Spark(Hive) SQL中UDF的使用(Python)





Spark(Hive) SQL中UDF的使用(Python)的更多相关文章
- Spark(Hive) SQL中UDF的使用(Python)【转】
相对于使用MapReduce或者Spark Application的方式进行数据分析,使用Hive SQL或Spark SQL能为我们省去不少的代码工作量,而Hive SQL或Spark SQL本身内 ...
- Spark(Hive) SQL数据类型使用详解(Python)
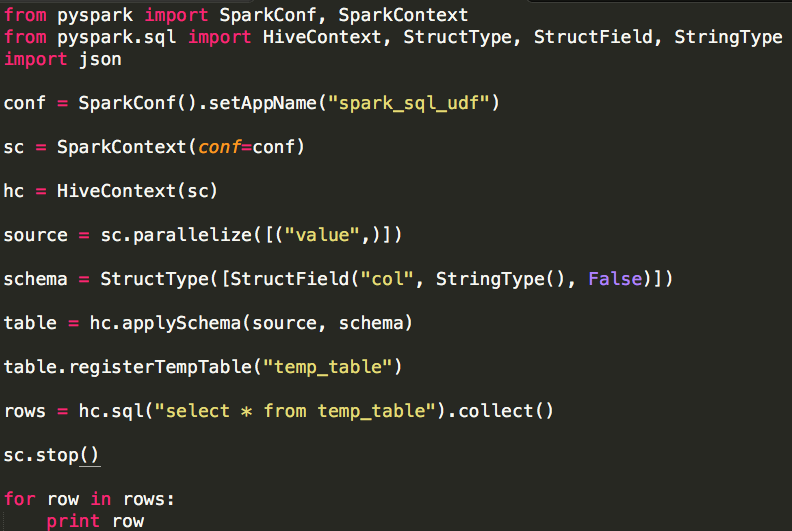
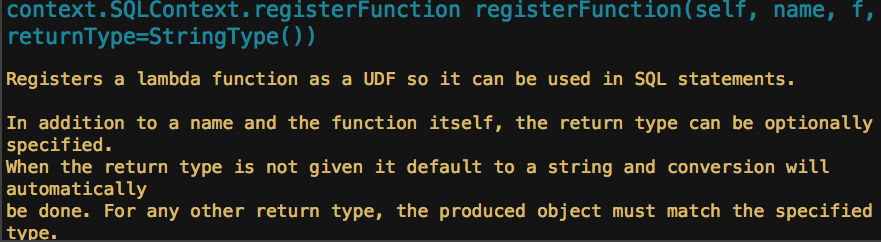
Spark SQL使用时需要有若干“表”的存在,这些“表”可以来自于Hive,也可以来自“临时表”.如果“表”来自于Hive,它的模式(列名.列类型等)在创建时已经确定,一般情况下我们直接通过Spar ...
- Spark SQL中UDF和UDAF
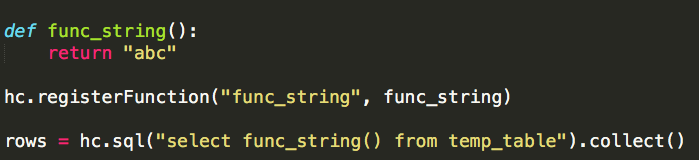
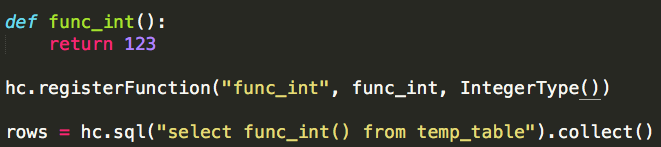
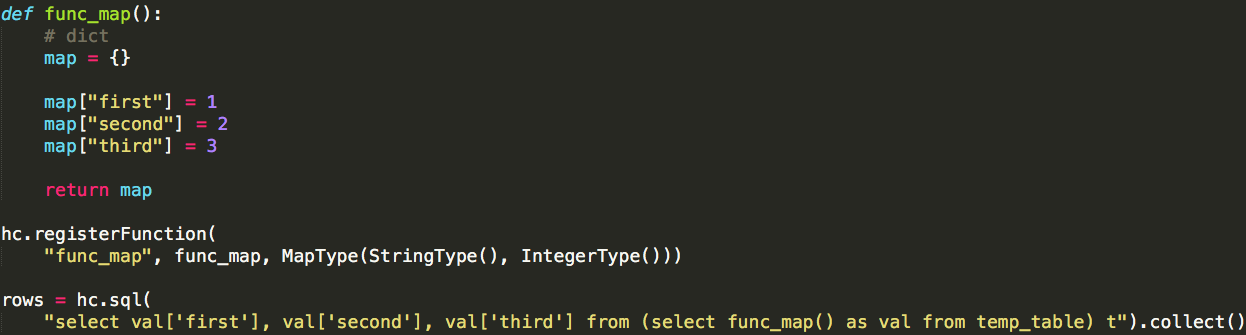
转载自:https://blog.csdn.net/u012297062/article/details/52227909 UDF: User Defined Function,用户自定义的函数,函数 ...
- 两种方式— 在hive SQL中传入参数
第一种: sql = sql.format(dt=dt) 第二种: item_third_cate_cd_list = " 发发发 " ...... ""&qu ...
- Hive SQL 编译过程
转自:http://www.open-open.com/lib/view/open1400644430159.html Hive跟Impala貌似都是公司或者研究所常用的系统,前者更稳定点,实现方式是 ...
- 【转】Hive SQL的编译过程
Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是基于Hive搭建,每天执行近万次的Hive ETL计算流程,负责每天数百GB的数据存储和分析.Hive的稳定性和 ...
- Hive SQL的编译过程
文章转自:http://tech.meituan.com/hive-sql-to-mapreduce.html Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是 ...
- 转:Hive SQL的编译过程
Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是基于Hive搭建,每天执行近万次的Hive ETL计算流程,负责每天数百GB的数据存储和分析.Hive的稳定性和 ...
- Hive SQL的编译过程[转载自https://tech.meituan.com/hive-sql-to-mapreduce.html]
https://tech.meituan.com/hive-sql-to-mapreduce.html Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是基于Hi ...
随机推荐
- Python教程:连接数据库,对数据进行增删改查操作
各位志同道合的同仁可以点击上方关注↑↑↑↑↑↑ 本教程致力于程序员快速掌握Python语言编程. 本文章内容是基于上次课程Python教程:操作数据库,MySql的安装详解 和python基础知识之上 ...
- 隐藏元素的宽高无法通过原生js获取的问题
1.起源:移动app项目中,页面加载时需要加载国家下拉列表,将隐藏的透明浮层和一个显示加载过程中的框 显示出来,隐藏的透明浮层设置宽高都是100%即可,而这个加载提示框需要先得出它的宽高,然后再根据页 ...
- Python初学记录
发音: 拍怂 语系:类C 特点: 1语句控制不用{}和(),而是强制用户空格或tab缩进.空格和tab数量不一定. 2解释性语言,不需要事先声明变量,即写即用. 3.list 列表可存放多种类型数据. ...
- C#中堆和栈的区别分析(有待更新总结)
转载:http://blog.csdn.net/zevin/article/details/5721495 一.预备知识-程序的内存分配 一个由C/C++编译的程序占用的内存分为以下几个部分 1.栈区 ...
- Mysql DB2等数据库分页的实现
一.Mysql的分页 (一).MySQL分页的实现,使用关键字:Limit 语法:select * from tableName Limit A,B; 注释:tableName:表名 A:查询的 ...
- 配置hive元数据库mysql时候出现 Unable to find the JDBC database jar on host : master
解决办法: cd /usr/share/java/,(没有java文件夹,自行创建)rz mysql-connector-java-***.jar,mv mysql-connector-java-* ...
- Set集合中的HashSet集合
HashSet集合的特点:元素是具备唯一性的,每次存储都要先算出哈希值,看有没相同,没有相同的存储到相应的位置,如果相同则再判断存储进来的值是否与被比较的相同,如果相同,则不再存储,不同就存储 pac ...
- PHP 编译问题PEAR package PHP_Archive not installed的解决
php 的编译时需要依赖pear package ,目前的问题错误"PEAR package PHP_Archive not installed",已经明显报出这个问题. 因此编译 ...
- PHP常用数组函数
一.数组操作的基本函数 数组的键名和值 array_values($arr); 获得数组的值 array_keys($arr); 获得数组的键名 array_flip($arr); 数组中的 ...
- css字体大小设置em与rem的区别
em 单位em是相对于父元素的,如果父元素没有设置字体大小,那就会追溯到body. 比如 如果我在box_text的父元素box加了一个字体大小 那么body的8px就会被box_text的父元 ...