MapReduce:Shuffle过程详解

1、Map任务处理
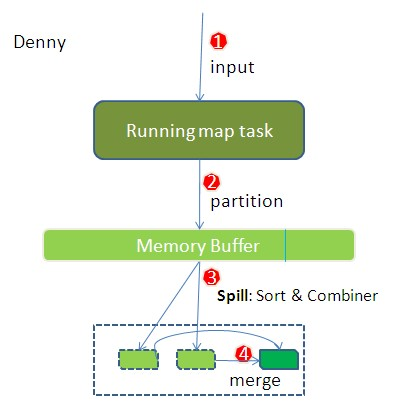
1.1 读取HDFS中的文件。每一行解析成一个<k,v>。每一个键值对调用一次map函数。 <0,hello you> <10,hello me>
1.2 覆盖map(),接收1.1产生的<k,v>,进行处理,转换为新的<k,v>输出。 <hello,1> <you,1> <hello,1> <me,1>
1.3 对1.2输出的<k,v>进行分区。默认分为一个区。Partitioner
- partitioner的作用是将mapper输出的键/值对拆分为分片(shard),每个reducer对应一个分片。 默认情况下,partitioner先计算目标的散列值(通常为md5值)。然后,通过reducer个数执行取模运算key.hashCode()%(reducer的个数)。 这种方式不仅能够随机地将整个键空间平均分发给每个reducer,同时也能确保不同mapper产生的相同键能被分发至同一个reducer。 如果用户自己对Partitioner有需求,可以订制并设置到job上。 job.setPartitionerClass(clz);
1.4 溢写Split
- map之后的key/value对以及Partition的结果都会被序列化成字节数组写入缓冲区,这个内存缓冲区是有大小限制的,默认是100MB。
- 当缓冲区的数据已经达到阈值(buffer size * spill percent = 100MB * 0.8 = 80MB),溢写线程启动,锁定这80MB的内存,执行溢写过程。Map task的输出结果还可以往剩下的20MB内存中写,互不影响。
- 当溢写线程启动后,需要对这80MB空间内的key做排序sort(1.5)
- 内存缓冲区没有对将发送到相同reduce端的数据做合并,那么这种合并应该是体现是磁盘文件中的。即Combine(1.6)。
1.5 对不同分区中的数据进行排序(按照k)Sort。
- 排序:每个分区内调用job.setSortComparatorClass()设置的Key比较函数类排序。可以看到,这本身就是一个二次排序。如果没有通过job.setSortComparatorClass()设置 Key比较函数类,则使用Key实现的compareTo()方法,即字典排序。job.setSortComparatorClass(clz); 排序后:<hello,1> <hello,1> <me,1> <you,1>
1.6 (可选)对分组后的数据进行归约。Combiner
combiner是一个可选的本地reducer,可以在map阶段聚合数据。combiner通过执行单个map范围内的聚合,减少通过网络传输的数据量。
例如,一个聚合的计数是每个部分计数的总和,用户可以先将每个中间结果取和,再将中间结果的和相加,从而得到最终结果。
求平均值的时候不能用,因为123的平均是2,12平均再和3平均结果就不对了。Combiner应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景,比如累加,最大值等。
1.7 合并Merge
- 每次溢写会在磁盘上生成一个溢写文件,如果map的输出结果真的很大,有多次这样的溢写发生,磁盘上相应的就会有多个溢写文件存在。
- 最终的文件只有一个,所以需要将这些溢写文件归并到一起,这个过程就叫做Merge。
- “hello”从两个map task读取过来,因为它们有相同的key,所以得merge成group。什么是group。group中的值就是从不同溢写文件中读取出来的,然后再把这些值加起来。group后:<hello,{1,1}><me,{1}><you,{1}>
- 因为merge是将多个溢写文件合并到一个文件,所以可能也有相同的key存在,在这个过程中如果设置过Combiner,也会使用Combiner来合并相同的key。
2、Reduce任务处理
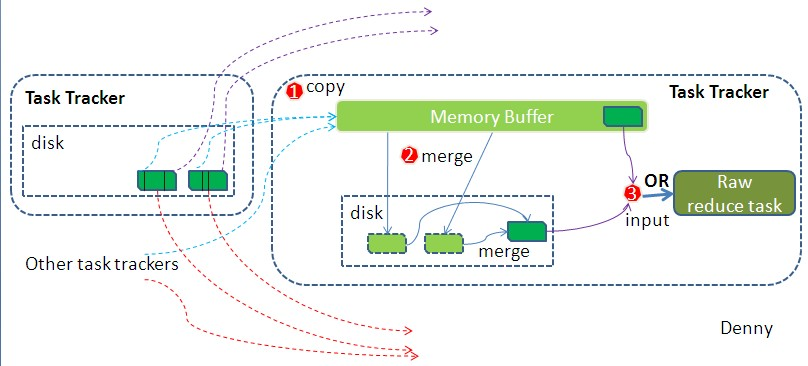
2.1 拉取数据Fetch
- Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求map task所在的TaskTracker获取map task的输出文件。因为map task早已结束,这些文件就归TaskTracker管理在本地磁盘中。
2.2 合并Merge
- Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置,因为Shuffle阶段Reducer不运行,所以应该把绝大部分的内存都给Shuffle用。
- 这里需要强调的是,merge有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。
- 默认情况下第一种形式不启用。
- 当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。与map 端类似,这也是溢写的过程,也有sort排序,如果设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种merge方式一直在运行,直到没有map端的数据时才结束。
- 然后启动第三种磁盘到磁盘的merge方式,有相同的key的键值队,merge成group,job.setGroupingComparatorClass设置的分组函数类,进行分组,同一个分组的value放在一个迭代器里面(二次排序会重新设置分组规则)。如果未指定GroupingComparatorClass则则使用Key的实现的compareTo方法来对其分组。group中的值就是从不同溢写文件中读取出来的,group后:<hello,{1,1}><me,{1}><you,{1}>
- 最终的生成的文件作为Reducer的输入,整个Shuffle才最终结束。
2.3 Reduce
- Reducer执行业务逻辑,产生新的<k,v>输出,将结果写到HDFS中。
3、WordCount代码
package mapreduce; import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class WordCountApp {
static final String INPUT_PATH = "hdfs://chaoren:9000/hello";
static final String OUT_PATH = "hdfs://chaoren:9000/out"; public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf);
Path outPath = new Path(OUT_PATH);
if (fileSystem.exists(outPath)) {
fileSystem.delete(outPath, true);
} Job job = new Job(conf, WordCountApp.class.getSimpleName()); // 指定读取的文件位于哪里
FileInputFormat.setInputPaths(job, INPUT_PATH);
// 指定如何对输入的文件进行格式化,把输入文件每一行解析成键值对
//job.setInputFormatClass(TextInputFormat.class); // 指定自定义的map类
job.setMapperClass(MyMapper.class);
// map输出的<k,v>类型。如果<k3,v3>的类型与<k2,v2>类型一致,则可以省略
//job.setOutputKeyClass(Text.class);
//job.setOutputValueClass(LongWritable.class); // 指定自定义reduce类
job.setReducerClass(MyReducer.class);
// 指定reduce的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class); // 指定写出到哪里
FileOutputFormat.setOutputPath(job, outPath);
// 指定输出文件的格式化类
//job.setOutputFormatClass(TextOutputFormat.class); // 分区
//job.setPartitionerClass(clz); // 排序、分组、归约
//job.setSortComparatorClass(clz);
//job.setGroupingComparatorClass(clz);
//job.setCombinerClass(clz); // 有一个reduce任务运行
//job.setNumReduceTasks(1); // 把job提交给jobtracker运行
job.waitForCompletion(true);
} /**
*
* KEYIN 即K1 表示行的偏移量
* VALUEIN 即V1 表示行文本内容
* KEYOUT 即K2 表示行中出现的单词
* VALUEOUT 即V2 表示行中出现的单词的次数,固定值1
*
*/
static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
protected void map(LongWritable k1, Text v1, Context context) throws java.io.IOException, InterruptedException {
String[] splited = v1.toString().split("\t");
for (String word : splited) {
context.write(new Text(word), new LongWritable(1));
}
};
} /**
* KEYIN 即K2 表示行中出现的单词
* VALUEIN 即V2 表示出现的单词的次数
* KEYOUT 即K3 表示行中出现的不同单词
* VALUEOUT 即V3 表示行中出现的不同单词的总次数
*/
static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
protected void reduce(Text k2, java.lang.Iterable<LongWritable> v2s, Context ctx) throws java.io.IOException, InterruptedException {
long times = 0L;
for (LongWritable count : v2s) {
times += count.get();
}
ctx.write(k2, new LongWritable(times));
};
}
}
MapReduce:Shuffle过程详解的更多相关文章
- Hadoop MapReduce执行过程详解(带hadoop例子)
https://my.oschina.net/itblog/blog/275294 摘要: 本文通过一个例子,详细介绍Hadoop 的 MapReduce过程. 分析MapReduce执行过程 Map ...
- Hadoop学习之Mapreduce执行过程详解
一.MapReduce执行过程 MapReduce运行时,首先通过Map读取HDFS中的数据,然后经过拆分,将每个文件中的每行数据分拆成键值对,最后输出作为Reduce的输入,大体执行流程如下图所示: ...
- MapReduce shuffle阶段详解
在Mapreduce中,Shuffle过程是Mapreduce的核心,它分布在Mapreduce的map阶段和reduce阶段,共可分为6个详细的阶段: 1).Collect阶段:将MapTask的结 ...
- hadoop: Shuffle过程详解 (转载)
原文地址:http://langyu.iteye.com/blog/992916 另一篇博文:http://www.cnblogs.com/gwgyk/p/3997849.html Shuffle过程 ...
- Hadoop Mapreduce的shuffle过程详解
1.map task读取数据时默认调用TextInputFormat的成员RecoreReader,RecoreReader调用自己的read()方法,进行逐行读取,返回一个key.value; 2. ...
- MapReduce的shuffle过程详解
[学习笔记] 结果分析:shuffle的英文是洗牌,混洗的意思,洗牌就是越乱越好的意思.当在集群的情况下是这样的,假如有三个map节点和三个reduce节点,一号reduce节点的数据会来自于三个ma ...
- Shuffle过程详解
- MapReduce Shuffle过程
MapReduce Shuffle 过程详解 一.MapReduce Shuffle过程 1. Map Shuffle过程 2. Reduce Shuffle过程 二.Map Shuffle过程 1. ...
- Hadoop Mapreduce分区、分组、二次排序过程详解[转]
原文地址:Hadoop Mapreduce分区.分组.二次排序过程详解[转]作者: 徐海蛟 教学用途 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2) ...
随机推荐
- 在vue-cli建的vue项目中使用sass
前面已使用vue-cli新建了一个vue项目,参考 使用命令行创建一个vue项目的全部命令及结果 首先看下新建项目的页面和代码,有部分修改,可忽视,如下图: 然后我们在页面添加sass的代码 ...
- 【BZOJ2082】【POI2010】Divine divisor 假的pollard-rho
题目大意:给你$m$个数$a_i$,定义$n=\Pi_{i=1}^{m}a_i$.将$n$分解质因数为$\Pi p_i^{k_i} $,$p_i$是质数.请输出$2^{max(k_i)}-1$,以及存 ...
- Tomcat发生java.lang.OutOfMemoryError: PermGen space的解决方案
产生该问题的主要原因是JVM永久带空间不足导致的,可以在环境变量CATALINA_OPTS中提高MaxPermSize参数值 set CATALINA_OPTS = -XX:PermSize=12 ...
- mysql中UNION ALL用法
MYSQL中的UNION UNION在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果. 举例说明: select * from table1 u ...
- (转)Python中集合(set)的基本操作以及一些常见的用法
原文:http://blog.51cto.com/10616534/1944841 Python除了List.Tuple.Dict等常用数据类型外,还有一种数据类型叫做集合(set),集合的最大特点是 ...
- java对象流与序列化
Object流,直接把obj写入或读出. 前言: 比如 画图的程序,咣当画一个三角形出来,咣当画一正方形出来.然后存盘,当你下次再打开软件的时候三角形.方块还在原来的位置上.如果用面向对象的思维,三角 ...
- 页面滚动插件 better-scroll 的用法
better-scroll 是一个页面滚动插件,用它可以很方便的实现下拉刷新,锚点滚动等功能. 实现原理:父容器固定高度,并设置 overflow:hidden,子元素超出父元素高度后将被隐藏,超出部 ...
- SPSS学习系列之SPSS Modeler Server是什么?
不多说,直接上干货! SPSS Modeler 使用客户端/服务器体系结构将资源集约型操作的请求分发给功能强大的服务器软件,因而使大数据集的传输速度大大加快.除了此处所列的产品和更新,也可能还有其他可 ...
- epoll—IO多路复用
1.在socket.listen()后创一个epoll对象 epoll = select.epoll() 2.将server_socket注册到epoll中 epoll.regist ...
- solidity如何拼接字符串?
当你开始学习使用solidity开发以太坊智能合约之后,很快你会碰到一个问题: 一.在solidity中该如何拼接字符串? 可能你已经试过了,下面的代码试图把两个字符串使用相加的运算符连接起来,但是这 ...