强化学习(2)----Q-learning
1、Q-learning主要是Q表:
当前状态s1,接下来可以有两个动作选择,看电视a1和学习a2,对于agent人来说,可以根据reward来作出决策(Policy)。目的就是得到奖励最大。
Q-learning的目的就是学习特定state下、特定Action的价值。
Q-learning的方法是建立一个表,以state为行、action为列。比如:state有2个,action也有两个,所以Q-table就是2×2的一个表,对应总共4种可能得决策。
2、模型:
首先以 0 填充Q-table进行初始化,然后观察每一个决策带来的回馈,再更新Q-table。更新的依据是Bellman等式:
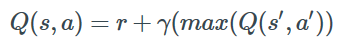

每一次行动,都会更新Q-table。
初始Q-table如下(行:state,列:action):
| a1 | a2 | |
| s1 | 0 | 0 |
| s2 | 0 | 0 |
相应的Q-table如下:
| a1 | a2 | |
| s1 | -2 | 1 |
| s2 | -4 | 2 |
但是这个Q-table是我们希望得出或逼近的,在开始时,Agent所知的Q-table还是一个全0的矩阵。
3、算法:

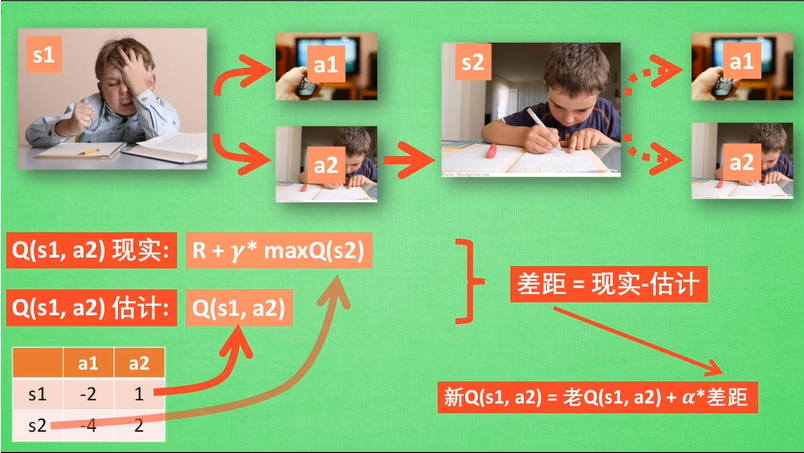


算法中的 α 是指学习率,其控制前一个 Q 值和新提出的 Q 值之间被考虑到的差异程度。尤其是,当 α=1 时,两个 Q[s,a] 互相抵消,结果刚好和贝尔曼方程一样。
我们用来更新 Q[s,a] 的只是一个近似,而且在早期阶段的学习中它完全可能是错误的。但是随着每一次迭代,该近似会越来越准确;而且我们还发现如果我们执行这种更新足够长时间,那么 Q 函数就将收敛并能代表真实的 Q 值。
4、代码:
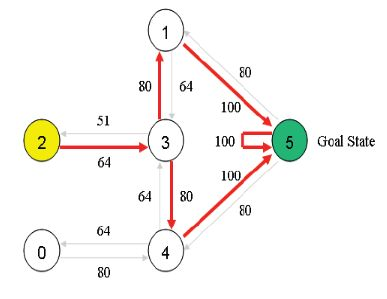
import numpy as np
GAMMA = 0.8
Q = np.zeros((6,6))
R=np.asarray([[-1,-1,-1,-1,0,-1],
[-1,-1,-1,0,-1,100],
[-1,-1,-1,0,-1,-1],
[-1,0, 0, -1,0,-1],
[0,-1,-1,0,-1,100],
[-1,0,-1,-1,0,100]])
def getMaxQ(state):
return max(Q[state, :])
def QLearning(state):
curAction = None
for action in range(6):
if(R[state][action] == -1):
Q[state, action]=0
else:
curAction = action
Q[state,action]=R[state][action]+GAMMA * getMaxQ(curAction)
count=0
while count<1000:
for i in range(6):
QLearning(i)
count+=1
print(Q/5)
强化学习(2)----Q-learning的更多相关文章
- 强化学习9-Deep Q Learning
之前讲到Sarsa和Q Learning都不太适合解决大规模问题,为什么呢? 因为传统的强化学习都有一张Q表,这张Q表记录了每个状态下,每个动作的q值,但是现实问题往往极其复杂,其状态非常多,甚至是连 ...
- 强化学习_Deep Q Learning(DQN)_代码解析
Deep Q Learning 使用gym的CartPole作为环境,使用QDN解决离散动作空间的问题. 一.导入需要的包和定义超参数 import tensorflow as tf import n ...
- 转:强化学习(Reinforcement Learning)
机器学习算法大致可以分为三种: 1. 监督学习(如回归,分类) 2. 非监督学习(如聚类,降维) 3. 增强学习 什么是增强学习呢? 增强学习(reinforcementlearning, RL)又叫 ...
- 强化学习10-Deep Q Learning-fix target
针对 Deep Q Learning 可能无法收敛的问题,这里提出了一种 fix target 的方法,就是冻结现实神经网络,延时更新参数. 这个方法的初衷是这样的: 1. 之前我们每个(批)记忆都 ...
- 强化学习(Reinforcement Learning)中的Q-Learning、DQN,面试看这篇就够了!
1. 什么是强化学习 其他许多机器学习算法中学习器都是学得怎样做,而强化学习(Reinforcement Learning, RL)是在尝试的过程中学习到在特定的情境下选择哪种行动可以得到最大的回报. ...
- 机器学习之强化学习概览(Machine Learning for Humans: Reinforcement Learning)
声明:本文翻译自Vishal Maini在Medium平台上发布的<Machine Learning for Humans>的教程的<Part 5: Reinforcement Le ...
- [Reinforcement Learning] 强化学习介绍
随着AlphaGo和AlphaZero的出现,强化学习相关算法在这几年引起了学术界和工业界的重视.最近也翻了很多强化学习的资料,有时间了还是得自己动脑筋整理一下. 强化学习定义 先借用维基百科上对强化 ...
- The categories of Reinforcement Learning 强化学习分类
RL分为三大类: (1)通过行为的价值来选取特定行为的方法,具体 包括使用表格学习的 q learning, sarsa, 使用神经网络学习的 deep q network: (2)直接输出行为的 p ...
- 【整理】强化学习与MDP
[入门,来自wiki] 强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益.其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的 ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
随机推荐
- JS 限制input框的输入字数,并提示可输入字数
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8&quo ...
- hdu 1754 I Hate It【线段树】
维护一个最大值 #include<cstdio> #include<cstring> #include<iostream> #include<algorith ...
- CorelDRAW 2017通过智能笔触调整自然地绘制草图
LiveSketch 工具是CorelDRAW 2017版本中的新增功能,LiveSketch 工具适合快速草图和绘图,可以帮助您加快工作流并使您能够专注于创建流程.该工具并不预填充节点和图柄,而且无 ...
- SQL日期数据格式的处理
sql server2000中使用convert来取得datetime数据类型样式(全) 日期数据格式的处理,两个示例: CONVERT(varchar(16), 时间一, 20) 结果:2007-0 ...
- BZOJ 3413 匹配 (后缀自动机+线段树合并)
题目大意: 懒得概括了 神题,搞了2个半晚上,还认为自己的是对的...一直调不过,最后终于在jdr神犇的帮助下过了这道题 线段树合并该是这道题最好理解且最好写的做法了,貌似主席树也行?但线段树合并这个 ...
- myeclipse的git插件安装
首先需要一个myeclies的Git插件EGit 点击下载5.0.1 官方网站
- vue 根据下拉框动态切换form的rule
taskCategorySelect (val) { // 任务类别下拉选择 if ( val == 5 ) { this.cameraORgateway = false; // true不可以使用 ...
- python web开发 编写web框架
参考链接:https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/00143233900 ...
- 论wpf的设备无关性 - 简书
原文:论wpf的设备无关性 - 简书 WPF从发布之日起,一直将“分辨率无关(resolution independence)”作为其亮点,声称使用WPF制作的用户界面在轻巧的Ultra-Mobile ...
- C语言使用memcpy函数实现两个数间任意位置的复制操作
c和c++使用的内存拷贝函数,memcpy函数的功能是从源src所指的内存地址的起始位置开始拷贝n个字节到目标dest所指的内存地址的起始位置中. 用法:void *memcpy(void *dest ...