Python 爬虫入门(一)
毕设是做爬虫相关的,本来想的是用java写,也写了几个爬虫,其中一个是爬网易云音乐的用户信息,爬了大概100多万,效果不是太满意。之前听说Python这方面比较强,就想用Python试试,之前也没用过Python。所以,边爬边学,边学边爬。废话不多说,进入正题。
1.首先是获取目标页面,这个对用python来说,很简单
#encoding=utf8
import urllib res = urllib.urlopen("http://www.baidu.com")
print res.read()
运行结果和打开百度页面,查看源代码一样。这里针对python的语法有几点说明。
a).import 就是引入的意思,java也用import,C/C++用的是include,作用一样
b).urllib 这个是python自带的模块,在以后开发的时候,如果遇到自己需要的功能,python自带的模块中没有的时候,可以试着去网上找一找,比如需要操作MySql数据 库,这个时候python是没有自带的,就可以在网上找到MySQLdb,然后安装引入就行了。
c).res是一个变量,不用像java,C语言那样声明。用的时候直接写就行了
d).标点符号。像java,C这些语言,每行代码后面都要用分号或者别的符号,作为结束标志,python不用,用了反了会出错。不过有的时候,会用标点符号,比如冒号, 这个后面再说
e).关于print,在python2.7中,有print()函数,也有print 语句,作用基本差不多。
f).#注释
g).encoding=utf8代表使用utf8编码,这个在代码中有中文的时候特别有用
2.解析获取的网页中的元素,取得自己想要的,以豆瓣为例,我们想获取这个页面中的所有书籍名称(仅供学习交流)
http://www.douban.com/tag/%E5%B0%8F%E8%AF%B4/?focus=book
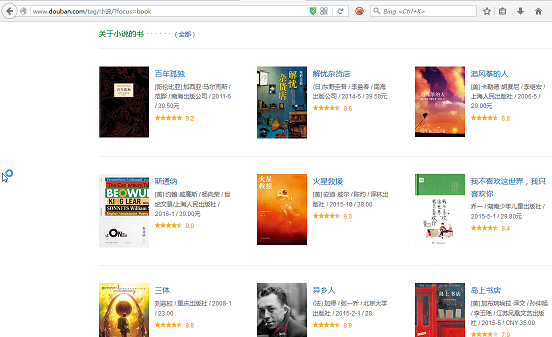
首先获取页面代码:
#encoding=utf8
import urllib
res = urllib.urlopen("http://www.douban.com/tag/%E5%B0%8F%E8%AF%B4/?focus=book")
print res.read()
获取结果,通过分析页面源代码(建议用firefox浏览器,按F12,可看到源代码),可以定位到有效代码如下:
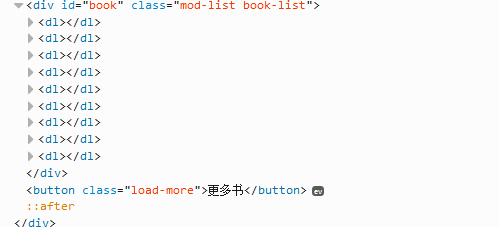
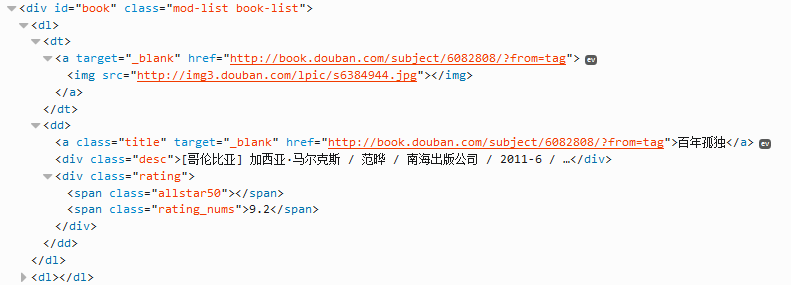
下面我们开始解析(这里用BeautifulSoup,自行下载安装),基本流程:
a).缩小范围,这里我们通过id="book"获取所有的书
b).然后通过class="title",遍历所有的书名。
代码如下:
#encoding=utf8
import urllib
import BeautifulSoup res = urllib.urlopen("http://www.douban.com/tag/%E5%B0%8F%E8%AF%B4/?focus=book")
soup = BeautifulSoup.BeautifulSoup(res)
book_div = soup.find(attrs={"id":"book"})
book_a = book_div.findAll(attrs={"class":"title"})
for book in book_a:
print book.string
代码说明:
a).book_div 通过id=book获取div标签
b).book_a 通过class="title"获取所有的book a标签
c).for循环 是遍历book_a所有的a标签
d).book.string 是输出a标签中的内容
结果如下:

3.存储获取的数据,比如写入数据库,我的数据库用的Mysql,这里就以Mysql为例(下载安装MySQLdb模块这里不做叙述),只写怎么执行一条sql语句
代码如下:
connection = MySQLdb.connect(host="***",user="***",passwd="***",db="***",port=3306,charset="utf8")
cursor = connection.cursor()
sql = "*******"
sql_res = cursor.execute(sql)
connection.commit()
cursor.close()
connection.close()
说明:
a).这段代码是执行sql语句的流程,针对不同的sql语句,会有不同的处理。比如,执行select的语句,我怎么获取执行的结果,执行update语句,怎么之后成没成功。这 些就要自己动手了
b).创建数据库的时候一定要注意编码,建议使用utf8
4.至此,一个简单的爬虫就完成了。之后是针对反爬虫的一些策略,比如,用代理突破ip访问量限制
声明:
代码仅供学习交流使用,不能用于恶意采集、破坏等不良行为,出问题概不负责
如有问题,欢迎指正。
转载请注明出处。
Python 爬虫入门(一)的更多相关文章
- Python爬虫入门一之综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- python爬虫入门-开发环境与小例子
python爬虫入门 开发环境 ubuntu 16.04 sublime pycharm requests库 requests库安装: sudo pip install requests 第一个例子 ...
- Python爬虫入门教程 48-100 使用mitmdump抓取手机惠农APP-手机APP爬虫部分
1. 爬取前的分析 mitmdump是mitmproxy的命令行接口,比Fiddler.Charles等工具方便的地方是它可以对接Python脚本. 有了它我们可以不用手动截获和分析HTTP请求和响应 ...
- Python爬虫入门教程 43-100 百思不得姐APP数据-手机APP爬虫部分
1. Python爬虫入门教程 爬取背景 2019年1月10日深夜,打开了百思不得姐APP,想了一下是否可以爬呢?不自觉的安装到了夜神模拟器里面.这个APP还是比较有名和有意思的. 下面是百思不得姐的 ...
- Python 爬虫入门(二)——爬取妹子图
Python 爬虫入门 听说你写代码没动力?本文就给你动力,爬取妹子图.如果这也没动力那就没救了. GitHub 地址: https://github.com/injetlee/Python/blob ...
- Python爬虫入门之正则表达式
在前面我们已经搞定了怎样获取页面的内容,不过还差一步,这么多杂乱的代码夹杂文字我们怎样把它提取出来整理呢?下面就开始介绍一个十分强大的工具,正则表达式! 1.了解正则表达式 正则表达式是对字符串操作的 ...
- Python爬虫入门之Cookie的使用
本节我们一起来看一下Cookie的使用. 为什么要使用Cookie呢? Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据(通常经过加密) 比如说有些网站需要 ...
- Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- Python爬虫入门之Urllib库的基本使用
那么接下来,小伙伴们就一起和我真正迈向我们的爬虫之路吧. 1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解 ...
- 3.Python爬虫入门三之Urllib和Urllib2库的基本使用
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它是一段HTML代码,加 JS.CSS ...
随机推荐
- users命令详解
基础命令学习目录 原文链接:https://blog.csdn.net/m0_38132420/article/details/78861464 users命令用于显示当前登录系统所有的用户的用户列表 ...
- 互评Beta版本(Hello World!——SkyHunter)
1 基于NABCD评论作品,及改进建议 SkyHunter这款游戏我很喜欢,小时候总玩飞机类的游戏,这款游戏我上课的时候试玩了,在我电脑上运行是很好玩的,音乐震撼,画面玄幻,富有金属音乐的味道,游戏内 ...
- 作业MathExam
MathExam233 一.预估与实际 PSP2.1 Personal Software Process Stages 预估耗时(分钟) 实际耗时(分钟) Planning 计划 600 650 • ...
- 信息安全系统设计基础_exp1
北京电子科技学院(BESTI) 实 验 报 告 课程:信息安全系统设计基础 班级:1353 姓名:吴子怡.郑伟 学号:20135313.20135322 指导教师: 娄嘉鹏 实验 ...
- POJ 2151 Check the difficulty of problems 概率dp+01背包
题目链接: http://poj.org/problem?id=2151 Check the difficulty of problems Time Limit: 2000MSMemory Limit ...
- Gradle入门(5):创建二进制发布版本
在创建了一个实用的应用程序之后,我们可能想将其与他人分享.其中一种方式就是创建一个可以从网站上下载的二进制文件. 这篇教程描述了如何创建一个二进制发布版本,满足以下需求: 二进制发布一定不能使用所谓的 ...
- Scrum Meeting Beta - 10
Scrum Meeting Beta - 10 NewTeam 2017/12/11 地点:新主楼F座二楼 任务反馈 团队成员 完成任务 计划任务 安万贺 完成了作业详情的本地存储Issue #165 ...
- 『编程题全队』Alpha 阶段冲刺博客Day4
1.每日站立式会议 1.会议照片 2.昨天已完成的工作统计 孙志威: 1.添加团队界面下的看板容器SlotWidget 2.实现SlotWidgets的动态布局管理 3.实现团队/个人界面之间的切换 ...
- python基础(四)文件操作和集合
一.文件操作 对文件的操作分三步: 1.打开文件获取文件的句柄,句柄就理解为这个文件 2.通过文件句柄操作文件 3.关闭文件. 1.文件基本操作: f = open('file.txt','r') # ...
- “Unable to open kernel device \\.\Global\vmx86
启动vm中虚拟机中的时候,弹出窗口的时候,弹出窗口 Unable to open kernel device \\.\Global\vmx86;系统找不到指定的文件,Did you reboot af ...