高可用OpenStack(Queen版)集群-6.Nova控制节点集群
参考文档:
- Install-guide:https://docs.openstack.org/install-guide/
- OpenStack High Availability Guide:https://docs.openstack.org/ha-guide/index.html
- 理解Pacemaker:http://www.cnblogs.com/sammyliu/p/5025362.html
- Ceph: http://docs.ceph.com/docs/master/start/intro/
十.Nova控制节点集群
1. 创建nova相关数据库
# 在任意控制节点创建数据库,后台数据自动同步,以controller01节点为例;
# nova服务含4个数据库,统一授权到nova用户;
# placement主要涉及资源统筹,较常用的api接口是获取备选资源与claim资源等
[root@controller01 ~]# mysql -u root -pmysql_pass MariaDB [(none)]> CREATE DATABASE nova_api;
MariaDB [(none)]> CREATE DATABASE nova;
MariaDB [(none)]> CREATE DATABASE nova_cell0;
MariaDB [(none)]> CREATE DATABASE nova_placement; MariaDB [(none)]> GRANT ALL PRIVILEGES ON nova_api.* TO 'nova'@'localhost' IDENTIFIED BY 'nova_dbpass';
MariaDB [(none)]> GRANT ALL PRIVILEGES ON nova_api.* TO 'nova'@'%' IDENTIFIED BY 'nova_dbpass'; MariaDB [(none)]> GRANT ALL PRIVILEGES ON nova.* TO 'nova'@'localhost' IDENTIFIED BY 'nova_dbpass';
MariaDB [(none)]> GRANT ALL PRIVILEGES ON nova.* TO 'nova'@'%' IDENTIFIED BY 'nova_dbpass'; MariaDB [(none)]> GRANT ALL PRIVILEGES ON nova_cell0.* TO 'nova'@'localhost' IDENTIFIED BY 'nova_dbpass';
MariaDB [(none)]> GRANT ALL PRIVILEGES ON nova_cell0.* TO 'nova'@'%' IDENTIFIED BY 'nova_dbpass'; MariaDB [(none)]> GRANT ALL PRIVILEGES ON nova_placement.* TO 'nova'@'localhost' IDENTIFIED BY 'nova_dbpass';
MariaDB [(none)]> GRANT ALL PRIVILEGES ON nova_placement.* TO 'nova'@'%' IDENTIFIED BY 'nova_dbpass'; MariaDB [(none)]> flush privileges;
MariaDB [(none)]> exit;
2. 创建nova/placement-api
# 在任意控制节点操作,以controller01节点为例;
# 调用nova相关服务需要认证信息,加载环境变量脚本即可
[root@controller01 ~]# . admin-openrc
1)创建nova/plcement用户
# service项目已在glance章节创建;
# nova/placement用户在”default” domain中
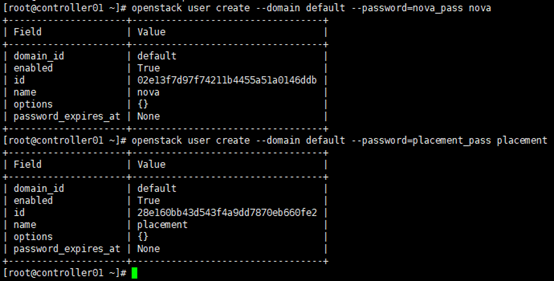
[root@controller01 ~]# openstack user create --domain default --password=nova_pass nova
[root@controller01 ~]# openstack user create --domain default --password=placement_pass placement
2)nova/placement赋权
# 为nova/placement用户赋予admin权限
[root@controller01 ~]# openstack role add --project service --user nova admin
[root@controller01 ~]# openstack role add --project service --user placement admin
3)创建nova/placement服务实体
# nova服务实体类型”compute”;
# placement服务实体类型”placement”
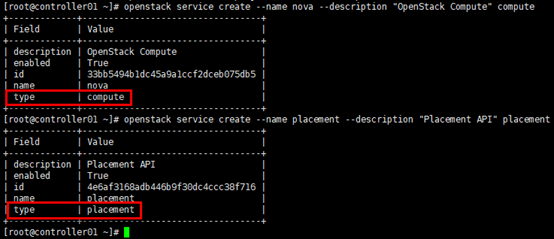
[root@controller01 ~]# openstack service create --name nova --description "OpenStack Compute" compute
[root@controller01 ~]# openstack service create --name placement --description "Placement API" placement
4)创建nova/placement-api
# 注意--region与初始化admin用户时生成的region一致;
# api地址统一采用vip,如果public/internal/admin分别使用不同的vip,请注意区分;
# nova-api 服务类型为compute,placement-api服务类型为placement;
# nova public api
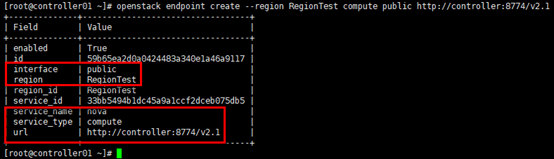
[root@controller01 ~]# openstack endpoint create --region RegionTest compute public http://controller:8774/v2.1
# nova internal api
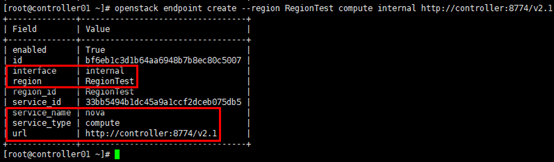
[root@controller01 ~]# openstack endpoint create --region RegionTest compute internal http://controller:8774/v2.1
# nova admin api
[root@controller01 ~]# openstack endpoint create --region RegionTest compute admin http://controller:8774/v2.1

# placement public api
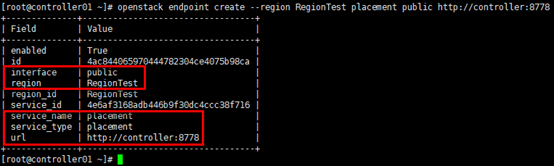
[root@controller01 ~]# openstack endpoint create --region RegionTest placement public http://controller:8778
# placement internal api
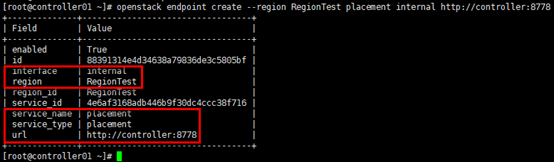
[root@controller01 ~]# openstack endpoint create --region RegionTest placement internal http://controller:8778
# placement admin api
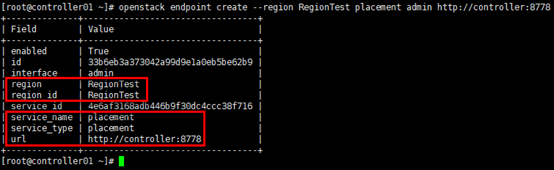
[root@controller01 ~]# openstack endpoint create --region RegionTest placement admin http://controller:8778
3. 安装nova
# 在全部控制节点安装nova相关服务,以controller01节点为例
[root@controller01 ~]# yum install openstack-nova-api openstack-nova-conductor \
openstack-nova-console openstack-nova-novncproxy \
openstack-nova-scheduler openstack-nova-placement-api -y
4. 配置nova.conf
# 在全部控制节点操作,以controller01节点为例;
# 注意”my_ip”参数,根据节点修改;
# 注意nova.conf文件的权限:root:nova
[root@controller01 ~]# cp /etc/nova/nova.conf /etc/nova/nova.conf.bak
[root@controller01 ~]# egrep -v "^$|^#" /etc/nova/nova.conf
[DEFAULT]
my_ip=172.30.200.31
use_neutron=true
firewall_driver=nova.virt.firewall.NoopFirewallDriver
enabled_apis=osapi_compute,metadata
osapi_compute_listen=$my_ip
osapi_compute_listen_port=8774
metadata_listen=$my_ip
metadata_listen_port=8775
# 前端采用haproxy时,服务连接rabbitmq会出现连接超时重连的情况,可通过各服务与rabbitmq的日志查看;
# transport_url=rabbit://openstack:rabbitmq_pass@controller:5673
# rabbitmq本身具备集群机制,官方文档建议直接连接rabbitmq集群;但采用此方式时服务启动有时会报错,原因不明;如果没有此现象,强烈建议连接rabbitmq直接对接集群而非通过前端haproxy
transport_url=rabbit://openstack:rabbitmq_pass@controller01:5672,controller02:5672,controller03:5672
[api]
auth_strategy=keystone
[api_database]
connection=mysql+pymysql://nova:nova_dbpass@controller/nova_api
[barbican]
[cache]
backend=oslo_cache.memcache_pool
enabled=True
memcache_servers=controller01:11211,controller02:11211,controller03:11211
[cells]
[cinder]
[compute]
[conductor]
[console]
[consoleauth]
[cors]
[crypto]
[database]
connection = mysql+pymysql://nova:nova_dbpass@controller/nova
[devices]
[ephemeral_storage_encryption]
[filter_scheduler]
[glance]
api_servers = http://controller:9292
[guestfs]
[healthcheck]
[hyperv]
[ironic]
[key_manager]
[keystone]
[keystone_authtoken]
auth_uri = http://controller:5000
auth_url = http://controller:35357
memcached_servers = controller01:11211,controller02:11211,controller03:11211
auth_type = password
project_domain_name = default
user_domain_name = default
project_name = service
username = nova
password = nova_pass
[libvirt]
[matchmaker_redis]
[metrics]
[mks]
[neutron]
[notifications]
[osapi_v21]
[oslo_concurrency]
lock_path=/var/lib/nova/tmp
[oslo_messaging_amqp]
[oslo_messaging_kafka]
[oslo_messaging_notifications]
[oslo_messaging_rabbit]
[oslo_messaging_zmq]
[oslo_middleware]
[oslo_policy]
[pci]
[placement]
region_name = RegionTest
project_domain_name = Default
project_name = service
auth_type = password
user_domain_name = Default
auth_url = http://controller:35357/v3
username = placement
password = placement_pass
[quota]
[rdp]
[remote_debug]
[scheduler]
[serial_console]
[service_user]
[spice]
[upgrade_levels]
[vault]
[vendordata_dynamic_auth]
[vmware]
[vnc]
enabled=true
server_listen=$my_ip
server_proxyclient_address=$my_ip
novncproxy_base_url=http://$my_ip:6080/vnc_auto.html
novncproxy_host=$my_ip
novncproxy_port=6080
[workarounds]
[wsgi]
[xenserver]
[xvp]
5. 配置00-nova-placement-api.conf
# 在全部控制节点操作,以controller01节点为例;
# 注意根据不同节点修改监听地址
[root@controller01 ~]# cp /etc/httpd/conf.d/00-nova-placement-api.conf /etc/httpd/conf.d/00-nova-placement-api.conf.bak
[root@controller01 ~]# sed -i "s/Listen\ 8778/Listen\ 172.30.200.31:8778/g" /etc/httpd/conf.d/00-nova-placement-api.conf
[root@controller01 ~]# sed -i "s/*:8778/172.30.200.31:8778/g" /etc/httpd/conf.d/00-nova-placement-api.conf
[root@controller01 ~]# echo " #Placement API
<Directory /usr/bin>
<IfVersion >= 2.4>
Require all granted
</IfVersion>
<IfVersion < 2.4>
Order allow,deny
Allow from all
</IfVersion>
</Directory>
" >> /etc/httpd/conf.d/00-nova-placement-api.conf # 重启httpd服务,启动placement-api监听端口
[root@controller01 ~]# systemctl restart httpd
6. 同步nova相关数据库
1)同步nova相关数据库
# 任意控制节点操作;
# 同步nova-api数据库
[root@controller01 ~]# su -s /bin/sh -c "nova-manage api_db sync" nova # 注册cell0数据库
[root@controller01 ~]# su -s /bin/sh -c "nova-manage cell_v2 map_cell0" nova # 创建cell1 cell
[root@controller01 ~]# su -s /bin/sh -c "nova-manage cell_v2 create_cell --name=cell1 --verbose" nova # 同步nova数据库;
# 忽略”deprecated”信息
[root@controller01 ~]# su -s /bin/sh -c "nova-manage db sync" nova

补充:
此版本在向数据库同步导入数据表时,报错:/usr/lib/python2.7/site-packages/oslo_db/sqlalchemy/enginefacade.py:332: NotSupportedWarning: Configuration option(s) ['use_tpool'] not supported
exception.NotSupportedWarning

解决方案如下:
bug:https://bugs.launchpad.net/nova/+bug/1746530
pacth:https://github.com/openstack/oslo.db/commit/c432d9e93884d6962592f6d19aaec3f8f66ac3a2
2)验证
# cell0与cell1注册正确
[root@controller01 ~]# nova-manage cell_v2 list_cells

# 查看数据表
[root@controller01 ~]# mysql -h controller01 -u nova -pnova_dbpass -e "use nova_api;show tables;"
[root@controller01 ~]# mysql -h controller01 -u nova -pnova_dbpass -e "use nova;show tables;"
[root@controller01 ~]# mysql -h controller01 -u nova -pnova_dbpass -e "use nova_cell0;show tables;"
7. 启动服务
# 在全部控制节点操作,以controller01节点为例;
# 开机启动
[root@controller01 ~]# systemctl enable openstack-nova-api.service \
openstack-nova-consoleauth.service \
openstack-nova-scheduler.service \
openstack-nova-conductor.service \
openstack-nova-novncproxy.service # 启动
[root@controller01 ~]# systemctl restart openstack-nova-api.service
[root@controller01 ~]# systemctl restart openstack-nova-consoleauth.service
[root@controller01 ~]# systemctl restart openstack-nova-scheduler.service
[root@controller01 ~]# systemctl restart openstack-nova-conductor.service
[root@controller01 ~]# systemctl restart openstack-nova-novncproxy.service # 查看状态
[root@controller01 ~]# systemctl status openstack-nova-api.service \
openstack-nova-consoleauth.service \
openstack-nova-scheduler.service \
openstack-nova-conductor.service \
openstack-nova-novncproxy.service # 查看端口
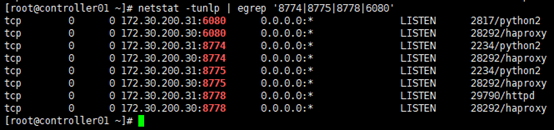
[root@controller01 ~]# netstat -tunlp | egrep '8774|8775|8778|6080'
8. 验证
[root@controller01 ~]# . admin-openrc # 列出各服务组件,查看状态;
# 也可使用命令” nova service-list”
[root@controller01 ~]# openstack compute service list
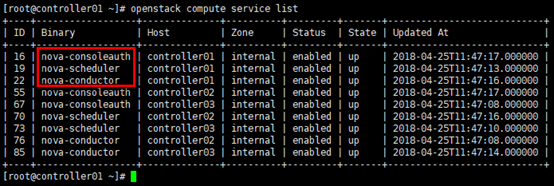
# 展示api端点
[root@controller01 ~]# openstack catalog list

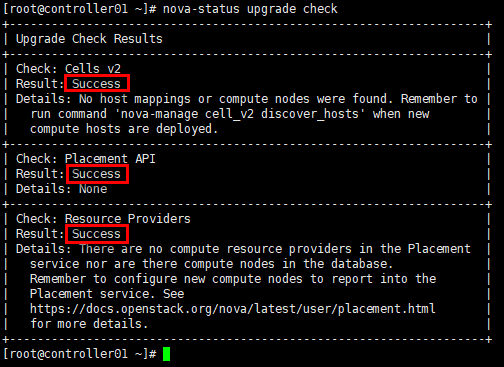
# 检查cell与placement api运行正常
[root@controller01 ~]# nova-status upgrade check
9. 设置pcs资源
# 在任意控制节点操作;
# 添加资源openstack-nova-api,openstack-nova-consoleauth,openstack-nova-scheduler,openstack-nova-conductor与openstack-nova-novncproxy
[root@controller01 ~]# pcs resource create openstack-nova-api systemd:openstack-nova-api --clone interleave=true
[root@controller01 ~]# pcs resource create openstack-nova-consoleauth systemd:openstack-nova-consoleauth --clone interleave=true
[root@controller01 ~]# pcs resource create openstack-nova-scheduler systemd:openstack-nova-scheduler --clone interleave=true
[root@controller01 ~]# pcs resource create openstack-nova-conductor systemd:openstack-nova-conductor --clone interleave=true
[root@controller01 ~]# pcs resource create openstack-nova-novncproxy systemd:openstack-nova-novncproxy --clone interleave=true # 经验证,建议openstack-nova-api,openstack-nova-consoleauth,openstack-nova-conductor与openstack-nova-novncproxy 等无状态服务以active/active模式运行;
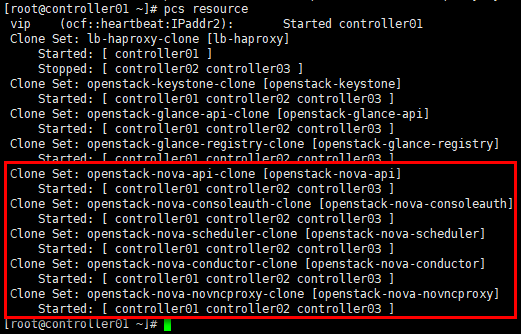
# openstack-nova-scheduler等服务以active/passive模式运行 # 查看pcs资源;
[root@controller01 ~]# pcs resource
高可用OpenStack(Queen版)集群-6.Nova控制节点集群的更多相关文章
- Nova控制节点集群
#Nova控制节点集群 openstack pike 部署 目录汇总 http://www.cnblogs.com/elvi/p/7613861.html ##Nova控制节点集群 # control ...
- 高可用OpenStack(Queen版)集群-9.Cinder控制节点集群
参考文档: Install-guide:https://docs.openstack.org/install-guide/ OpenStack High Availability Guide:http ...
- Neutron控制节点集群
#Neutron控制节点集群 openstack pike 部署 目录汇总 http://www.cnblogs.com/elvi/p/7613861.html #.Neutron控制节点集群 #本实 ...
- cinder控制节点集群
#cinder控制节点集群 openstack pike 部署 目录汇总 http://www.cnblogs.com/elvi/p/7613861.html #cinder块存储控制节点.txt.s ...
- 高可用OpenStack(Queen版)集群-3.高可用配置(pacemaker&haproxy)
参考文档: Install-guide:https://docs.openstack.org/install-guide/ OpenStack High Availability Guide:http ...
- openstack高可用集群21-生产环境高可用openstack集群部署记录
第一篇 集群概述 keepalived + haproxy +Rabbitmq集群+MariaDB Galera高可用集群 部署openstack时使用单个控制节点是非常危险的,这样就意味着单个节 ...
- Corosync+Pacemaker+DRBD+MySQL 实现高可用(HA)的MySQL集群
大纲一.前言二.环境准备三.Corosync 安装与配置四.Pacemaker 安装与配置五.DRBD 安装与配置六.MySQL 安装与配置七.crmsh 资源管理 推荐阅读: Linux 高可用(H ...
- 高可用,完全分布式Hadoop集群HDFS和MapReduce安装配置指南
原文:http://my.oschina.net/wstone/blog/365010#OSC_h3_13 (WJW)高可用,完全分布式Hadoop集群HDFS和MapReduce安装配置指南 [X] ...
- 用Kolla在阿里云部署10节点高可用OpenStack
为展现 Kolla 的真正实力,我在阿里云使用 Ansible 自动创建 10 台虚机,部署一套多节点高可用 OpenStack 集群! 前言 上次 Kolla 已经表示了要打 10 个的愿望,这次我 ...
随机推荐
- arcgis api for javascript本地部署加载地图
最近开始学习arcgis api for javascript,发现一头雾水,决定记录下自己的学习过程. 一.下载arcgis api for js 4.2的library和jdk,具体安装包可以去官 ...
- Core WebAPI 入门
官方文档地址 https://docs.microsoft.com/zh-cn/aspnet/?view=aspnetcore-2.2#pivot=core 使用 ASP.NET Core 构建 We ...
- active developer path ("/Applications/Xcode.app/Contents/Developer")
-> git xcrun: error: active developer path ("/Applications/Xcode.app/Contents/Developer" ...
- 2.编写实现:有一个三角形类Triangle,成员变量有底边x和另一条边y,和两边的夹角a(0<a<180),a为静态成员,成员方法有两个:求面积s(无参数)和修改角度(参数为角度)。 编写实现: 构造函数为 Triangle(int xx,int yy,int aa) 参数分别为x,y,a赋值 在main方法中构造两个对象,求出其面积,然后使用修改角度的方法,修改两边的夹角,再求出面积值。(提示
求高的方法 h=y*Math.sin(a) 按题目要求,需要我们做的分别是:1.改角度2.显示角度3.求面积并显示 代码用到:1.静态成员变量以修改角度2.数学函数 以下具体代码具体分析 import ...
- Spring源码分析(十二)FactoryBean的使用
摘要:本文结合<Spring源码深度解析>来分析Spring 5.0.6版本的源代码.若有描述错误之处,欢迎指正. 一般情况下,Spring通过反射机制利用bean的class属性指定实现 ...
- 细数用anaconda安装mayavi时出现的各种问题
这段时间需要利用mayavi做科学数据的处理,因此需要利用到mayavi库,但是官网上面的指示说:如果安装了anaconda,其中自带各种科学库,但是实践中,并没有发现mayavi. 官方网站导航:m ...
- Hadoop源码学习笔记之NameNode启动场景流程一:源码环境搭建和项目模块及NameNode结构简单介绍
最近在跟着一个大佬学习Hadoop底层源码及架构等知识点,觉得有必要记录下来这个学习过程.想到了这个废弃已久的blog账号,决定重新开始更新. 主要分以下几步来进行源码学习: 一.搭建源码阅读环境二. ...
- 自学tensorflow——2.使用tensorflow计算线性回归模型
废话不多说,直接开始 1.首先,导入所需的模块: import numpy as np import os import tensorflow as tf 关闭tensorflow输出的一大堆硬件信息 ...
- 函数的返回值是void
#include <stdio.h> void sub(int x,int y,int z){ z=y-x; } void main() { int a=1,b=2,c=3; sub(10 ...
- RabbitMQ(三):消息持久化策略
原文:RabbitMQ(三):消息持久化策略 一.前言 在正常的服务器运行过程中,时常会面临服务器宕机重启的情况,那么我们的消息此时会如何呢?很不幸的事情就是,我们的消息可能会消失,这肯定不是我们希望 ...