python3+selenium3+requests爬取我的博客粉丝的名称
爬取目标
1.本次代码是在python3上运行通过的
- selenium3 +firefox59.0.1(最新)
- BeautifulSoup
- requests
2.爬取目标网站,我的博客:https://home.cnblogs.com/u/lxs1314
爬取内容:爬我的博客的所有粉丝的名称,并保存到txt
3.由于博客园的登录是需要人机验证的,所以是无法直接用账号密码登录,需借助selenium登录
直接贴代码:
# coding:utf-8
# __author__ = 'Carry' import requests
from selenium import webdriver
from bs4 import BeautifulSoup
import re
import time # firefox浏览器配置文件地址
profile_directory = r'C:\Users\Administrator\AppData\Roaming\Mozilla\Firefox\Profiles\pxp74n2x.default' s = requests.session() # 新建session
url = "https://home.cnblogs.com/u/lxs1314" def get_cookies(url):
'''启动selenium获取登录的cookies'''
# 加载配置
profile = webdriver.FirefoxProfile(profile_directory)
# 启动浏览器配置
driver = webdriver.Firefox(profile)
driver.get(url+"/followers") time.sleep(3)
cookies = driver.get_cookies() # 获取浏览器cookies
print(cookies)
driver.quit()
return cookies def add_cookies(cookies):
'''往session添加cookies'''
# 添加cookies到CookieJar
c = requests.cookies.RequestsCookieJar()
for i in cookies:
c.set(i["name"], i['value']) s.cookies.update(c) # 更新session里cookies def get_ye_nub(url):
# 发请求
r1 = s.get(url+"/relation/followers")
soup = BeautifulSoup(r1.content, "html.parser")
# 抓取我的粉丝数
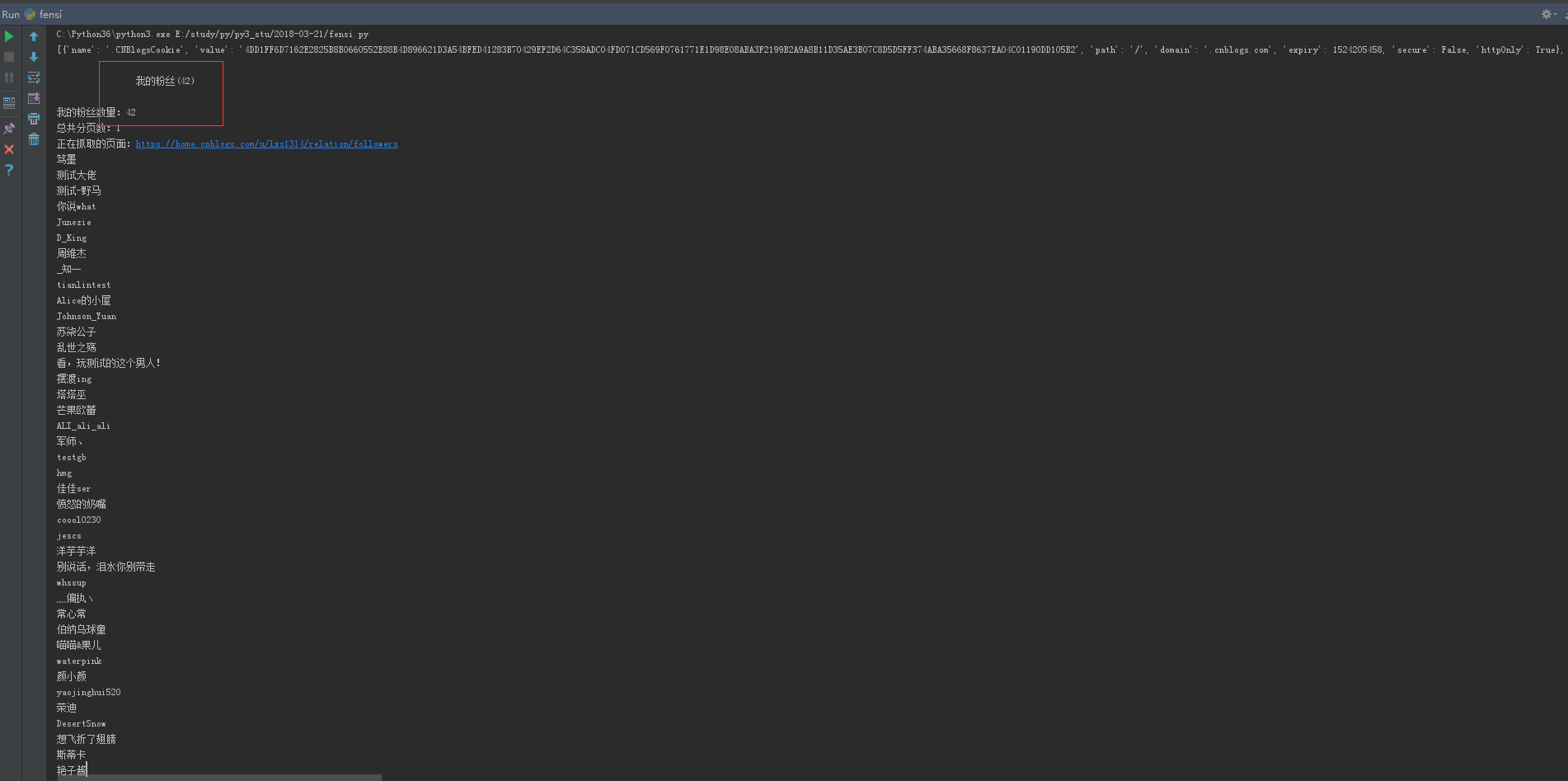
fensinub = soup.find_all(class_="current_nav")
print (fensinub[0].string)
num = re.findall(u"我的粉丝\((.+?)\)", fensinub[0].string)
print (u"我的粉丝数量:%s"%str(num[0])) # 计算有多少页,每页45条
ye = int(int(num[0])/45)+1
print (u"总共分页数:%s"%str(ye))
return ye def save_name(nub):
# 抓取第一页的数据
if nub <= 1:
url_page = url+"/relation/followers"
else:
url_page = url+"/relation/followers?page=%s" % str(nub)
print (u"正在抓取的页面:%s" %url_page)
r2 = s.get(url_page)
soup = BeautifulSoup(r2.content, "html.parser")
fensi = soup.find_all(class_="avatar_name")
for i in fensi:
name = i.string.replace("\n", "").replace(" ","")
print (name)
with open("name.txt", "a") as f: # 追加写入
f.write(name+"\n")
#name.encode("utf-8") if __name__ == "__main__":
cookies = get_cookies(url)
add_cookies(cookies)
n = get_ye_nub(url)
for i in range(1, n+1):
save_name(i)
原文链接:http://www.cnblogs.com/yoyoketang/p/8610779.html
python3+selenium3+requests爬取我的博客粉丝的名称的更多相关文章
- python+selenium+requests爬取我的博客粉丝的名称
爬取目标 1.本次代码是在python2上运行通过的,python3的最需改2行代码,用到其它python模块 selenium 2.53.6 +firefox 44 BeautifulSoup re ...
- Python爬虫小实践:爬取任意CSDN博客所有文章的文字内容(或可改写为保存其他的元素),间接增加博客访问量
Python并不是我的主业,当初学Python主要是为了学爬虫,以为自己觉得能够从网上爬东西是一件非常神奇又是一件非常有用的事情,因为我们可以获取一些方面的数据或者其他的东西,反正各有用处. 这两天闲 ...
- Scrapy爬取自己的博客内容
python中常用的写爬虫的库有urllib2.requests,对于大多数比较简单的场景或者以学习为目的,可以用这两个库实现.这里有一篇我之前写过的用urllib2+BeautifulSoup做的一 ...
- python3使用requests爬取新浪热门微博
微博登录的实现代码来源:https://gist.github.com/mrluanma/3621775 相关环境 使用的python3.4,发现配置好环境后可以直接使用pip easy_instal ...
- 开发记录_自学Python写爬虫程序爬取csdn个人博客信息
每天刷开csdn的博客,看到一整个页面,其实对我而言,我只想看看访问量有没有上涨而已... 于是萌生了一个想法: 想写一个爬虫程序把csdn博客上边的访问量和评论数都爬下来. 打算通过网络各种搜集资料 ...
- step2: 爬取廖雪峰博客
#https://zhuanlan.zhihu.com/p/26342933 #https://zhuanlan.zhihu.com/p/26833760 scrapy startproject li ...
- scrapy 爬取自己的博客
定义项目 # -*- coding: utf-8 -*- # items.py import scrapy class LianxiCnblogsItem(scrapy.Item): # define ...
- requests爬取百度音乐
使用requests爬取百度音乐,我想把当前热门歌手的音乐信息爬下来. 首先进行url分析,可以看到: 歌手网页: 薛之谦网页: 可以看到,似乎这些路劲的获取一切都很顺利,然后可以写代码: # -*- ...
- Python爬虫入门——使用requests爬取python岗位招聘数据
爬虫目的 使用requests库和BeautifulSoup4库来爬取拉勾网Python相关岗位数据 爬虫工具 使用Requests库发送http请求,然后用BeautifulSoup库解析HTML文 ...
随机推荐
- java基础解析系列(三)---HashMap
java基础解析系列(三)---HashMap java基础解析系列 java基础解析系列(一)---String.StringBuffer.StringBuilder java基础解析系列(二)-- ...
- 「专题训练」Collecting Bugs(POJ-2096)
题意与分析 题意大致是这样的:给定一个\(n\times s\)的矩阵,每次可以随机的在这个矩阵内给一个格子染色(染过色的仍然可能被选中),问每一行和每一列都有格子被染色的次数的期望. 这题如果从概率 ...
- 浅谈HTTP中GET和POST请求方式的区别
浅谈HTTP中GET和POST请求的区别 HTTP认知: HTTP是基于TCP/IP的关于数据如何在万维网中如何通信的协议.HTTP的底层是TCP/IP.所以GET和POST的底层也是TCP/IP,也 ...
- WebGL——osg框架学习四
这篇我们接着来看一下DrawEntityActor类,我们来看看这个继承DrawActor的类到底做了什么事.我们之前学习了Drawable对应的DrawActor,那么我们类比的来看Drawable ...
- hashCode及HashMap中的hash()函数
一.hashcode是什么 要理解hashcode首先要理解hash表这个概念 1. 哈希表 hash表也称散列表(Hash table),是根据关键码值(Key value)而直接进行访问的数据结构 ...
- Scikit-learn数据变换
转载自:https://blog.csdn.net/Dream_angel_Z/article/details/49406573 本文主要是对照scikit-learn的preprocessing章节 ...
- [译文]c#扩展方法(Extension Method In C#)
原文链接: https://www.codeproject.com/Tips/709310/Extension-Method-In-Csharp 介绍 扩展方法是C# 3.0引入的新特性.扩展方法使你 ...
- django_models_Meta字段详解
Django模型类的Meta是一个内部类,它用于定义一些Django模型类的行为特性.而可用的选项大致包含以下几类 abstract 这个属性是定义当前的模型是不是一个抽象类.所谓抽象类是不会对应数据 ...
- 跟踪调试Linux内核的启动过程
跟踪调试Linux内核的启动过程---使用gdb 符钰婧 原创作品转载请注明出处 <Linux内核分析>MOOC课程http://mooc.study.163.com/course/UST ...
- JAVA开发环境的熟悉
北京电子科技学院(BESTI) 实 验 报 告 课程:Java程序设计 班级:1352 姓名:马悦 学号:20135235 成绩: 指导教师:娄嘉鹏 实验日期:2015.4.13 实验密级: 预习程度 ...