PDF数据提取------3.解析Demo
1.PDF中文本字符串格式中关键值信息抓取(已完成)
简介:这种解析比较传统最简单主要熟练使用Regular Expression做语义识别和验证.例如抓取下面红色圈内关键信息

string mettingData=GetMeetingData();
public string GetMeetingData()
{
string patternAll = @"(?<NDAandCAMDate>会\s*议\s*.{2,15}\d{2,4}\s*年\s*\d{1,2}\s*月\s*\d{1,2}\s*日.{0,15})";
PdfAnalyzer pa = new PdfAnalyzer();
PDFNet.Initialize();
PDFDoc doc = new PDFDoc(item);
doc.InitSecurityHandler();
List<PdfString> foundAll = pa.RegexSearchAllPages(doc, patternAll);
List<string> patternFilter = new List<string>();
patternFilter.Add(@"(?<year>\d{2,4})年(?<month>\d{1,2})月(?<day>\d{1,2})日((\(|\()(星期|周)(一|二|三|四|五|六|七)(\)|\)))?(上午)?(?<hour>\d{1,2})(\:|点|时)(?<minute>\d{1,2})");
patternFilter.Add(@"(?<year>\d{2,4})年(?<month>\d{1,2})月(?<day>\d{1,2})日((\(|\()(星期|周)(一|二|三|四|五|六|七)(\)|\)))?下午(?<hour>\d{1,2})(\:|点|时)(?<minute>\d{1,2})");
patternFilter.Add(@"(?<year>\d{2,4})年(?<month>\d{1,2})月(?<day>\d{1,2})日((\(|\()(星期|周)(一|二|三|四|五|六|七)(\)|\)))?(上午)?(?<hour>\d{1,2})点半");
patternFilter.Add(@"(?<year>\d{2,4})年(?<month>\d{1,2})月(?<day>\d{1,2})日((\(|\()(星期|周)(一|二|三|四|五|六|七)(\)|\)))?下午(?<hour>\d{1,2})点半");
patternFilter.Add(@"(?<year>\d{2,4})年(?<month>\d{1,2})月(?<day>\d{1,2})日((\(|\()(星期|周)(一|二|三|四|五|六|七)(\)|\)))?(上午)?(?<hour>\d{1,2})(点|时)");
patternFilter.Add(@"(?<year>\d{2,4})年(?<month>\d{1,2})月(?<day>\d{1,2})日((\(|\()(星期|周)(一|二|三|四|五|六|七)(\)|\)))?下午(?<hour>\d{1,2})(点|时)");
patternFilter.Add(@"(?<year>\d{2,4})年(?<month>\d{1,2})月(?<day>\d{1,2})日");
return GetMeetingDateFilter(foundAll, patternAll);
}
private string GetMeetingDateFilter(List<PdfString> foundAll, List<string> patternAll)
{
string meetingDate = " ";
Match ma = null;
string result = string.Empty;
foreach (PdfString pdfString in foundAll)
{
result = pdfString.ToString().Replace(" ", "");
for (int i = ; i < patternAll.Count; i++)
{
ma = (new Regex(patternAll[i])).Match(result);
if (ma.Success)
{
if (IsValid(ma))
return meetingDate;
else
meetingDate = " ";
}
}
}
return meetingDate;
}
注解:
a.第一次通过通过 pa.RegexSearchAllPages(doc, patternAll);搜索所有关于时间数据信息
b.第二次通过正则匹配获取带有关键词信息Meeting Data
2.PDF类似表格形式关键值数据抓取。(已完成)
简介:这种格式需要用的封装数据结构PdfString类和PdfAnalyzer类,根据给定关键词在指定范围提取数据,例如提取下面数据。
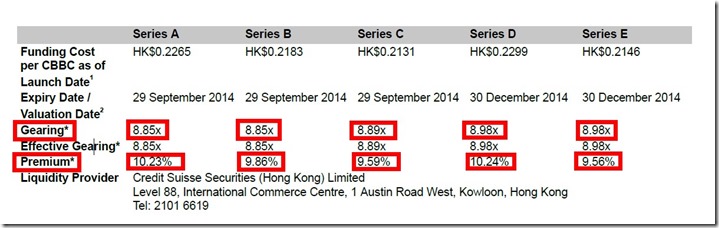
private string GetPremium(string path, string ricCode)
{
string result = string.Empty;
PDFDoc doc = null;
try
{
PDFNet.Initialize();
doc = new PDFDoc(path);
doc.InitSecurityHandler(); if (doc == null)
{
string msg = string.Format("can't load pdf to doc = new PDFDoc({0}); ", path);
Logger.Log(msg, Logger.LogType.Error);
return result;
} int x1 = ;
int y1 = ;
PdfAnalyzer pa = new PdfAnalyzer();
List<PdfString> listX1 = pa.RegexSearchAllPages(doc, ricCode);
List<PdfString> listY1 = pa.RegexSearchAllPages(doc, @"[P|p]remium");
List<PdfString> listResult = pa.RegexSearchAllPages(doc, @"(?<Result>\d+\.\d+\%)"); if (listX1.Count == || listY1.Count == || listResult.Count == )
{
string msg = string.Format("({0}),([P|p]remium) exist missing value ,so Gearing is empty value.", ricCode);
Logger.Log(msg, Logger.LogType.Warning);
return result;
} x1 = System.Convert.ToInt32(listX1[].Position.x1);
y1 = System.Convert.ToInt32(listY1[].Position.y1); int subX1 = ;
int subY1 = ;
//use Gearing position (x1,y1) to get the right result value
foreach (var item in listResult)
{
subX1 = x1 - System.Convert.ToInt32(item.Position.x1);
if (subX1 < ) subX1 = - subX1;
subY1 = y1 - System.Convert.ToInt32(item.Position.y1);
if (subY1 < ) subY1 = - subY1; if (subX1 <= && subY1 <= )
{
result = item.ToString().Replace("%", "");
return result;
}
} Logger.Log(string.Format("stock code:{0},extract premium failed .", ricCode), Logger.LogType.Error);
return result;
}
catch (Exception ex)
{
string msg = string.Format("PDF analysis failed for " + ricCode + "! Action: Need manually input gearing and premium \r\n error msg:{0}", ex.Message);
Logger.Log(msg, Logger.LogType.Warning);
return result;
}
}
3.需要PDF中大量数据转换到Excel中去 (已完成)
简介:基与2的延伸,加入一个自动模糊匹配到行和列边界范围,根据位置坐标排序提取正确数据信息。如图:
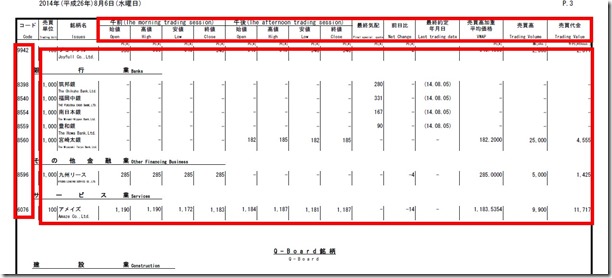
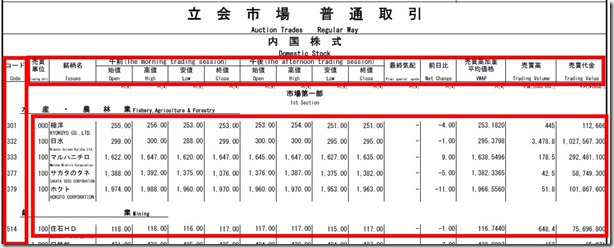
private void StartExtractFile()
{
List<List<string>> bulkFileFilter = null;
List<LineFound> bulkFile = null;
PDFNet.Initialize();
PDFDoc doc = new PDFDoc(config.FilePath1);
doc.InitSecurityHandler();
string patternTitle = @"コード";
int page = ;
PdfString ricPosition = GetRicPosition(doc, patternTitle, page);
if (ricPosition == null)
return; string patternRic = @"\d{4}";
string patternValue = @"(\-|\+)?\d+(\,|\.|\d)+";
bulkFile = GetValue(doc, ricPosition, patternRic, patternValue);
int indexOK = ;
bulkFileFilter = FilterBulkFile(bulkFile, indexOK);
string filePath = Path.Combine(config.OutputFolder, string.Format("Type1ExtractedFromPdf{0}.csv", DateTime.Now.ToString("dd-MM-yyyy"))); if (File.Exists(filePath))
File.Delete(filePath); XlsOrCsvUtil.GenerateStringCsv(filePath, bulkFileFilter);
AddResult(Path.GetFileNameWithoutExtension(filePath), filePath, "type1");
} private List<List<string>> FilterBulkFile(List<LineFound> bulkFile, int indexOK)
{
List<List<string>> result = new List<List<string>>(); if (bulkFile == null || bulkFile.Count == )
{
Logger.Log("no value data extract from pdf");
return null;
}
int count = bulkFile[indexOK].LineData.Count; List<string> line = null;
foreach (var item in bulkFile)
{
if (item.LineData == null || item.LineData.Count <= )
continue; line = new List<string>();
if (item.LineData.Count.CompareTo(count) == )
{
foreach (var value in item.LineData)
{
line.Add(value.Words.ToString());
}
}
else
{
line.Add(item.LineData[].Words.ToString());
for (int i = ; i < count; i++)
{
line.Add(string.Empty);
}
}
result.Add(line);
} return result;
} private List<LineFound> GetValue(PDFDoc doc, PdfString ricPosition, string patternRic, string patternValue)
{
List<LineFound> bulkFile = new List<LineFound>();
try
{
List<string> line = new List<string>();
List<PdfString> ric = null; //for (int i = 1; i < 10; i++)
for (int i = ; i < doc.GetPageCount(); i++)
{
ric = pa.RegexExtractByPositionWithPage(doc, patternRic, i, ricPosition.Position);
foreach (var item in ric)
{
LineFound lineFound = new LineFound();
lineFound.Ric = item.Words.ToString();
lineFound.Position = item.Position;
lineFound.PageNumber = i;
lineFound.LineData = pa.RegexExtractByPositionWithPage(doc, patternValue, i, item.Position, PositionRect.X2);
bulkFile.Add(lineFound);
}
}
}
catch (Exception ex)
{
string msg = string.Format("\r\n ClassName: {0}\r\n MethodName: {1}\r\n Message: {2}",
System.Reflection.MethodBase.GetCurrentMethod().DeclaringType.ToString(),
System.Reflection.MethodBase.GetCurrentMethod().Name,
ex.Message);
Logger.Log(msg, Logger.LogType.Error);
} return bulkFile;
} private PdfString GetRicPosition(PDFDoc doc, string pattern, int page)
{
try
{
List<PdfString> ricPosition = null;
ricPosition = pa.RegexSearchByPage(doc, @"コード", page);
if (ricPosition == null || ricPosition.Count == )
{
Logger.Log(string.Format("there is no ric title found by using pattern:{0} to find the ric title ,in the page:{1} of the pdf:{2}"));
return null;
} return ricPosition[];
}
catch (Exception ex)
{
string msg = string.Format("\r\n ClassName: {0}\r\n MethodName: {1}\r\n Message: {2}",
System.Reflection.MethodBase.GetCurrentMethod().DeclaringType.ToString(),
System.Reflection.MethodBase.GetCurrentMethod().Name,
ex.Message);
Logger.Log(msg, Logger.LogType.Error);
throw;
}
}
} struct LineFound
{
public string Ric { get; set; }
public Rect Position { get; set; }
public int PageNumber { get; set; }
public List<PdfString> LineData { get; set; }
}
注解:
a.由于PDF中数据坐标位置信息是基于页的所以必须按页来解析抓取数据
b.大概思路,第一次获取“コード”位置,来获取每页中Ric List的集合(获取列并排序)
c.根据每一列信息获取每一行信息(获取并排序),组合成表格信息
改进:
现在这部分还需要代码中手动干预,下一步打算加入自动识别功能,通过获取大量PDF数据自动根据位置信息组合成Table信息
4.PDF中数据保存图片格式(未完成)
想法:这种PDF文件我目前还没好的处理办法,应该需要用到图像识别方面的算法。对着这种文件格式表示我现在确实无能为力,
希望那位大神提供一些好的建议。
PDF数据提取------3.解析Demo的更多相关文章
- PDF数据提取------2.相关类介绍
1.简介 构造数据类型PdfString封装Rect类,PdfAnalyzer类中定义一些PDF解析方法. 2.PdfString类与Rect类 public class PdfString : IC ...
- Python爬虫10-页面解析数据提取思路方法与简单正则应用
GitHub代码练习地址:正则1:https://github.com/Neo-ML/PythonPractice/blob/master/SpiderPrac15_RE1.py 正则2:match. ...
- Python爬虫教程-18-页面解析和数据提取
本篇针对的数据是已经存在在页面上的数据,不包括动态生成的数据,今天是对HTML中提取对我们有用的数据,去除无用的数据 Python爬虫教程-18-页面解析和数据提取 结构化数据:先有的结构,再谈数据 ...
- 转:SQL SERVER数据库中实现快速的数据提取和数据分页
探讨如何在有着1000万条数据的MS SQL SERVER数据库中实现快速的数据提取和数据分页.以下代码说明了我们实例中数据库的“红头文件”一表的部分数据结构: CREATE TABLE [dbo]. ...
- PHP实例 表单数据插入数据库及数据提取 用户注册验证
网站在进行新用户注册时,都会将用户的注册信息存入数据库中,需要的时候再进行提取.今天写了一个简单的实例. 主要完成以下几点功能: (1)用户进行注册,实现密码重复确认,验证码校对功能. (2)注册成功 ...
- SQL 正则表达式使模式匹配和数据提取变得更容易
SQL Server 2005 正则表达式使模式匹配和数据提取变得更容易 David Banister 本文讨论: 使用正则表达式进行高效的 SQL 查询 SQL Server 2005 对正则表达式 ...
- PHP+Mysql-表单数据插入数据库及数据提取完整过程
网站在进行新用户注册时,都会将用户的注册信息存入数据库中,需要的时候再进行提取.今天写了一个简单的实例. 主要完成以下几点功能: (1)用户进行注册,实现密码重复确认,验证码校对功能. (2)注册成功 ...
- PHP+Mysql————表单数据插入数据库及数据提取
站点在进行新用户注冊时,都会将用户的注冊信息存入数据库中,须要的时候再进行提取.今天写了一个简单的实例. 主要完毕下面几点功能: (1)用户进行注冊,实现password反复确认,验证码校对功能. ( ...
- Struts2 Action接收POST请求JSON数据及其实现解析
一.认识JSON JSON是一种轻量级.基于文本.与语言无关的数据交换格式,可以用文本格式的形式来存储或表示结构化的数据. 二.POST请求与Content-Type: application/jso ...
随机推荐
- Array.prototype.slice.call(document.querySelectorAll('a'), 0)
Array.prototype.slice.call(document.querySelectorAll('a'), 0)的作用就是将一个DOM NodeList 转换成一个数组. slice()方法 ...
- 在db2中 两个数据库之间的两个表的联合查询
大家好,今天遇到了在db2中 两个数据库之间的两个表的联合查询 我知道oracle中有dblink,可是不知到db2的两个数据库联合查询怎么处理我找了类似于比如两个数据库: db1,db2用户名密码s ...
- 311. Sparse Matrix Multiplication
题目: Given two sparse matrices A and B, return the result of AB. You may assume that A's column numbe ...
- Data Flow ->> Look up & Merge Join
Look up: Look up组件做的事情和SQL SERVER中的inner和outer hash join差不多. 但是look up每次只能有两张表参与. 在FULL-CACHE模式下,两个s ...
- uploadify+批量上传文件+java
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding= ...
- git merge简介【转】
转自:http://blog.csdn.net/hudashi/article/details/7664382 git merge的基本用法为把一个分支或或某个commit的修改合并现在的分支上.我们 ...
- 文件夹工具类 - FolderUtils
文件夹工具类,提供创建完整路径的方法. 源码如下:(点击下载 -FolderUtils.java .commons-io-2.4.jar ) import java.io.File; import o ...
- IO(一)
文件相关 package com.bjsxt.io.file; import java.io.File; /** * 两个常量 * 1.路径分隔符 ; * 2.名称分隔符 /(windows) /(l ...
- Android模拟器使用教程
Using the Emulator In this document Overview Android Virtual Devices and the Emulator Starting and S ...
- 数据库系统中事务的ACID原则
事务的原子性.一致性.独立性及持久性 事务的原子性是指一个事务要么全部执行,要么不执行.也就是说一个事务不可能只执行了一半就停止了.比如你从取款机取钱,这个事务可以分成两个步骤:1划卡,2出钱.不可能 ...