Hive学习之路 (十七)Hive分析窗口函数(五) GROUPING SETS、GROUPING__ID、CUBE和ROLLUP
概述
GROUPING SETS,GROUPING__ID,CUBE,ROLLUP
这几个分析函数通常用于OLAP中,不能累加,而且需要根据不同维度上钻和下钻的指标统计,比如,分小时、天、月的UV数。
数据准备
数据格式
2015-03,2015-03-10,cookie1
2015-03,2015-03-10,cookie5
2015-03,2015-03-12,cookie7
2015-04,2015-04-12,cookie3
2015-04,2015-04-13,cookie2
2015-04,2015-04-13,cookie4
2015-04,2015-04-16,cookie4
2015-03,2015-03-10,cookie2
2015-03,2015-03-10,cookie3
2015-04,2015-04-12,cookie5
2015-04,2015-04-13,cookie6
2015-04,2015-04-15,cookie3
2015-04,2015-04-15,cookie2
2015-04,2015-04-16,cookie1
创建表
use cookie;
drop table if exists cookie5;
create table cookie5(month string, day string, cookieid string)
row format delimited fields terminated by ',';
load data local inpath "/home/hadoop/cookie5.txt" into table cookie5;
select * from cookie5;
玩一玩GROUPING SETS和GROUPING__ID
说明
在一个GROUP BY查询中,根据不同的维度组合进行聚合,等价于将不同维度的GROUP BY结果集进行UNION ALL
GROUPING__ID,表示结果属于哪一个分组集合。
查询语句
select
month,
day,
count(distinct cookieid) as uv,
GROUPING__ID
from cookie.cookie5
group by month,day
grouping sets (month,day)
order by GROUPING__ID;
等价于
SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID FROM cookie5 GROUP BY month
UNION ALL
SELECT NULL,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID FROM cookie5 GROUP BY day
查询结果
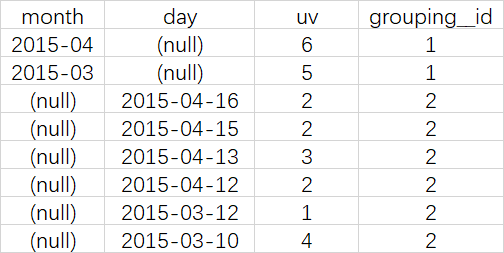
结果说明
第一列是按照month进行分组
第二列是按照day进行分组
第三列是按照month或day分组是,统计这一组有几个不同的cookieid
第四列grouping_id表示这一组结果属于哪个分组集合,根据grouping sets中的分组条件month,day,1是代表month,2是代表day
再比如
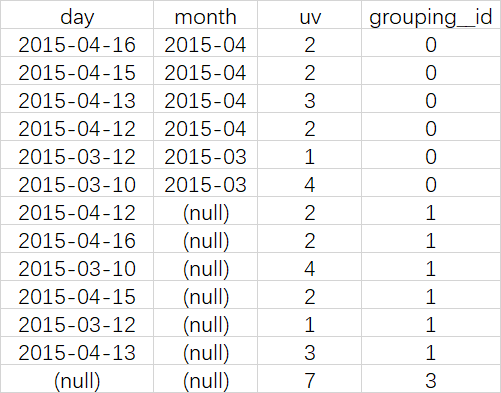
SELECT month, day,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM cookie5
GROUP BY month,day
GROUPING SETS (month,day,(month,day))
ORDER BY GROUPING__ID;
等价于
SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID FROM cookie5 GROUP BY month
UNION ALL
SELECT NULL,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID FROM cookie5 GROUP BY day
UNION ALL
SELECT month,day,COUNT(DISTINCT cookieid) AS uv,3 AS GROUPING__ID FROM cookie5 GROUP BY month,day

玩一玩CUBE
说明
根据GROUP BY的维度的所有组合进行聚合
查询语句
SELECT month, day,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM cookie5
GROUP BY month,day
WITH CUBE
ORDER BY GROUPING__ID;
等价于
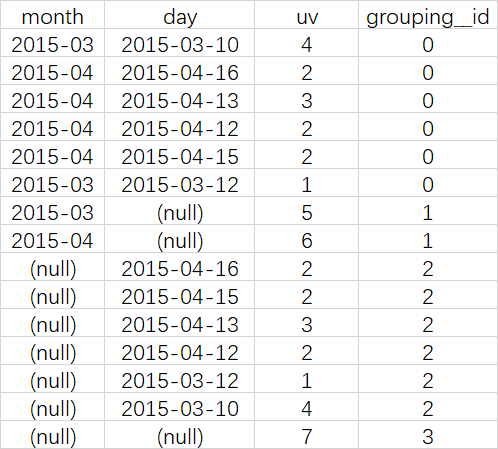
SELECT NULL,NULL,COUNT(DISTINCT cookieid) AS uv,0 AS GROUPING__ID FROM cookie5
UNION ALL
SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID FROM cookie5 GROUP BY month
UNION ALL
SELECT NULL,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID FROM cookie5 GROUP BY day
UNION ALL
SELECT month,day,COUNT(DISTINCT cookieid) AS uv,3 AS GROUPING__ID FROM cookie5 GROUP BY month,day
查询结果
玩一玩ROLLUP
说明
是CUBE的子集,以最左侧的维度为主,从该维度进行层级聚合
查询语句
-- 比如,以month维度进行层级聚合
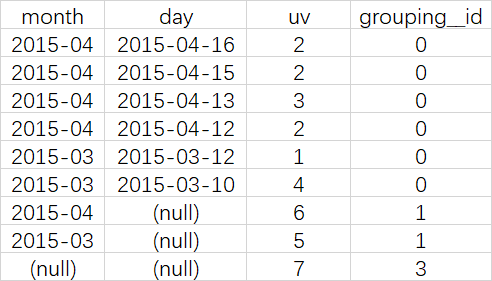
SELECT month, day, COUNT(DISTINCT cookieid) AS uv, GROUPING__ID
FROM cookie5
GROUP BY month,day WITH ROLLUP ORDER BY GROUPING__ID;
可以实现这样的上钻过程:
月天的UV->月的UV->总UV
--把month和day调换顺序,则以day维度进行层级聚合:
可以实现这样的上钻过程:
天月的UV->天的UV->总UV
(这里,根据天和月进行聚合,和根据天聚合结果一样,因为有父子关系,如果是其他维度组合的话,就会不一样)
Hive学习之路 (十七)Hive分析窗口函数(五) GROUPING SETS、GROUPING__ID、CUBE和ROLLUP的更多相关文章
- Hive高阶聚合函数 GROUPING SETS、Cube、Rollup
-- GROUPING SETS作为GROUP BY的子句,允许开发人员在GROUP BY语句后面指定多个统计选项,可以简单理解为多条group by语句通过union all把查询结果聚合起来结合起 ...
- Hive函数:GROUPING SETS,GROUPING__ID,CUBE,ROLLUP
参考:lxw大数据田地:http://lxw1234.com/archives/2015/04/193.htm 数据准备: CREATE EXTERNAL TABLE test_data ( mont ...
- [转帖]Hive学习之路 (一)Hive初识
Hive学习之路 (一)Hive初识 https://www.cnblogs.com/qingyunzong/p/8707885.html 讨论QQ:1586558083 目录 Hive 简介 什么是 ...
- Hive学习之路 (二十)Hive 执行过程实例分析
一.Hive 执行过程概述 1.概述 (1) Hive 将 HQL 转换成一组操作符(Operator),比如 GroupByOperator, JoinOperator 等 (2)操作符 Opera ...
- Hive学习之路 (一)Hive初识
Hive 简介 什么是Hive 1.Hive 由 Facebook 实现并开源 2.是基于 Hadoop 的一个数据仓库工具 3.可以将结构化的数据映射为一张数据库表 4.并提供 HQL(Hive S ...
- Hive学习之路 (二十一)Hive 优化策略
一.Hadoop 框架计算特性 1.数据量大不是问题,数据倾斜是个问题 2.jobs 数比较多的作业运行效率相对比较低,比如即使有几百行的表,如果多次关联多次 汇总,产生十几个 jobs,耗时很长.原 ...
- Hive学习之路 (十一)Hive的5个面试题
一.求单月访问次数和总访问次数 1.数据说明 数据字段说明 用户名,月份,访问次数 数据格式 A,, A,, B,, A,, B,, A,, A,, A,, B,, B,, A,, A,, B,, B ...
- Hive 学习之路(八)—— Hive 数据查询详解
一.数据准备 为了演示查询操作,这里需要预先创建三张表,并加载测试数据. 数据文件emp.txt和dept.txt可以从本仓库的resources目录下载. 1.1 员工表 -- 建表语句 CREAT ...
- Hive学习之路 (二)Hive安装
Hive的下载 下载地址http://mirrors.hust.edu.cn/apache/ 选择合适的Hive版本进行下载,进到stable-2文件夹可以看到稳定的2.x的版本是2.3.3 Hive ...
随机推荐
- Jprofiler注册码
L-Larry_Lau@163.com#23874-hrwpdp1sh1wrn#0620 L-Larry_Lau@163.com#36573-fdkscp15axjj6#25257 L-Larry_L ...
- R语言与.net 集成开发入门
首先:R语言的基本教程: https://www.yiibai.com/r/r_environment_setup.html 下载R语言的安装包:https://cran.r-project.org/ ...
- Springmvc中的HandlerAdaptor执行流程
今天讲解一下在Springmvc中的HandlerAdaptor执行流程,明白这个过程,你就能画出下面的图: 接下来我们就来看看具体的实现过程吧. 1.0在DispatcherServlet中找到ge ...
- linux系统下开启一个简单的web服务
linux 下开启一个简单的web服务: 首先需要linux下安装nodejs 然后创建一个test.js: vi test.js var http =require("http&quo ...
- Spring Boot--01错误处理
package com.smartmap.sample.ch1.controller.view; import java.io.IOException; import java.util.Collec ...
- 激活函数(relu,prelu,elu,+BN)对比on cifar10
激活函数(relu,prelu,elu,+BN)对比on cifar10 可参考上一篇: 激活函数 ReLU.LReLU.PReLU.CReLU.ELU.SELU 的定义和区别 一.理论基础 ...
- Ubuntu 16.04 小飞机启动失败
好长时间没用小飞机了,今天打开发现,无法启动了. 查看了日志: Initialising ciphers... AES-256/CFB (aes-256-cfb) initialised. Runni ...
- sql 字段别名里包含特殊字符
select ename employee.name from emp; 在数据库查询时,如果列名的别名里特殊符号,报错. select ename 'employee.name' from emp; ...
- public 类、default 类、内部类、匿名内部类
0.父类里private的成员变量,子类只有拥有权,没有使用权. 1.default 类 和public 类 package HelloWorld; public class HelloWorld { ...
- Prometheus Node_exporter 之 Basic CPU / Mem / Disk Gauge
1. CPU Busy :收集所有 cpu 内核 busy 状态占比 type: SinglestatUnit: perent(0-100)(所有 cpu使用情况 - 5分钟内 cpu 空闲的平均值) ...