从源码看Azkaban作业流下发过程
上一篇零散地罗列了看源码时记录的一些类的信息,这篇完整介绍一个作业流在Azkaban中的执行过程,希望可以帮助刚刚接手Azkaban相关工作的开发、测试。
一、Azkaban简介
Azkaban作为开源的调度系统,在大数据中有广泛地使用。它主要有三部分组成:Azkaban Webserver、Azkaban Executor、 DB。
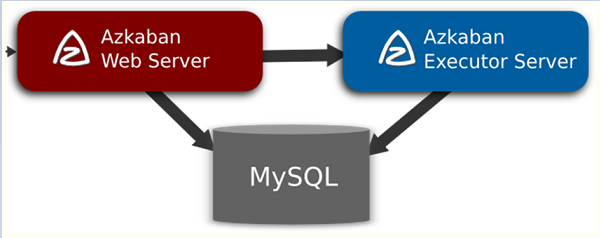
图1 Azkaban架构
图1所示的是Azkaban的基本架构:Webserver主要负责权限验证、项目管理、作业流下发等工作;Executor主要负责作业流/作业的具体执行以及搜集执行日志等工作;MySQL用于存储作业/作业流的执行状态信息。图中所示的是单executor场景,但是实际应用中大部分的项目使用的都是多executor场景。下面主要介绍多executor场景下的azkaban调度过程。
二、作业流执行过程
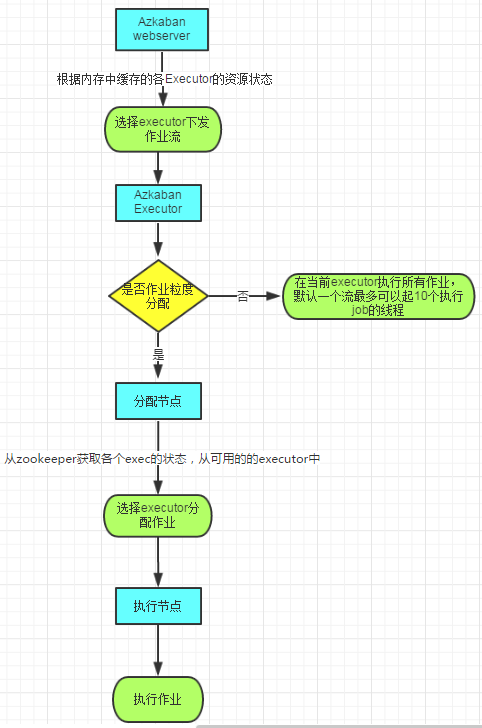
图2 作业流执行过程
图2展示的就是Azkaban作业流的执行过程:
1. 首先Webserver根据内存中缓存的各Executor的资源状态(Webserver有一个线程会遍历各个active executor,去发送http请求获取其资源状态信息缓存到内存中),按照选择策略(包括executor资源状态、最近执行流个数等)选择一个executor下发作业流;
2. 然后executor判断是否设置作业粒度分配,如果未设置作业粒度分配,则在当前executor执行所有作业;
3. 如果设置了作业粒度分配,则当前节点会成为作业分配的决策者,即分配节点;
4. 分配节点从zookeeper获取各个executor的资源状态信息,然后根据策略选择一个executor分配作业;
5. 被分配到作业的executor即成为执行节点,执行作业,然后更新数据库。
三、从源码看作业流执行过程
首先是Webserver端:
1. ExecutorServlet类根据请求的ajax参数判断,如果ajax=executeFlow,就去调ajaxAttemptExecuteFlow(req, resp, ret, session.getUser())方法
2. ajaxAttemptExecuteFlow方法里,首先调getProjectAjaxByPermission方法判断用户是否有执行权限,如果验证权限通过,且Project和Flow都存在,就调ajaxExecuteFlow方法
3. ajaxExecuteFlow方法的主要作用就是构造ExecutableFlow对象,设定执行参数(通知机制,并发,失败策略),然后去调executorManager.submitExecutableFlow方法
4. executorManager.submitExecutableFlow方法:判断执行策略(流水线、忽略、并发);如果是多执行节点模式,则将作业流提交到执行队列queue;如果是单执行节点模式,选择唯一执行节点下发作业流。
5. ExecutorManager.submitExecutableFlow()方法是Webserver端下发作业流的主要实现逻辑,下面重点细述其内容:
5.1 从exflow实例获取作业流的flowId(就是作业流的名字),打日志(“开始提交流XXX by 某某某了”)。
5.2 判断queuedFlows是否满,如果满了打日志(“提交失败,Azkaban过饱和啦”),return;如果未满,继续往下执行代码
5.3 获取该作业流所有正在跑的实例的id, List<Integer> running
5.4 获取执行设置options
5.5 从执行设置options里获取流的执行参数(是否enable,是则将参数生效)
5.6 判断running是否为空,如果为空,即没有并发的实例在跑
5.7 如果running不为空,获取并发设置getConcurrentOption()
5.7.1 流水线(pipeline):设置pipelineExcutionId为running中最后提交的实例id
5.7.2 忽略(skip):抛异常,“流已经在执行了,忽略本次执行”
5.7.3 并发(ignore):仅修改日志
5.8 根据白名单设置是否memoryCheck
5.9 executorLoader.uploadExecutableFlow(exflow) 写数据库表execution_flows,状态为preparing
5.10 构造具体的执行实例ExecutionReference
5.11 判断是否多执行节点模式,如果不是,将该执行流的状态标记为active,即写数据库表active_executing_flows,将流dispatch到唯一执行节点执行。
5.12 如果是多执行节点模式,则将该执行流的状态标记为active,然后将流放入执行队列queuedFlows。
6. 如果是多执行节点模式,ExecutorManager类在构造函数里会调setupMultiExecutorMode()方法,该方法会建一个线程通过processQueuedFlows方法去持续地消费队列里的首个作业流。processQueuedFlows方法的主要内容就是按照一定规则去refreshExecutors刷新执行节点的资源信息,以及selectExecutorAndDispatchFlow从activeExecutors中根据策略选择一个executor下发作业流。refreshExecutors()方法实际上是通过遍历每个active executor,去发请求获取状态信息,而不是通过zookeeper。
至此,Webserver端的工作已经完毕。
然后是Executor端:
1. 执行流到达Executor端,此时在数据库中的状态已经是preparing
2. ExecutorServlet类根据请求的action参数判断,如果action=execute,就去调handleAjaxExecute(req, respMap, execid)方法
3. handleAjaxExecute方法里执行flowRunnerManager.submitFlow(execId),去调FlowRunnerManager的submitFlow(execId)方法来提交执行流。
4. FlowRunnerManager的两个重要的数据结构:
4.1 Map<Future<?>, Integer> submittedFlows = new ConcurrentHashMap<Future<?>, Integer>();
4.2 Map<Integer, FlowRunner> runningFlows = new ConcurrentHashMap<Integer, FlowRunner>();
submittedFlows用于跟踪当前executor所有处于preparing状态的流的执行;runningFlows用于存数当前executor所有正在执行的流的信息,当需要执行cancling()或killing()的时候就可以找到这些流。
5. FlowRunnerManager.submitFlow(execId)方法是Executor端执行作业流的主要实现逻辑,下面重点细述其内容:
5.1 先判断runningFlows是否包含该execId对应的实例,如果已经包含,抛异常
5.2 从executorLoader去获取execId对应的执行实例(ExecutableFlow)flow
5.3 执行setupFlow(flow),配置flow:创建项目和执行的目录等
5.4 获取执行设置ExecutionOptions
5.5 判断pipelineExecId是否为null。如果不为null,就判断pipelineExecId对应的flowRunner在不在runningFlows中。如果在runningFlows中,起一个LocalFlowWatcher去监控在flow中各个job的执行状态;
5.6 如果不在runningFlows中,起一个RemoteFlowWatcher去监控,即每隔一定时间(默认为60秒)通过读取数据库的记录来监控流中各个job的状态
5.7 判断执行参数里是否包含flow.num.job.threads,如果存在且小于默认值10,则修改该值。这个值代表该流可以同时执行的job线程数。
5.8 构造一个新的FlowRunner实例runner
5.9 configureFlowLevelMetrics(runner)配置runner
5.10 再次判断runningFlows是否包含该次execId对应的执行实例,如果包含,抛异常
5.11 将runner加入到runningFlows的map
5.12 提交到TrackingThreadPool(工作线程池)
5.13 加入到submittedFlows的map
6. 自此,我们就有了FlowRunner实例,下面我们看FlowRunner中都干了些什么事。
FlowRunner其实就是一个线程,它的run()方法的内容如下:
6.1 Executors.newFixedThreadPool(numJobThreads) 创建flow内部job线程池flow
6.2 setupFlowExecution()
6.3 updateFlowReference()
6.4 updateFlow() 更新flow的状态信息,写数据库表execution_flows
6.5 loadAllProperties()载入job参数和共享的参数
6.6 判断输入参数是否包含job.dispatch(作业粒度分配),如果包含且为true,起一个新的线程jobEventUpdaterThread,用于跟踪该作业流下各个作业的执行状态。
6.7 执行runFlow()
6.8 runFlow()方法:根据DAG图的算法依次执行job。从流的开始节点,递归调用runReadyjob()来执行作业,然后updateFlow();如果流还没结束,根据重试设置,决定是否重跑失败的作业。
6.9 在runReadyjob()里会调runExecutableNode(node)方法,runExecutableNode方法再判断job.dispatch参数,如果为false,则通过LocalJobRunner本地执行;如果为true,则再通过JobRunnerManager提交作业。
6.10 JobRunnerManager通过submitExecutableNode方法构建RemoteJobRunner,RemoteJobRunner会根据各执行节点(包含本节点)的资源状态去选择一个节点执行作业。
最后,整个过程可以总结成一个图,如下图所示:
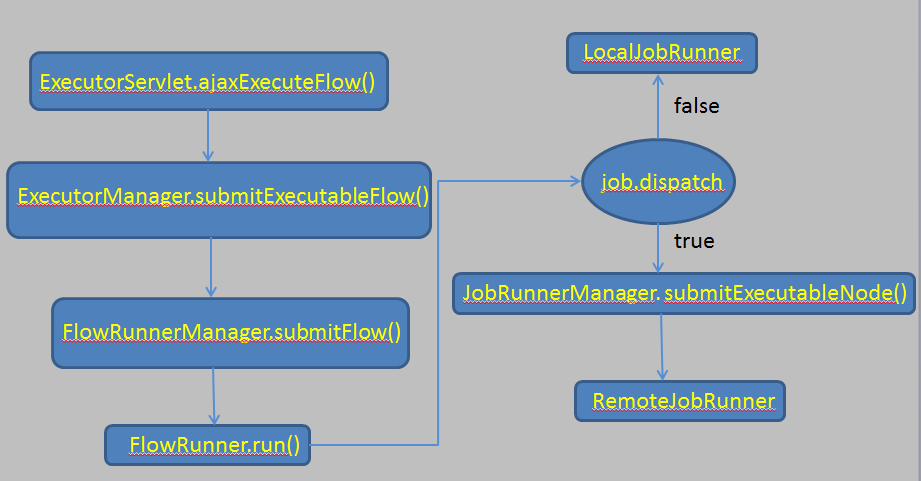
图3 从源码看作业流执行过程
从源码看Azkaban作业流下发过程的更多相关文章
- Android so 文件进阶<二> 从dlsym()源码看android 动态链接过程
0x00 前言 这篇文章其实是我之前学习elf文件关于符号表的学习笔记,网上也有很多关于符号表的文章,怎么说呢,感觉像是在翻译elf文件格式的文档一样,千篇一律,因此把自己的学习笔记分享出来.dls ...
- 解密随机数生成器(二)——从java源码看线性同余算法
Random Java中的Random类生成的是伪随机数,使用的是48-bit的种子,然后调用一个linear congruential formula线性同余方程(Donald Knuth的编程艺术 ...
- 从Chrome源码看浏览器的事件机制
.aligncenter { clear: both; display: block; margin-left: auto; margin-right: auto } .crayon-line spa ...
- 从Chrome源码看JS Array的实现
.aligncenter { clear: both; display: block; margin-left: auto; margin-right: auto } .crayon-line spa ...
- tomcat8 源码分析 | 组件及启动过程
tomcat 8 源码分析 ,本文主要讲解tomcat拥有哪些组件,容器,又是如何启动的 推荐访问我的个人网站,排版更好看呦: https://chenmingyu.top/tomcat-source ...
- 【Spring源码解析】—— 结合SpringMVC过程理解IOC容器初始化
关于IOC容器的初始化,结合之前SpringMVC的demo,对其过程进行一个相对详细的梳理,主要分为几个部分: 一.IOC的初始化过程,结合代码和debug过程重点说明 1. 为什么要debug? ...
- MyBatis 源码分析 - 映射文件解析过程
1.简介 在上一篇文章中,我详细分析了 MyBatis 配置文件的解析过程.由于上一篇文章的篇幅比较大,加之映射文件解析过程也比较复杂的原因.所以我将映射文件解析过程的分析内容从上一篇文章中抽取出来, ...
- 从微信小程序开发者工具源码看实现原理(一)- - 小程序架构设计
使用微信小程序开发已经很长时间了,对小程序开发已经相当熟练了:但是作为一名对技术有追求的前端开发,仅仅熟练掌握小程序的开发感觉还是不够的,我们应该更进一步的去理解其背后实现的原理以及对应的考量,这可能 ...
- 从微信小程序开发者工具源码看实现原理(四)- - 自适应布局
从前面从微信小程序开发者工具源码看实现原理(一)- - 小程序架构设计可以知道,小程序大部分是通过web技术进行渲染的,也就是最终通过浏览器的dom tree + cssom来生成渲染树:既然最终是通 ...
随机推荐
- 在PowerShell中使用curl(Invoke-WebRequest)
前言 习惯了windows的界面模式就很难转去命令行,甚至以命令行发家的git也涌现出各种界面tool.然而命令行真的会比界面快的多,如果你是一个码农. situation:接到需求分析bug,需要访 ...
- 在Ubuntu 16.10安装mysql workbench报未安装软件包 libpng12-0错误
1.安装mysql workbench,提示未安装软件包 libpng12-0 下载了MySQL Workbench 6.3.8 在安装的时候报错: -1ubu1604-amd64.deb 提示: ...
- LeetCode[5] 最长的回文子串
题目描述 Given a string S, find the longest palindromic substring in S. You may assume that the maximum ...
- 【Web动画】SVG 实现复杂线条动画
在上一篇文章中,我们初步实现了一些利用基本图形就能完成的线条动画: [Web动画]SVG 线条动画入门 当然,事物都是朝着熵增焓减的方向发展的,复杂线条也肯定比有序线条要多. 很多时候,我们无法人工去 ...
- TortoiseGit 文件比对工具使用 Beyond Compare 和 DiffMerge
TortoiseGit 内置的文件比对工具是 TortoiseMerge,用于文件比对和解决冲突合并,TortoiseGit 还支持外部的比对工具使用,比如 Beyond Compare 和 Diff ...
- 微信小程序IDE(微信web开发者工具)安装、破解手册
1.IDE下载 微信web开发者工具,本人是用的windows 10 x64系统,用到以下两个版本的IDE安装工具与一个破解工具包: wechat_web_devtools_0.7.0_x64.exe ...
- 值得注意的ibatis动态sql语法格式
一.Ibatis常用动态sql语法,简单粗暴用一例子 <select id="iBatisSelectList" parameterClass="java.util ...
- BPM SharePoint解决方案分享
一.需求分析 SharePoint作为微软推出的协同类平台产品,为客户提供了门户.内容.文档.流程.社区.搜索.BI等一系列的解决方案,然而其流程功能由于设计理念差异,不能完全满足客户的需求,主要原因 ...
- Android 关于ijkplayer
基于ijkplayer封装支持简单界面UI定制的视频播放器 可以解析ts格式的so库 怎样编译出可以解析ts等格式的so库?就是编译的时候需要在哪一步修改配置? 一些电视台的m3u8 CCTV1综合, ...
- listview下拉刷新和上拉加载更多的多种实现方案
listview经常结合下来刷新和上拉加载更多使用,本文总结了三种常用到的方案分别作出说明. 方案一:添加头布局和脚布局 android系统为listview提供了addfootview ...