Kettle实现数据抽取、转换、装入和加载数据-数据转移ETL工具
原文地址:http://www.xue51.com/soft/5341.html
Kettle是来自国外的一款开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装。Kettle可以帮助你实现你的ETTL需要:抽取、转换、装入和加载数据数据,且抽取高效稳定。Kettle这个ETL工具集,翻译成中文名称应该叫水壶,寓意为希望把各种数据放到一个壶里然后以一种指定的格式流出。它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。
官方网站下载地址:https://community.hitachivantara.com/docs/DOC-1009855 目前最新稳定版本已经到8.2了。

Kettle家族目前包括4个产品:Spoon、Pan、CHEF、Kitchen。
- SPOON 允许你通过图形界面来设计ETL转换过程(Transformation)。
- PAN 允许你批量运行由Spoon设计的ETL转换 (例如使用一个时间调度器)。Pan是一个后台执行的程序,没有图形界面。
- CHEF 允许你创建任务(Job)。 任务通过允许每个转换,任务,脚本等等,更有利于自动化更新数据仓库的复杂工作。任务通过允许每个转换,任务,脚本等等。任务将会被检查,看看是否正确地运行了。
- KITCHEN 允许你批量使用由Chef设计的任务 (例如使用一个时间调度器)。KITCHEN也是一个后台运行的程序。
使用教程
1、打开Spoon.bat,打开后请耐心等待一会儿时间。
2、配置Kettle的环境变量:(前提是配置好Java的环境变量,因为他是java编写,需要本地的JVM的运行环境)在系统的环境变量中添加KETTLE_HOME变量,目录指向kettle的安装目录
新建系统变量:KETTLE_HOME
变量值: D:\kettle\data-integration(具体以安装路径为准,Kettle的解压路径,直到Kettle.exe所在目录)
选择PATH添加环境变量:
变量名:PATH
变量值:% KETTLE_HOME%;
3、建立转换。
在文件->新建装换。
新建转换后在左边的主对象树中建立DB连接用以连接数据库。
建立数据库连接的过程与其他数据库管理软件连接数据库类似。
注意:在数据库链接的过程中,可能会报某个数据库连接找不到的异常。那是因为你没有对应的数据库链接驱动,请下载对应驱动后,放入kettle的lib文件夹。
4、简单的数据表插入\更新
新建表插入
在左边的面板中选择“核心对象”,在核心对象里面选择“输入->表输入”,用鼠标拖动到右边面板。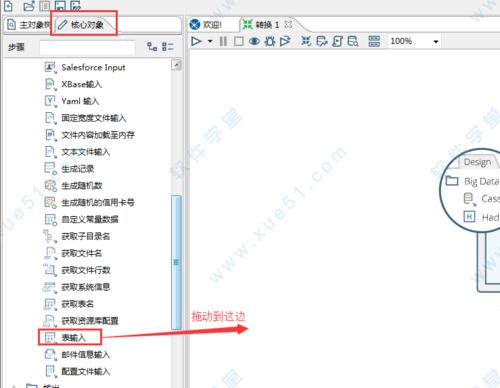
5、双击拖过来的表,可以编辑表输入。
选择数据库连接和编辑sql语句,在这一步可以点击预览,查看自己是否连接正确。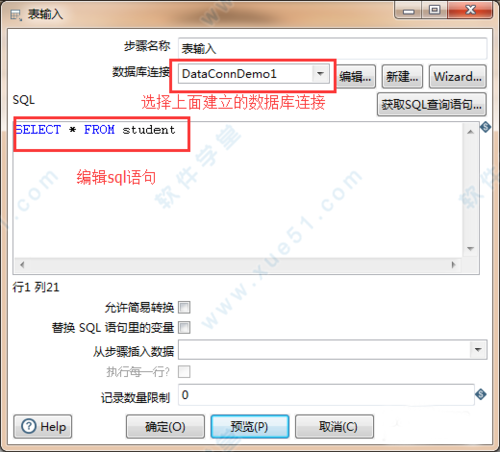
6、通过插入\更新输出到表。
在左边面板中选择核心对象、选择“输出->插入\更新”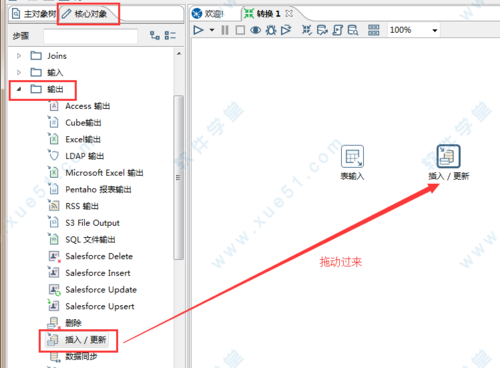
7、编辑插入更新:
首先:表输入连接插入更新。
选中表输入,按住shift键,拖向插入更新。
8、然后:双击插入更新,编辑它。
到这里基本上,这个转换就要做完了,可以点击运行查看效果,看是否有误,这个要先保存了才能运行,可以随意保存到任何一个地方。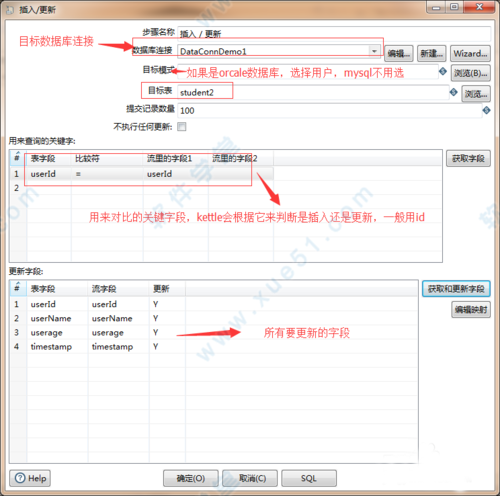
9、使用作业控制上面装换执行。
使用作业可以定时或周期性的执行转换,新建一个作业。并从左边面板拖入start 和转换。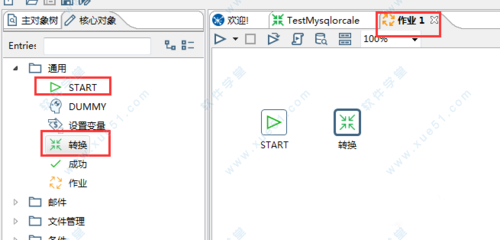
10、双击start可以编辑,可以设置执行时间等等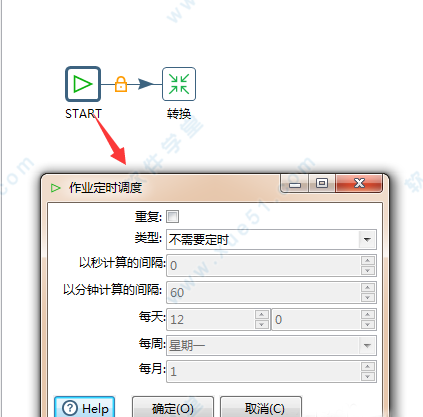
11、点开装换,可以设置需要执行的转换任务,比如可以执行上面我们做的转换,XXX.ktr最后点击运行即可。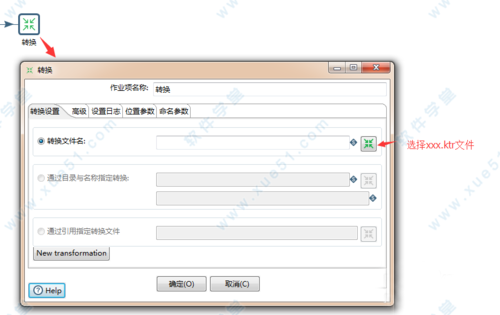
应用场景
1、表视图模式:这种情况我们经常遇到,就是在同一网络环境下,我们对各种数据源的表数据进行抽取、过滤、清洗等,例如历史数据同步、异构系统数据交互、数据对称发布或备份等都归属于这个模式;传统的实现方式一般都要进行研发(一小部分例如两个相同表结构的表之间的数据同步,如果sqlserver数据库可以通过发布/订阅实现),涉及到一些复杂的一些业务逻辑如果我们研发出来还容易出各种bug;
2、前置机模式:这是一种典型的数据交换应用场景,数据交换的双方A和B网络不通,但是A和B都可以和前置机C连接,一般的情况是双方约定好前置机的数据结构,这个结构跟A和B的数据结构基本上是不一致的,这样我们就需要把应用上的数据按照数据标准推送到前置机上,这个研发工作量还是比较大的;
3、文件模式: 数据交互的双方A和B是完全的物理隔离,这样就只能通过以文件的方式来进行数据交互了,例如XML格式,在应用A中我们开发一个接口用来生成标准格式的XML,然后用优盘或者别的介质在某一时间把XML数据拷贝之后,然后接入到应用B上,应用B上在按照标准接口解析相应的文件把数据接收过来
常见问题
1、Kettle无法启动
修改一下spoon.bat里内存配置:
if "%PENTAHO_DI_JAVA_OPTIONS%"=="" set PENTAHO_DI_JAVA_OPTIONS="-Xms2058m" "-Xmx1024m" "-XX:MaxPermSize=256m"
改为
if "%PENTAHO_DI_JAVA_OPTIONS%"=="" set PENTAHO_DI_JAVA_OPTIONS="-Xms512m" "-Xmx512m" "-XX:MaxPermSize=256m"
2、如何连接资源库?
如果没有则创建资源库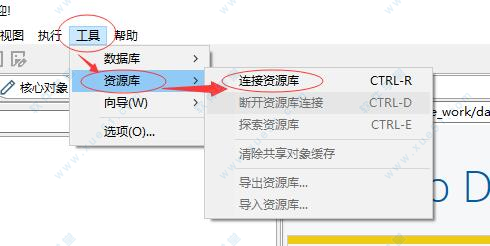
3、如何连接数据库?
在连接数据库之前,首先需要保证当前在一个transform(转换)页面,然后点击左侧选项栏中的“主对象树”,然后右键点击“DB连接”,选择“新建”。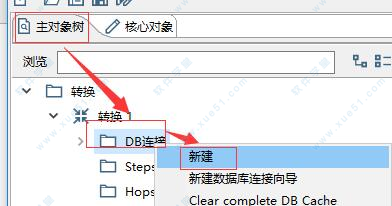
当然也可以设置一些其他的连接属性,如zeroDateTimeBehavior=round&characterEncoding=utf8。
4、如何解决数据库连接更新不及时问题?
有时候我们数据库中的表的字段进行了更新(增加或删除字段),但是在使用“表输入”控件的“获取SQL语句”功能是会发现的到的字段还是原来的字段,这是由于缓存造成的,需要进行缓存清理。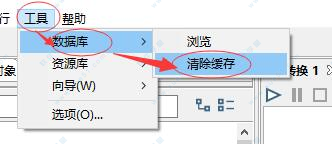
5、如何解决Unable to read file错误?
有时候我们在文件夹中将Job或Transform移动到其他目录之后,执行时会出现Unable to read file错误。然后就进入到了当前Transform的配置页面。修改配置中的目录即可。
6、如何解决tinyint类型数据丢失问题?
在Kettle使用JDBC连接MySQL时,对于表中数据类型为tinyint的字段,读取时有可能会将其转为bool类型,这有可能造成数据丢失。例如,有一个叫status名字的tinyint类型字段,取值有三种:0、1、2。kettle读取之后很可能将0转为false,1、2都转为true。输出时,将false转为0,true转为1,这样就会造成元数据中status为2的数据被错误的赋值为1。
解决这个问题时,可以在读取元数据时将status转为int或char。比如SELECT CAST(status as signed) as status FROM 或SELECT CAST(status as char) as status FROM
Kettle实现数据抽取、转换、装入和加载数据-数据转移ETL工具的更多相关文章
- ETL工具之Kettle的简单使用一(不同数据库之间的数据抽取-转换-加载)
ETL工具之Kettle将一个数据库中的数据提取到另外一个数据库中: 1.打开ETL文件夹,双击Spoon.bat启动Kettle 2.资源库选择,诺无则选择取消 3.选择关闭 4.新建一个转换 5. ...
- RS232/485通信方式 保存和加载时数据的处理
RS232/485通信方式 数据以RS232/485方式通信时,以0xA5作为开始码,以0xAE作为结束码.在开始码和结束码之间的0xA5, 0xAA, 0xAE数据需要进行转码. PC端发送数据时将 ...
- tensorflow保存数据为.pb格式和加载pb文件
转自:https://blog.csdn.net/u014264373/article/details/79943389 https://blog.csdn.net/fu6543210/article ...
- 大数据之ETL工具Kettle的--1功能介绍
Kettle是一款国外开源的ETL工具,纯java编写,可以在Window.Linux.Unix上运行. 说白了就是,很有必要去理解一般ETL工具必备的特性和功能,这样才更好的掌握Kettle的使用. ...
- 数据抽取 CDC
什么是数据抽取 数据抽取是指从源数据源系统抽取目的数据源系统需要的数据.实际应用中,数据源较多采用的是关系数据库. [编辑] 数据抽取的方式 (一) 全量抽取 全量抽取类似于数据迁移或数据复制,它将数 ...
- Learning Spark中文版--第五章--加载保存数据(2)
SequenceFiles(序列文件) SequenceFile是Hadoop的一种由键值对小文件组成的流行的格式.SequenceFIle有同步标记,Spark可以寻找标记点,然后与记录边界重新 ...
- 《BI项目笔记》增量ETL数据抽取的策略及方法
增量抽取 增量抽取只抽取自上次抽取以来数据库中要抽取的表中新增或修改的数据.在ETL使用过程中.增量抽取较全量抽取应用更广.如何捕获变化的数据是增量抽取的关键.对捕获方法一般有两点要求:准确性,能够将 ...
- ETL工具的功能和kettle如何来提供这些功能
不多说,直接上干货! 大家会有一个疑惑,本系列博客是Kettle,那怎么扯上ETL呢? Kettle是一款国外开源的ETL工具,纯java编写,可以在Window.Linux.Unix上运行. 说白了 ...
- 六种 主流ETL 工具的比较(DataPipeline,Kettle,Talend,Informatica,Datax ,Oracle Goldengate)
六种 主流ETL 工具的比较(DataPipeline,Kettle,Talend,Informatica,Datax ,Oracle Goldengate) 比较维度\产品 DataPipeline ...
随机推荐
- 使用PHPStorm 配置自定义的Apache与PHP环境
使用PHPStorm 配置自定义的Apache与PHP环境之一 关于phpstorm配置php开发环境,大多数资料都是直接推荐安装wapmserver.而对于如何配置自定义的PHP环境和Apach ...
- HDU 1045 Fire Net 【二分图匹配】
<题目链接> 题目大意: 这题意思是给出一张图,图中'X'表示wall,'.'表示空地,可以放置炮台,同一条直线上只能有一个炮台,除非有'X'隔开,问在给出的图中最多能放置多少个炮台. 解 ...
- POJ 1330 Nearest Common Ancestors (模板题)【LCA】
<题目链接> 题目大意: 给出一棵树,问任意两个点的最近公共祖先的编号. 解题分析:LCA模板题,下面用的是树上倍增求解. #include <iostream> #inclu ...
- linux(manjaro)磁盘迁移/opt /home
目录 1. 创建临时挂载点/opt, 并将分区挂载到临时挂载点上: 2. 切换单用户,将除了root用户之外的用户踢出 3. 将/opt目录下的所有内容拷贝到临时挂载点中,等待结束 4. 进入/et ...
- HashMap 源码阅读
前言 之前读过一些类的源码,近来发现都忘了,再读一遍整理记录一下.这次读的是 JDK 11 的代码,贴上来的源码会去掉大部分的注释, 也会加上一些自己的理解. Map 接口 这里提一下 Map 接口与 ...
- APP开发,微信第三方登录的介绍
去年做了一阵APP相关的开发,经常遇到第三方登陆的需求,比如微信.微博.fb的第三方登陆等等,其实主要的流程都大同小异,这里就以微信为例来介绍,希望对大家有帮助. 微信开放平台(open.weixin ...
- HTTP STATUS CODE: 521的解决办法
https://blog.csdn.net/wangdepei/article/details/84798601
- Java 的Event机制浅析
https://blog.csdn.net/kehyuanyu/article/details/23540901
- linux6.8安装docker
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化.容器是完全使用沙箱机制,相互之间不会有任何 ...
- Java基础(十三) 文件高级技术
文件高级技术 一.常见文件类型处理 一)属性文件 属性文件很简单,一行表示一个属性,属性就是键值对,键和值用(=)或者(:)分隔. #ready to work name = tang age = p ...