高可用OpenStack(Queen版)集群-12.Cinder计算节点
参考文档:
- Install-guide:https://docs.openstack.org/install-guide/
- OpenStack High Availability Guide:https://docs.openstack.org/ha-guide/index.html
- 理解Pacemaker:http://www.cnblogs.com/sammyliu/p/5025362.html
十六.Cinder计算节点
在采用ceph或其他商业/非商业后端存储时,建议将cinder-volume服务部署在控制节点,通过pacemaker将服务运行在active/passive模式。
以下配置文件可供参考,但部署模式(经验证后发现)并不是"最佳"实践。
1. 安装cinder
# 在全部计算点安装cinder服务,以compute01节点为例
[root@compute02 ~]# yum install -y openstack-cinder targetcli python-keystone
2. 配置cinder.conf
# 在全部计算点操作,以compute01节点为例;
# 注意”my_ip”参数,根据节点修改;
# 注意cinder.conf文件的权限:root:cinder
[root@compute01 ~]# cp /etc/cinder/cinder.conf /etc/cinder/cinder.conf.bak
[root@compute01 ~]# egrep -v "^$|^#" /etc/cinder/cinder.conf
[DEFAULT]
state_path = /var/lib/cinder
my_ip = 172.30.200.41
glance_api_servers = http://controller:9292
auth_strategy = keystone
# 简单的将cinder理解为存储的机头,后端可以采用nfs,ceph等共享存储
enabled_backends = ceph
# 前端采用haproxy时,服务连接rabbitmq会出现连接超时重连的情况,可通过各服务与rabbitmq的日志查看;
# transport_url = rabbit://openstack:rabbitmq_pass@controller:5673
# rabbitmq本身具备集群机制,官方文档建议直接连接rabbitmq集群;但采用此方式时服务启动有时会报错,原因不明;如果没有此现象,强烈建议连接rabbitmq直接对接集群而非通过前端haproxy
transport_url=rabbit://openstack:rabbitmq_pass@controller01:5672,controller02:5672,controller03:5672
[backend]
[backend_defaults]
[barbican]
[brcd_fabric_example]
[cisco_fabric_example]
[coordination]
[cors]
[database]
connection = mysql+pymysql://cinder:cinder_dbpass@controller/cinder
[fc-zone-manager]
[healthcheck]
[key_manager]
[keystone_authtoken]
www_authenticate_uri = http://controller:5000
auth_url = http://controller:35357
memcached_servers = controller01:11211,controller02:11211,controller03:11211
auth_type = password
project_domain_id = default
user_domain_id = default
project_name = service
username = cinder
password = cinder_pass
[matchmaker_redis]
[nova]
[oslo_concurrency]
lock_path = $state_path/tmp
[oslo_messaging_amqp]
[oslo_messaging_kafka]
[oslo_messaging_notifications]
[oslo_messaging_rabbit]
[oslo_messaging_zmq]
[oslo_middleware]
[oslo_policy]
[oslo_reports]
[oslo_versionedobjects]
[profiler]
[service_user]
[ssl]
[vault]
3. 启动服务
# 在全部计算点操作;
# 开机启动
[root@compute01 ~]# systemctl enable openstack-cinder-volume.service target.service # 启动
[root@compute01 ~]# systemctl restart openstack-cinder-volume.service
[root@compute01 ~]# systemctl restart target.service
4. 验证
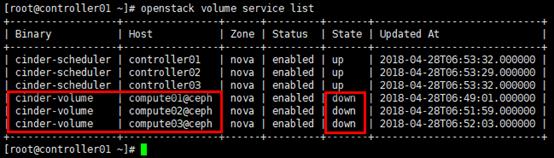
# 在任意控制节点(或具备客户端的节点)操作
[root@controller01 ~]# . admin-openrc # 查看agent服务;
# 或:cinder service-list;
# 此时后端存储服务为ceph,但ceph相关服务尚未启用并集成到cinder-volume,导致cinder-volume服务的状态也是”down”
[root@controller01 ~]# openstack volume service list
高可用OpenStack(Queen版)集群-12.Cinder计算节点的更多相关文章
- Corosync+Pacemaker+DRBD+MySQL 实现高可用(HA)的MySQL集群
大纲一.前言二.环境准备三.Corosync 安装与配置四.Pacemaker 安装与配置五.DRBD 安装与配置六.MySQL 安装与配置七.crmsh 资源管理 推荐阅读: Linux 高可用(H ...
- 高可用,完全分布式Hadoop集群HDFS和MapReduce安装配置指南
原文:http://my.oschina.net/wstone/blog/365010#OSC_h3_13 (WJW)高可用,完全分布式Hadoop集群HDFS和MapReduce安装配置指南 [X] ...
- 通过LVS+Keepalived搭建高可用的负载均衡集群系统
1. 安装LVS软件 (1)安装前准备操作系统:统一采用Centos6.5版本,地址规划如下: 服务器名 IP地址 网关 虚拟设备名 虚拟ip Director Server 192.168 ...
- 超详细干货!Docker+PXC+Haproxy搭建高可用强一致性的MySQL集群
前言 干货又来了,全程无废话,可先看目录了解. MySQL搭建集群最常见的是binlog方式,但还有一种方式是强一致性的,能保证集群节点的数据一定能够同步成功,这种方式就是pxc,本篇就使用图文方式一 ...
- 16套java架构师,高并发,高可用,高性能,集群,大型分布式电商项目实战视频教程
16套Java架构师,集群,高可用,高可扩展,高性能,高并发,性能优化,设计模式,数据结构,虚拟机,微服务架构,日志分析,工作流,Jvm,Dubbo ,Spring boot,Spring cloud ...
- Redis高可用方案-哨兵与集群
Redis高可用方案 一.名词解释 二.主从复制 Redis主从复制模式可以将主节点的数据同步给从节点,从而保障当主节点不可达的情况下,从节点可以作为 后备顶上来,并且可以保障数据尽量不丢失(主从 ...
- CentOS7安装OpenStack(Rocky版)-05.安装一个nova计算节点实例
上一篇文章分享了控制节点的nova计算服务的安装方法,在实际生产环境中,计算节点通常会安装一些单独的节点提供服务,本文分享单独的nova计算节点的安装方法 ---------------- 完美的分 ...
- openstack Q版部署-----nova服务配置-计算节点(6)
一.服务安装(计算节点) 安装软件: yum install openstack-nova-compute -y 编辑/etc/nova/nova.conf文件并设置如下内容: [DEFAULT] e ...
- 高可用OpenStack(Queen版)集群-11.Neutron计算节点
参考文档: Install-guide:https://docs.openstack.org/install-guide/ OpenStack High Availability Guide:http ...
随机推荐
- BZOJ1434:[ZJOI2009]染色游戏(博弈论)
Description 一共n×m个硬币,摆成n×m的长方形.dongdong和xixi玩一个游戏,每次可以选择一个连通块,并把其中的硬币全部翻转,但是需要满足存在一个硬币属于这个连通块并且所有其他硬 ...
- PAT乙级1020
1020 月饼 (25 分) 月饼是中国人在中秋佳节时吃的一种传统食品,不同地区有许多不同风味的月饼.现给定所有种类月饼的库存量.总售价.以及市场的最大需求量,请你计算可以获得的最大收益是多少. ...
- chrome浏览器使用jqprint插件打印时偶尔空白页问题
最近测试老是提bug说是有50%的概率打印出空白页,之前我也一直发现偶尔会出现这个问题,只是一直没有发现原因. 今天终于下定决心找到问题所在.开始吧! 查看源码一行行debug,发现问题只可能出现在这 ...
- u-boot-1.1.6实现自定义命令
学习目标: 1.了解u-boot-1.1.6中命令的实现机制 2.掌握如何在u-boot-1.1.6中添加自定义命令 1.命令的实现机制 uboot运行在命令行解析模式时,在串口终端输入uboot命令 ...
- STM32 HAL库学习系列第1篇 ADC配置 及 DAC配置
ADC工作均为非阻塞状态 轮询模式 中断模式 DMA模式 库函数: HAL_StatusTypeDef HAL_ADC_Start(ADC_HandleTypeDef* hadc);//轮询模式,需放 ...
- 菜鸟成长心酸史之php初遇教程
phpstorm是我接触到的第二个制作网页的程序,刚拿到php的时候,我是懵逼的,从安装到使用,可以说一点都不会,尤其是它还要配合wampsever使用,即使看视频,不同的制作php的软件也有不同的地 ...
- GoLang 命令
目录 查看可用命令 build 和 run 命令 go build编译时的附加参数 clent命令 fmt 和 doc 命令 get 命令 远程包的路径格式 go get+远程包 go get使用时的 ...
- 开发自己的DataSet查看器
记得在vs2002不是2003上没有DataSet调试器,断点时查看DataSet内容非常麻烦,最后有人开发了第三方工具解决了此问题. 后续的vs版本内部都自带的此工具可查看DataSet/DataT ...
- Visual Studio 2010 Express for Windows Phone 永久免费序列号
Visual Studio 2010 Express for Windows Phone 永久免费序列号:YDK44-2WW9W-QV7PM-8P8G8-FTYDF
- 20155238 《Java程序设计》实验一(Java开发环境的熟悉)实验报告
实验内容 使用JDK编译.运行简单的Java程序. 使用Eclipse 编辑.编译.运行.调试Java程序. 实现学生成绩管理功能,并进行测试. 实验步骤及结果 (一)命令行下Java程序开发 编译运 ...