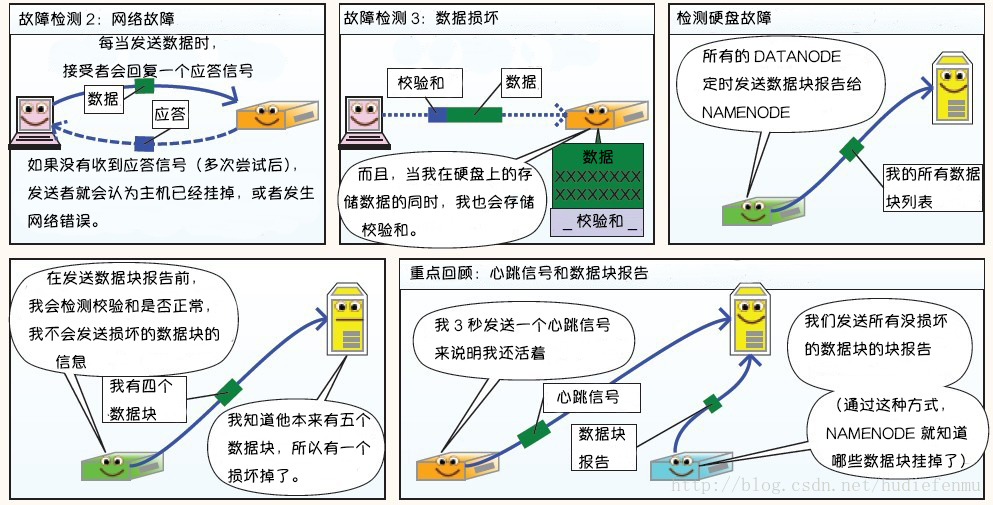
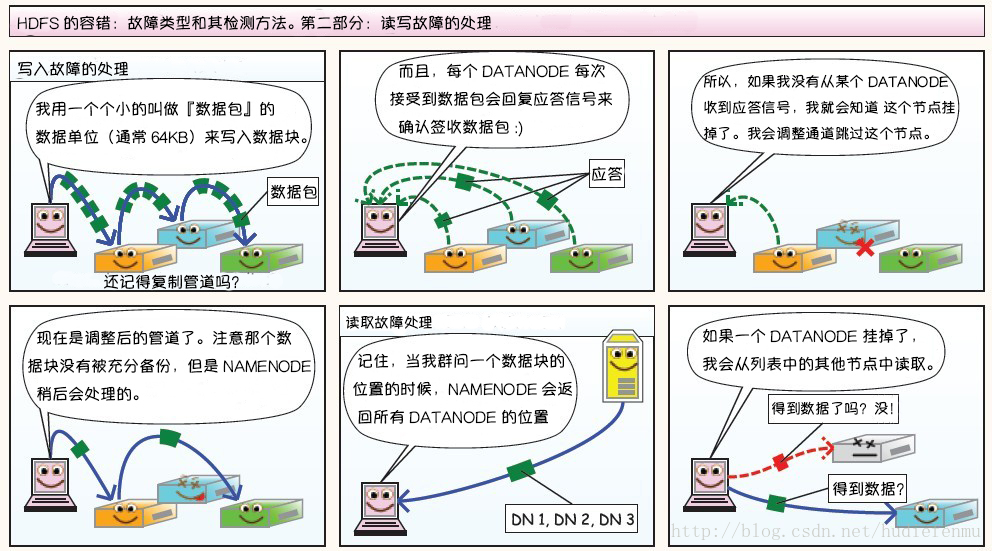
第二部分:读写故障的处理
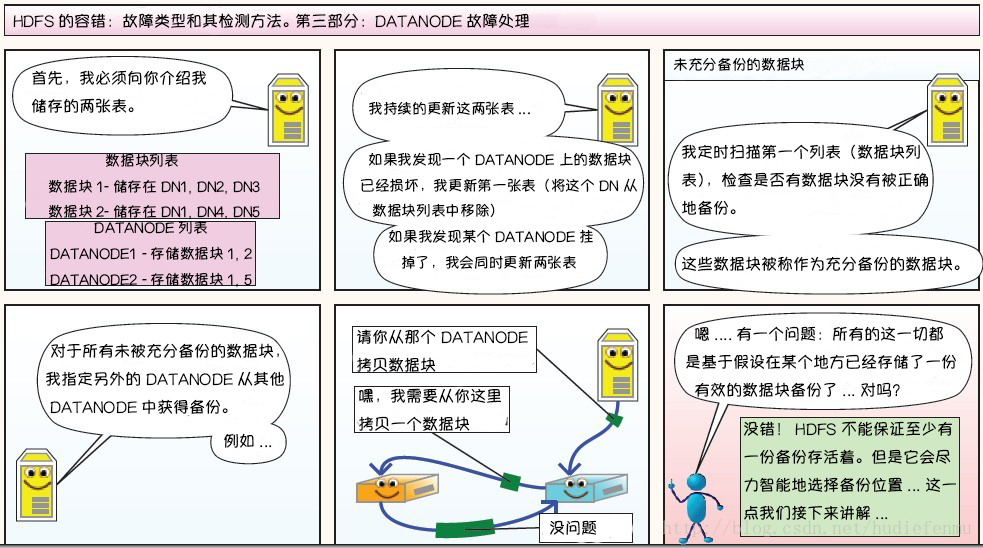
第三部分:DataNode故障处理
副本布局策略:
参考资料
- Apache Hadoop 2.9.2 > HDFS Architecture
- Tom White . hadoop权威指南 [M] . 清华大学出版社 . 2017.
- 翻译经典 HDFS 原理讲解漫画
更多大数据系列文章可以参见个人 GitHub 开源项目: 大数据入门指南
Hadoop 三剑客之 —— 分布式文件存储系统 HDFS的更多相关文章
- 一图看懂hadoop分布式文件存储系统HDFS工作原理
一图看懂hadoop分布式文件存储系统HDFS工作原理
- 必须掌握的分布式文件存储系统—HDFS
HDFS(Hadoop Distributed File System)分布式文件存储系统,主要为各类分布式计算框架如Spark.MapReduce等提供海量数据存储服务,同时HBase.Hive底层 ...
- 分布式文件管理系统HDFS
Hadoop 分布式文件管理系统HDFS可以部署在廉价硬件之上,能够高容错. 可靠地存储海量数据(可以达到TB甚至PB级),它还可以和Yam中的MapReduce 编程模型很好地结合,为应用程序提供高 ...
- 淘宝分布式文件存储系统:TFS
TFS ——分布式文件存储系统 TFS(Taobao File System)是淘宝针对海量非结构化数据存储设计的分布式系统,构筑在普通的Linux机器集群上,可为外部提供高可靠和高并发的存储访问. ...
- 用asp.net core结合fastdfs打造分布式文件存储系统
最近被安排开发文件存储微服务,要求是能够通过配置来无缝切换我们公司内部研发的文件存储系统,FastDFS,MongDb GridFS,阿里云OSS,腾讯云OSS等.根据任务紧急度暂时先完成了通过配置来 ...
- hadoop配置及无法移动文件到hdfs故障解析
首先博主用的64位ubuntu,hadoop官方只提供32位版本,这样的话启动本地库无法兼容,需要自己编译为64位版本,或下载别人编译好的64位版本. 下载好需要在etc/hadoop目录下改动以下几 ...
- redis/分布式文件存储系统/数据库 存储session,解决负载均衡集群中session不一致问题
先来说下session和cookie的异同 session和cookie不仅仅是一个存放在服务器端,一个存放在客户端那么笼统 session虽然存放在服务器端,但是也需要和客户端相互匹配,试想一个浏览 ...
- mogilefs分布式文件存储
MogileFS是一个开源的分布式文件存储系统,由LiveJournal旗下的Danga Interactive公司开发.Danga团队开发了包括 Memcached.MogileFS.Perlbal ...
- Hadoop 3、Hadoop 分布式存储系统 HDFS
HDFS是Hadoop Distribute File System 的简称,也就是Hadoop的一个分布式文件系统. 一.HDFS的优缺点 1.HDFS优点: a.高容错性 .数据保存多个副本 .数 ...
随机推荐
- SilverLight Q&A
1.在学校prism,Unity框架的时候,遇到的问题“The IModuleCatalog is required and cannot be null in order to initialize ...
- CI中的超级对象
CI中的超级对象就是当前控制器对象,它提供了很多属性,可以通过var_dump($this)打印所有的超级对象: load可以理解为一个加载器,加载了很多功能,可以理解为当你使用 $this -> ...
- js中国各大城市快速选择代码
js中国各大城市快速选择插件 在线演示本地下载
- 自定义安装MS Office Project2007会出错
作者:朱金灿 来源:http://blog.csdn.net/clever101 今天使用虚拟光驱文件自定义安装MSOffice Project2007,如下图: 然后总是出现一个错误: 从网上找来一 ...
- android黑科技系列——Apk的加固(加壳)原理解析和实现
一.前言 今天又到周末了,憋了好久又要出博客了,今天来介绍一下Android中的如何对Apk进行加固的原理.现阶段.我们知道Android中的反编译工作越来越让人操作熟练,我们辛苦的开发出一个apk, ...
- Java学习-课堂总结
一.字符串比较方式 1)‘==’ 地址值比较 2) equals()方法 内容比较 二.String类的两种实例化方式 1)String str=“Hello”: 2 ...
- Cocos2d-x-3.6学习笔记第一天
系统环境: win7,python2.7 开发工具:vs2013 cocos版本:cocos2d-x-3.6 暂无模拟手机的环境 新建我的第一个cocos2d项目 1.打开cmd,cd到cocos2d ...
- 「图解HTTP 笔记」Web 基础
Web 基础 三项构建技术: HTML:页面的文本标记语言 HTTP:文档传输协议 URL:指定文档所在地址 一些概念 HTTP(HyperText Transfer Protocol):通常被译为& ...
- **PCD数据获取:Kinect+OpenNI+PCL对接(代码)
前言: PCL使用点云作为数据格式,Kinect可以直接作为三维图像的数据源产生三维数据,其中的桥梁是OpenNI和PrimeSense.为了方便地使用Kinect的数据,还是把OpenNI获取的基础 ...
- JS 100内与7相关的数
var s =""; for(var i=0;i;i++) { if(i%7 == 0 ){ s += i+","; } else if((i-7)%10 == ...