0926mysql join的原理
转自 http://www.cnblogs.com/shengdimaya/p/7123069.html
MySQL JOIN原理
先看一下实验的两张表:
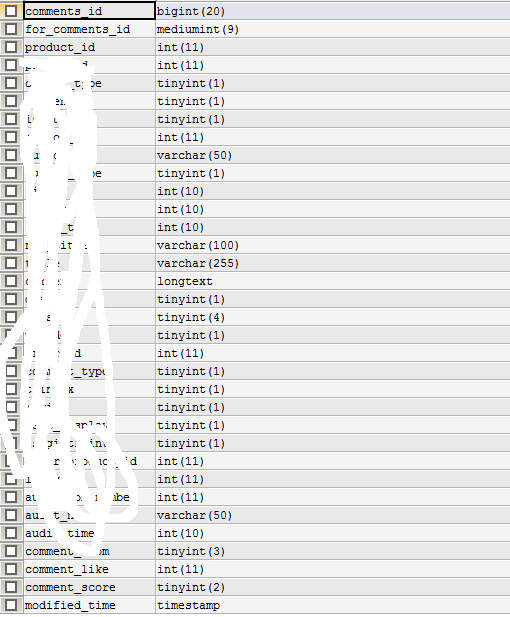
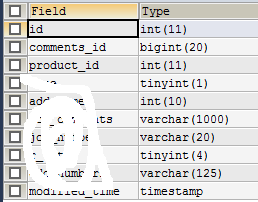
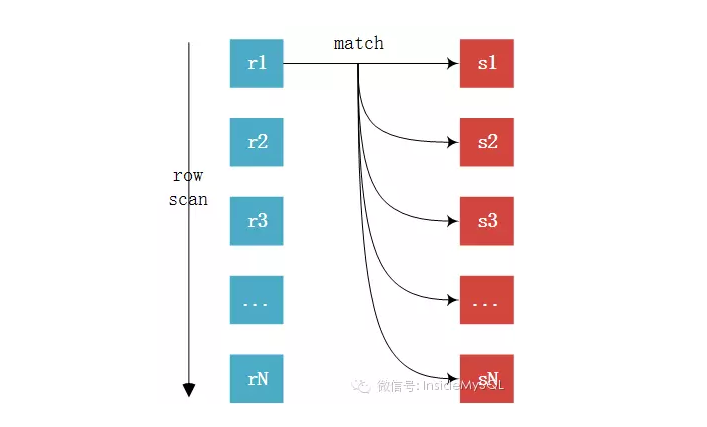
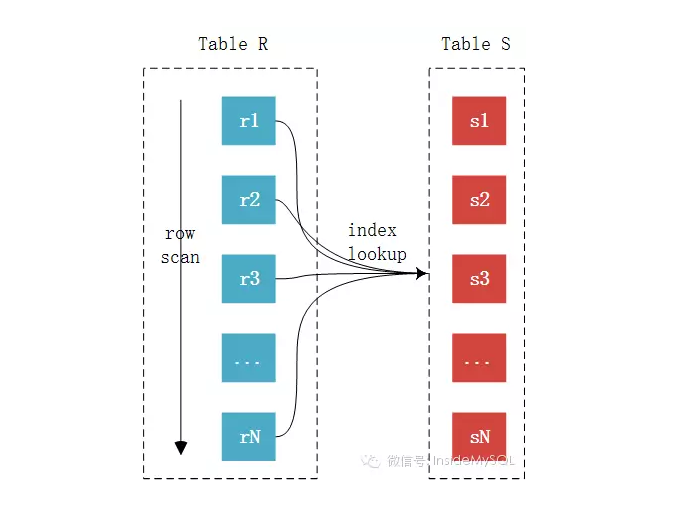
EXPLAIN SELECT * FROM comments gc
JOIN comments_for gcf ON gc.comments_id=gcf.comments_id;

SELECT * FROM comments gc
JOIN comments_for gcf ON gc.comments_id=gcf.comments_id
WHERE gc.comments_id =2056

EXPLAIN SELECT * FROM comments gc
JOIN comments_for gcf ON gc.order_id=gcf.product_id

EXPLAIN SELECT * FROM comments gc
LEFT JOIN comments_for gcf ON gc.comments_id=gcf.comments_id

EXPLAIN SELECT * FROM comments_for gcf
LEFT JOIN comments gc ON gc.comments_id=gcf.comments_id
WHERE gcf.comments_id =2056
 此,join基本上已经很明了了,未完待续中,欢迎大家指出错误,我会认真改正。。。。
此,join基本上已经很明了了,未完待续中,欢迎大家指出错误,我会认真改正。。。。0926mysql join的原理的更多相关文章
- 排序合并连接(sort merge join)的原理
排序合并连接(sort merge join)的原理 排序合并连接(sort merge join)的原理 排序合并连接(sort merge join) 访问次数:两张表都只会访 ...
- Hive中Join的原理和机制
转自:http://lxw1234.com/archives/2015/06/313.htm 笼统的说,Hive中的Join可分为Common Join(Reduce阶段完成join)和Map Joi ...
- MySql join匹配原理
疑问 表:sl_sales_bill_head 订单抬头表 数据行:8474 表:sl_sales_bill 订单明细 数据行:8839 字段:SALES_BILL_NO 订单号 情 ...
- join方法原理
join()方法--原理同wait方法 如果不知道保护性暂停是啥的可以参考一下上一篇文章 https://www.cnblogs.com/duizhangz/p/16222854.html join方 ...
- 谈谈fork/join实现原理
害,又是一个炒冷饭的时间.fork/join是在jdk1.7中出现的一个并发工作包,其特点是可以将一个大的任务拆分成多个子任务进行并行处理,最后将子任务结果合并成最后的计算结果,并进行输出.从而达到多 ...
- mysql join 底层原理
你知道 Sql 中 left join 的底层原理吗? 2019-09-10阅读 7130 https://cloud.tencent.com/developer/column/2367 01.前 ...
- 【原创】大数据基础之Spark(8)Spark中Join实现原理
spark中join有两种,一种是RDD的join,一种是sql中的join,分别来看: 1 RDD join org.apache.spark.rdd.PairRDDFunctions /** * ...
- 8.深入TiDB:解析Hash Join实现原理
本文基于 TiDB release-5.1进行分析,需要用到 Go 1.16以后的版本 我的博客地址:https://www.luozhiyun.com/archives/631 所谓 Hash Jo ...
- mysql join优化原理
http://blog.itpub.net/22664653/viewspace-1692317/ http://itindex.net/detail/46772-%E4%BC%98%E5%8C%96 ...
随机推荐
- [Contest Hunter#17-C] 舞动的夜晚
[题目链接] http://contest-hunter.org:83/contest/CH%20Round%20%2317/%E8%88%9E%E5%8A%A8%E7%9A%84%E5%A4%9C% ...
- 什么是 less? 如何使用 less?
什么是 Less? Less 是一门 CSS 预处理语言,它扩充了 CSS 语言,增加了诸如变量.混合(mixin).嵌套.函数等功能,让 CSS 更易编写.维护等. 本质上,Less 包含一套自定义 ...
- 前端布局神器 display:flex
前端布局神器display:flex 一直使用flex布局,屡试不爽,但是总是记不住一些属性,这里写来记录一下. 2009年,W3C提出了一种新的方案--Flex布局,可以简便.完整.响应式地实现 ...
- [BZOJ1821][JSOI2010]部落划分
感觉学了这么久还是有那么一丢丢进步的...上个学期看到这道题,虽然早就学过并查集和二分了但还是一点思路都没有,现在可以秒切了呢 思路就是二分+并查集,有些人说是生成树,其实它没有变成树,只是运用了生成 ...
- MySQL 的单表查询
单表查询 语法: 一.单表查询的语法 SELECT 字段1,字段2 ,...FROM 表名 WHERE 条件 GROUP BY field HAVING 筛选 ORDER BY filed LIMIT ...
- HTML中javascript使用dom获取dom节点范例
<!-- HTML结构 --> <div id="test-div"> <div class="c-red"> <p ...
- Git教程(3)git工作区与文件状态及简单示例
基础 目录: working driectory 工作目录,就是我们的工作目录,其中包括未跟踪文件及暂存区和仓库目录. staging area 暂存区,不对应一个具体目录,其实只是git di ...
- elasticsearch性能调优
转载 http://www.cnblogs.com/hseagle/p/6015245.html 该es调优版本可能有低,但是思想主体不变,不合适的参数可以自己找最新的版本相应的替代,或者增删 ela ...
- 5.13Junit单元测试-反射-注解
一.Junit单元测试 * 测试分类: 1.黑盒测试:不需要写代码,给输入值,看程序是否能够输出期望的值 2.白盒测试:需要些代码的.关注程序具体的执行流程 Junit使用:白盒测试 步骤: 1.定义 ...
- jquery学习之$(document).ready()
参考资料: 1.W3School在线教程:http://www.w3school.com.cn/jquery/event_ready.asp 2.某人博客园:http://www.cnblogs.co ...