奇异值分解(SVD)与在降维中的应用
奇异值分解(Singular Value Decomposition,SVD)是在机器学习领域广泛应用的算法,它不光可以用于降维算法中的特征分解,还可以用于推荐系统,以及自然语言处理等领域。是很多机器学习算法的基石。本文就对SVD的原理做一个总结,并讨论在在PCA降维算法中是如何运用运用SVD的。
1. 特征值和特征向量
特征值和特征向量的定义如下:
求出特征值和特征向量有什么好处呢? 就是我们可以将矩阵A特征分解。如果我们求出了矩阵A的n个特征值λ1≤λ2≤...≤λn,以及这n个特征值所对应的特征向量{w1,w2,...wn},那么矩阵A就可以用下式的特征分解表示:A=WΣW−1
其中W是这n个特征向量所张成的n×n维矩阵,而Σ为这n个特征值为主对角线的n×n维矩阵。
一般我们会把W的这n个特征向量标准化,即满足||wi||2=1, 或者说wiTwi=1,此时W的n个特征向量为标准正交基,满足WTW=I,即WT=W−1, 也就是说W为酉矩阵。
这样我们的特征分解表达式可以写成: A=WΣWT
注意到要进行特征分解,矩阵A必须为方阵。那么如果A不是方阵,即行和列不相同时,我们还可以对矩阵进行分解吗?答案是可以,此时我们的SVD登场了。
2. SVD的定义
SVD也是对矩阵进行分解,但是和特征分解不同,SVD并不要求要分解的矩阵为方阵。假设我们的矩阵A是一个m×n的矩阵,那么我们定义矩阵A的SVD为:A=UΣVT
其中U是一个m×m的矩阵,Σ是一个m×n的矩阵,除了主对角线上的元素以外全为0,主对角线上的每个元素都称为奇异值,V是一个n×n的矩阵。U和V都是酉矩阵,即满足UTU=I,VTV=I。下图可以很形象的看出上面SVD的定义:
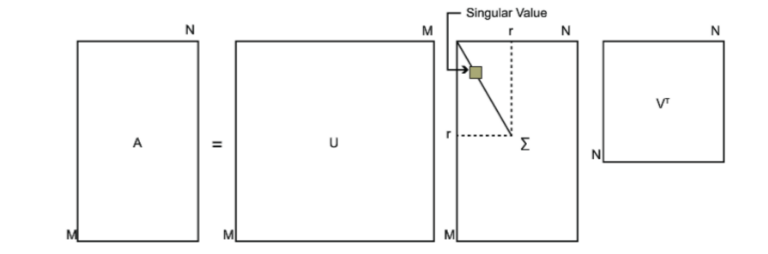
那么我们如何求出SVD分解后的U,Σ,V这三个矩阵呢?
如果我们将A的转置和A做矩阵乘法,那么会得到n×n的一个方阵ATA。既然ATA是方阵,那么我们就可以进行特征分解,得到的特征值和特征向量满足:(ATA)vi=λivi
这样我们就可以得到矩阵ATA的n个特征值和对应的n个特征向量v了。将ATA的所有特征向量张成一个n×n的矩阵V,就是我们SVD公式里面的V矩阵了。一般我们将V中的每个特征向量叫做A的右奇异向量。
如果我们将A和A的转置做矩阵乘法,那么会得到m×m的一个方阵AAT。既然AAT是方阵,那么我们就可以进行特征分解,得到的特征值和特征向量满足:(AAT)ui=λiui
这样我们就可以得到矩阵AAT的m个特征值和对应的m个特征向量u了。将AAT的所有特征向量张成一个m×m的矩阵U,就是我们SVD公式里面的U矩阵了。一般我们将U中的每个特征向量叫做A的左奇异向量。
U和V都求出来了,现在就剩下奇异值矩阵Σ没有求出了。由于Σ除了对角线上是奇异值其他位置都是0,那我们只需要求出每个奇异值σ就可以了。我们注意到:
这样我们可以求出我们的每个奇异值,进而求出奇异值矩阵Σ。
上面还有一个问题没有讲,就是我们说ATA的特征向量组成的就是我们SVD中的V矩阵,而AAT的特征向量组成的就是我们SVD中的U矩阵,这有什么根据吗?这个其实很容易证明,我们以V矩阵的证明为例。A=UΣVT ⇒ AT=VΣTUT ⇒ ATA=VΣTUTUΣVT=VΣ2VT
上式证明使用了:UTU=I,ΣTΣ=Σ2。UTU=I,ΣTΣ=Σ2。可以看出ATA的特征向量组成的就是SVD中的V矩阵。类似的方法可以得到AAT的特征向量组成的就是SVD中的U矩阵。
进一步我们还可以看出我们的特征值矩阵等于奇异值矩阵的平方,也就是说特征值和奇异值满足如下关系:σi=√λi
这样也就是说,我们可以不用σi=Avi/ui来计算奇异值,也可以通过求出ATA的特征值取平方根来求奇异值。
3. SVD的一些性质
上面几节我们对SVD的定义和计算做了详细的描述,似乎看不出我们费这么大的力气做SVD有什么好处。那么SVD有什么重要的性质值得我们注意呢?
对于奇异值,它跟我们特征分解中的特征值类似,在奇异值矩阵中也是按照从大到小排列,而且奇异值的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上的比例。也就是说,我们也可以用最大的k个的奇异值和对应的左右奇异向量来近似描述矩阵。也就是说:Am×n=Um×mΣm×nVTn×n≈Um×kΣk×kVTk×n。其中k要比n小很多,也就是一个大的矩阵A可以用三个小的矩阵Um×k,Σk×k,VTk×n来表示。如下图所示,现在我们的矩阵A只需要灰色的部分的三个小矩阵就可以近似描述了。
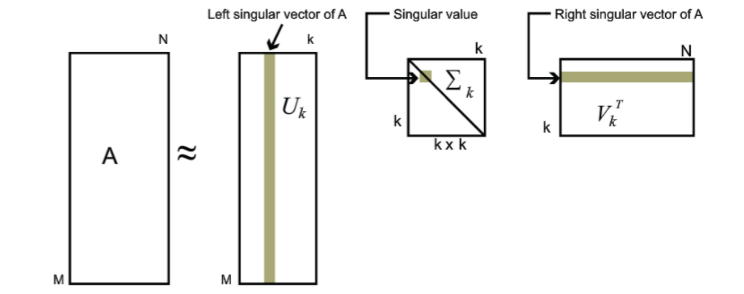
由于这个重要的性质,SVD可以用于PCA降维,来做数据压缩和去噪。也可以用于推荐算法,将用户和喜好对应的矩阵做特征分解,进而得到隐含的用户需求来做推荐。同时也可以用于NLP中的算法,比如潜在语义索引(LSI)。下面我们就对SVD用于PCA降维做一个介绍。
4. SVD用于PCA
在主成分分析(PCA)中,要用PCA降维,需要找到样本协方差矩阵XTX的最大的d个特征向量,然后用这最大的d个特征向量张成的矩阵来做低维投影降维。可以看出,在这个过程中需要先求出协方差矩阵XTX,当样本数多、样本特征数也多的时候,这个计算量是很大的。
注意到我们的SVD也可以得到协方差矩阵XTX最大的d个特征向量组成的矩阵,但是SVD有个好处,有一些SVD的实现算法可以不求先求出协方差矩阵XTX,也能求出我们的右奇异矩阵V。也就是说,我们的PCA算法可以不用做特征分解,而是做SVD来完成。这个方法在样本量很大的时候很有效。实际上,scikit-learn的PCA算法的背后真正的实现就是用的SVD,而不是我们我们认为的暴力特征分解。
另一方面,注意到PCA仅仅使用了我们SVD的右奇异矩阵,没有使用左奇异矩阵,那么左奇异矩阵有什么用呢?
假设我们的样本是m×n的矩阵X,如果我们通过SVD找到了矩阵XXT最大的d个特征向量组成的m×d维矩阵U,则我们如果进行如下处理:X′d×n=UTd×mXm×n
可以得到一个d×n的矩阵X‘,这个矩阵和我们原来的m×n维样本矩阵X相比,行数从m减到了k,可见对行数进行了压缩。也就是说,左奇异矩阵可以用于行数的压缩。相对的,右奇异矩阵可以用于列数即特征维度的压缩,也就是我们的PCA降维。
5. SVD小结
SVD作为一个很基本的算法,在很多机器学习算法中都有它的身影,特别是在现在的大数据时代,由于SVD可以实现并行化,因此更是大展身手。SVD的原理不难,只要有基本的线性代数知识就可以理解,实现也很简单因此值得仔细的研究。当然,SVD的缺点是分解出的矩阵解释性往往不强,有点黑盒子的味道,不过这不影响它的使用。
文章内容转载自:https://www.cnblogs.com/pinard/p/6251584.html
奇异值分解(SVD)与在降维中的应用的更多相关文章
- 机器学习降维方法概括, LASSO参数缩减、主成分分析PCA、小波分析、线性判别LDA、拉普拉斯映射、深度学习SparseAutoEncoder、矩阵奇异值分解SVD、LLE局部线性嵌入、Isomap等距映射
机器学习降维方法概括 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/u014772862/article/details/52335970 最近 ...
- 降维之奇异值分解(SVD)
看了几篇关于奇异值分解(Singular Value Decomposition,SVD)的博客,大部分都是从坐标变换(线性变换)的角度来阐述,讲了一堆坐标变换的东西,整了一大堆图,试图“通俗易懂”地 ...
- 奇异值分解(SVD)原理与在降维中的应用
奇异值分解(Singular Value Decomposition,以下简称SVD)是在机器学习领域广泛应用的算法,它不光可以用于降维算法中的特征分解,还可以用于推荐系统,以及自然语言处理等领域.是 ...
- 【疑难杂症】奇异值分解(SVD)原理与在降维中的应用
前言 在项目实战的特征工程中遇到了采用SVD进行降维,具体SVD是什么,怎么用,原理是什么都没有细说,因此特开一篇,记录下SVD的学习笔记 参考:刘建平老师博客 https://www.cnblogs ...
- [机器学习笔记]奇异值分解SVD简介及其在推荐系统中的简单应用
本文先从几何意义上对奇异值分解SVD进行简单介绍,然后分析了特征值分解与奇异值分解的区别与联系,最后用python实现将SVD应用于推荐系统. 1.SVD详解 SVD(singular value d ...
- 一步步教你轻松学奇异值分解SVD降维算法
一步步教你轻松学奇异值分解SVD降维算法 (白宁超 2018年10月24日09:04:56 ) 摘要:奇异值分解(singular value decomposition)是线性代数中一种重要的矩阵分 ...
- 机器学习实战(Machine Learning in Action)学习笔记————10.奇异值分解(SVD)原理、基于协同过滤的推荐引擎、数据降维
关键字:SVD.奇异值分解.降维.基于协同过滤的推荐引擎作者:米仓山下时间:2018-11-3机器学习实战(Machine Learning in Action,@author: Peter Harr ...
- SVD及其在推荐系统中的作用
本文先从几何意义上对奇异值分解SVD进行简单介绍,然后分析了特征值分解与奇异值分解的区别与联系,最后用python实现将SVD应用于推荐系统. 1.SVD详解 SVD(singular value d ...
- 奇异值分解(SVD)原理详解及推导(转载)
转载请声明出处http://blog.csdn.net/zhongkejingwang/article/details/43053513 在网上看到有很多文章介绍SVD的,讲的也都不错,但是感觉还是有 ...
随机推荐
- Java面试题整理---JVM篇
1.JVM运行时内存区域划分? 2.内存溢出OOM和堆栈溢出SOE的案例.原因.排查及解决? 3.常用的JVM性能监控工具? 4.JVM参数设置? 5.类加载过程? 6.JVM内存 ...
- Node.js学习准备篇
这里写个Node.js 准备篇包含内容有node.js 的安装,命令行运行node.js 文件,使用webStrom 编写 node.js 时有提示功能,并用webStrom 运行 Node.js 其 ...
- 【数据使用】3k水稻数据库现成SNP的使用
---恢复内容开始--- 我们经常说幻想着使用已有数据发表高分文章,的确,这样的童话故事每天都在发生,但如何走出第一步我们很多小伙伴不清楚,那么我们就从水稻SNP数据库的使用来讲起. http://s ...
- binlog的原理
- Java 文件重命名
Java 文件重命名 /** * 重命名文件 * @param fileName * @return */ public static void renameFile(String filePath, ...
- Python Mysql 交互
Mysql 安装Python模块 Linux: yum install MySQL-python Windos: http://files.cnblogs.com/files/wupeiqi/py ...
- 谷歌机翻英文字幕输出(Subtitle Edit)
Subtitle Edit 下载地址(https://github.com/SubtitleEdit/subtitleedit/releases/tag/3.5.0) 添加字幕文件后,点下图的Auto ...
- Ubuntu下 fatal error: Python.h: No such file or directory 解决方法
参考: fatal error: Python.h: No such file or directory Ubuntu下 fatal error: Python.h: No such file or ...
- java基础 (二)之HashMap,HashTable,ConcurrentHashMap区别
HashTable: put方法加了同步锁synchronized,底层数组+链表实现,无论key还是value都不能为null,线程安全,实现线程安全的方式是在修改数据时锁住整个HashTable, ...
- Bellman-Ford算法模板题
POJ 3259 虫洞(Bellman-Ford判断有无负环的问题) 描述: 在探索他的许多农场时,Farmer John发现了许多令人惊叹的虫洞.虫洞是非常奇特的,因为它是一条单向路径,在您进入虫洞 ...