pymysql 使用twisted异步插入数据库:基于crawlspider爬取内容保存到本地mysql数据库
本文的前提是实现了整站内容的抓取,然后把抓取的内容保存到数据库。
可以参考另一篇已经实现整站抓取的文章:Scrapy 使用CrawlSpider整站抓取文章内容实现
本文也是基于这篇文章代码基础上实现通过pymysql+twisted异步保存到本地数据库
直接进入主题:
# -*- coding: utf-8 -*-
import pymysql
from twisted.enterprise import adbapi
from scrapy.utils.project import get_project_settings
class DBHelper():
def __init__(self):
settings = get_project_settings()
dbparams = dict(
host=settings['MYSQL_HOST'],
db=settings['MYSQL_DBNAME'],
user=settings['MYSQL_USER'],
passwd=settings['MYSQL_PASSWD'],
charset='utf8', #解决中文乱码问题
cursorclass=pymysql.cursors.DictCursor,
use_unicode=False,
)
#**表示将字典扩展为关键字参数,相当于host=xxx,db=yyy....
dbpool = adbapi.ConnectionPool('pymysql', **dbparams)
self.__dbpool = dbpool
def connect(self):
return self.__dbpool
def insert(self, item):
#这里定义要插入的字段
sql = "insert into article(title) values(%s)"
query = self.__dbpool.runInteraction(self._conditional_insert, sql, item)
query.addErrback(self._handle_error)
return item
#写入数据库中
def _conditional_insert(self, canshu, sql, item):
#这里item就是爬虫代码爬下来存入items内的数据
params = (item['title'])
canshu.execute(sql, params)
def _handle_error(self, failue):
print(failue)
def __del__(self):
try:
self.__dbpool.close()
except Exception as ex:
print(ex)
- 定义数据库表结构(提前创建好名为scrapy的数据库并授权给root用户):
CREATE TABLE `article` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(200) DEFAULT NULL COMMENT '文章标题',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=116 DEFAULT CHARSET=utf8mb4
- settings.py中定义用到的数据库连接信息(这里配置的账号等信息根据你自己的环境相应改动):
#mysql-config
MYSQL_HOST = '127.0.0.1'
MYSQL_DBNAME = 'scrapy'
MYSQL_USER = 'root'
MYSQL_PASSWD ='123456'
MYSQL_PORT = 3306
- 最后在管道中把爬取的内容保存到mysql数据库中:
pipelines.py 的代码如下(其中还保存到json文件中了,不需要的可以去掉file相关操作的代码):
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
from logging import Logger
from twisted.enterprise import adbapi
from blogscrapy.db.dbhelper import DBHelper
import codecs
from logging import log
from scrapy.utils.project import get_project_settings
class BlogscrapyPipeline(object):
def __init__(self):
self.file = open('blog.json', 'a+', encoding='utf-8')
self.db = DBHelper()
def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(content)
self.db.insert(item)
return item
def close_spider(self, spider):
self.file.close()
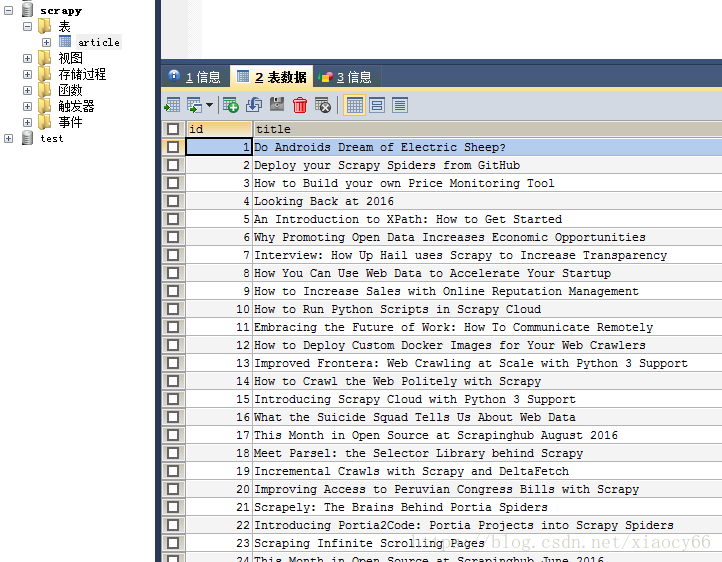
结果如下图:
本文源码下载: 点我去下载
参考资料
[1]: Scrapy官方文档
[2]: Python3爬取今日头条系列
[3]: 廖雪峰老师的Python3 在线学习手册
[4]: Python3官方文档
[5]: 菜鸟学堂-Python3在线学习
[6]: XPath语法参考
[7]: Scrapy 使用CrawlSpider整站抓取文章内容实现
pymysql 使用twisted异步插入数据库:基于crawlspider爬取内容保存到本地mysql数据库的更多相关文章
- python之scrapy爬取jingdong招聘信息到mysql数据库
1.创建工程 scrapy startproject jd 2.创建项目 scrapy genspider jingdong 3.安装pymysql pip install pymysql 4.set ...
- 从redis数据库取数据存放到本地mysql数据库
redis数据库属于非关系型数据库,数据存放在内存堆栈中,效率比较高. 其存储数据是以json格式字符串存储字典的,而类似的关系型数据库无法实现这种数据的存储. 在爬取数据时,将数据暂存到redis中 ...
- 基于gin的golang web开发:访问mysql数据库
web开发基本都离不开访问数据库,在Gin中使用mysql数据库需要依赖mysql的驱动.直接使用驱动提供的API就要写很多样板代码.你可以找到很多扩展包这里介绍的是jmoiron/sqlx.另外还有 ...
- Scrapy Item用法示例(保存item到MySQL数据库,MongoDB数据库,使用官方组件下载图片)
需要学习的地方: 保存item到MySQL数据库,MongoDB数据库,下载图片 1.爬虫文件images.py # -*- coding: utf-8 -*- from scrapy import ...
- 爬取70城房价到oracle数据库并6合1
学习数据分析,然后没有合适的数据源,从国家统计局的网页上抓取一页数据来玩玩(没有发现robots协议,也仅仅发出一次连接请求,不对网站造成任何负荷) 运行效果 源码 python代码 ''' 本脚本旨 ...
- [saiku] 将saiku自带的H2嵌入式数据库迁移到本地mysql数据库
saiku数据库的表和用户默认创建是在启动项目的时候,通过初始化 saiku-beans.xml 中的 h2database 这个 bean 执行org.saiku.service.Database类 ...
- Holer实现外网访问本地MySQL数据库
外网访问内网MySQL数据库 内网主机上安装了MySQL数据库,只能在局域网内访问,怎样从公网也能访问本地MySQL数据库? 本文将介绍使用holer实现的具体步骤. 1. 准备工作 1.1 安装并启 ...
- Java读取oracle数据库中blob字段数据文件保存到本地文件(转载)
转自:https://www.cnblogs.com/forever2698/p/4747349.html package com.bo.test; import java.io.FileOutput ...
- Scrapy框架——CrawlSpider爬取某招聘信息网站
CrawlSpider Scrapy框架中分两类爬虫,Spider类和CrawlSpider类. 它是Spider的派生类,Spider类的设计原则是只爬取start_url列表中的网页, 而Craw ...
随机推荐
- ffmpeg切割视频
using System.Diagnostics; public static void carveVideo() { var inputpath = @"d:\1.mp4"; v ...
- data-key
在foreach或者each循环中给按钮赋予值 html中:data-key="@config.key" js里获取值: var key = $(this).data(" ...
- Just Oj 2017C语言程序设计竞赛高级组D: 字符串最大表示(next数组)
D: 字符串最大表示 时间限制: 1 s 内存限制: 128 MB 题目描述 有如下定义,abcnabcn表示字符串abc重复n次,例如abc2abc2表示abcabc. 给定一个字符串,求 ...
- Python - 去除list中的空字符
list1 = ['122', '2333', '3444', '', '', None] a = list(filter(None, list1)) # 只能过滤空字符和None print(a) ...
- vue Bus总线
有时候两个组件也需要通信(非父子关系).当然Vue2.0提供了Vuex,但在简单的场景下,可以使用一个空的Vue实例作为中央事件总线. 参考:http://blog.csdn.net/u0130340 ...
- SSD垃圾回收
A complete GC typically:includes four steps: selecting some blocks that contain somestale data as vi ...
- 升级 Apache Tomcat的办法
1.下载最新的7系列tomcat cd /usr/local/software wget https://www-us.apache.org/dist/tomcat/tomcat-7/v7.0.92/ ...
- CAS统一登录认证好文汇集贴
悟空的专栏 https://blog.csdn.net/u010475041/article/category/7156505 LinBSoft的专栏 https://blog.csdn.net/ol ...
- Vue2.0 探索之路——生命周期和钩子函数的一些理解
前言 在使用vue一个多礼拜后,感觉现在还停留在初级阶段,虽然知道怎么和后端做数据交互,但是对于mounted这个挂载还不是很清楚的.放大之,对vue的生命周期不甚了解.只知道简单的使用,而不知道为什 ...
- MVC异常处理(异常捕获)
1.cshtml页面异常 2.Controller异常 3.路由参数异常. 4.页面不存在404 页面不存在404,可以通过配置config来处理 <customErrors mode=&quo ...