Hadoop1.0 与Hadoop2.0
.png)
Hadoop1.0 与Hadoop2.0的更多相关文章
- Hadoop1.0 和 Hadoop2.0
date: 2018-11-16 18:54:37 updated: 2018-11-16 18:54:37 1.从Hadoop整体框架来说 1.1 Hadoop1.0即第一代Hadoop,由分布式存 ...
- Hadoop2.0的基本构成总览
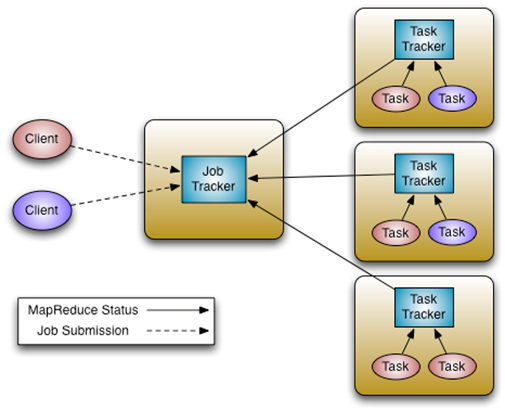
Hadoop1.x和Hadoop2.0构成图对比 Hadoop1.x构成: HDFS.MapReduce(资源管理和任务调度):运行时环境为JobTracker和TaskTracker: Hadoop ...
- Hadoop2.0(HDFS2)以及YARN设计的亮点
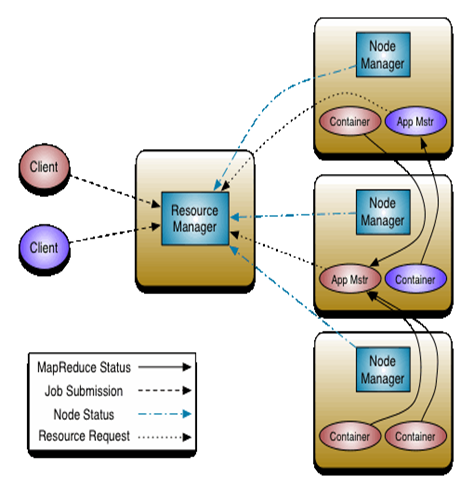
YARN总体上仍然是Master/Slave结构,在整个资源管理框架中,ResourceManager为Master,NodeManager为Slave,ResouceManager负责对各个Node ...
- hadoop2.2.0 + hbase 0.94 + hive 0.12 配置记录
一开始用hadoop2.2.0 + hbase 0.96 + hive 0.12 ,基本全部都配好了.只有在hive中查询hbase的表出错.以直报如下错误: java.io.IOException: ...
- Cloudera Hadoop 5& Hadoop高阶管理及调优课程(CDH5,Hadoop2.0,HA,安全,管理,调优)
1.课程环境 本课程涉及的技术产品及相关版本: 技术 版本 Linux CentOS 6.5 Java 1.7 Hadoop2.0 2.6.0 Hadoop1.0 1.2.1 Zookeeper 3. ...
- hadoop2.0的datanode数据存储文件夹策略的多个副本
在hadoop2.0在,datanode数据存储盘选择策略有两种方式复制: 首先是要遵循hadoop1.0磁盘文件夹投票,实现类:RoundRobinVolumeChoosingPolicy.java ...
- hadoop2.0的数据副本存放策略
在hadoop2.0中,datanode数据副本存放磁盘选择策略有两种方式: 第一种是沿用hadoop1.0的磁盘目录轮询方式,实现类:RoundRobinVolumeChoosingPolicy.j ...
- HDP2.0.6+hadoop2.2.0+eclipse(windows和linux下)调试环境搭建
花了好几天,搭建好windows和linux下连接HDP集群的调试环境,在此记录一下 hadoop2.2.0的版本比hadoop0.x和hadoop1.x结构变化很大,没有eclipse-hadoop ...
- Hadoop2.0源码包简介
Hadoop2.0源码包简介 1.解压源码包: 2.目录结构: hadoop-common-project:Hadoop基础库所在目录,如RPC.Metrics.Counter等.包含了其它所有模块可 ...
随机推荐
- LeetCode-Container With Most Water-zz
先上代码. #include <iostream> #include <vector> #include <algorithm> using namespace s ...
- 使用WdatePicker日期组件时,选择日期后,执行某个方法
WdatePicker({onpicked:function(){alert(123);},dateFmt:'yyyy年MM月dd日',maxDate:'%y-%M-%d'}) 1.onpicked: ...
- stream操作 z
常见并常用的stream一共有 文件流(FileStream), 内存流(MemoryStream), 压缩流(GZipStream), 加密流(CrypToStream), 网络流(NetworkS ...
- Beyond Compare 4的试用期过了怎么办
修改配置文件(C:\Users\gaojs\AppData\Roaming\BCompare\BCompare.ini)中的时间戳. 时间戳在线转换:https://tool.lu/timestamp ...
- Win10安装msi程序报错2503和2502错误解决方案
刚升级了系统到win10,重新搭建开发环境,在安装scala的时候一直报2503.2502错误,如图 试了好几种办法都不好使,现在罗列依次用到的三种方法: 一.命令提示符(管理员)启动 "w ...
- SAP R/3系统的R和3分别代表什么含义,负载均衡的实现原理
1972年,SAP诞生,推出了RF系统(实时财务会计系统), 后来命名为R1. R指Real time.3既指第三代系统,又代表3层架构. 三层架构分别为下图的Presentation server ...
- bzoj2331 [SCOI2011]地板
Description lxhgww的小名叫“小L”,这是因为他总是很喜欢L型的东西.小L家的客厅是一个的矩形,现在他想用L型的地板来铺满整个客厅,客厅里有些位置有柱子,不能铺地板.现在小L想知道,用 ...
- swift菜鸟入门视频教程-02-基本运算符
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/mengxiangyue/article/details/32435435 本人自己录制的swift菜 ...
- BZOJ4530:[BJOI2014]大融合(LCT)
Description 小强要在N个孤立的星球上建立起一套通信系统.这套通信系统就是连接N个点的一个树. 这个树的边是一条一条添加上去的.在某个时刻,一条边的负载就是它所在的当前能够 联通的树上路过它 ...
- VS2008 工具栏CMFCToolBar的使用总结(转)
(一)自定义工具栏 自定义工具栏,分两种情况:一是直接添加工具栏,并自己绘制图标:二是,添加工具栏,然后与BMP关联,与VC6.0中的自定义彩色工具栏类似. 1. 自绘工具栏 1)添加Toolbar ...