python 线程理解
简介
一个应用程序由多个进程组成,一个进程有多个线程,一个线程则是操作系统调度的最小单位,当应用程序运行时,操作系统根据优先级和时间片调度线程(决定此时此刻执行哪个线程)。
python的线程
python存在多个解释器,cpython、jpython等,但目前主流常用的则是cpython,其存在GIL锁,从而导致无论你启多少个线程,你有多少个cpu, Python在执行的时候会淡定的在同一时刻只允许一个线程运行,因此适用于io密集型程序,由于读写io需要时间且python线程只能在一个cpu运行,可以在io的时间中来回切换线程,进一步提高效率
python为什么要加锁
进行定期自动内存回收
加入GIL主要的原因是为了降低程序的开发的复杂度,比如现在的你写python不需要关心内存回收的问题,因为Python解释器帮你自动定期进行内存回收,你可以理解为python解释器里有一个独立的线程,每过一段时间它起wake up做一次全局轮询看看哪些内存数据是可以被清空的,此时你自己的程序 里的线程和 py解释器自己的线程是并发运行的,假设你的线程删除了一个变量,py解释器的垃圾回收线程在清空这个变量的过程中的clearing时刻,可能一个其它线程正好又重新给这个还没来及得清空的内存空间赋值了,结果就有可能新赋值的数据被删除了,为了解决类似的问题,python解释器简单粗暴的加了锁,即当一个线程运行时,其它人都不能动,这样就解决了上述的问题, 这可以说是Python早期版本的遗留问题。
python线程的常用创建方式
1.类方式创建,需要继承threading.Thread类,必须要在构造函数中初始化thread的init方法,线程方法需要重写run方法
import threading, time, os
class MyThread(threading.Thread):
def __init__(self, name):
threading.Thread.__init__(self, name=name)
self.name = name
def run(self):
time.sleep(10)
print(f"MyThread run:{self.name}")
print(f'pid:{os.getpid()}')
t = MyThread(name='test')
t2 = MyThread(name='test2')
t.run()
t2.run()
2.函数式创建线程,需要注意的是在函数传参时如果只有一个值,需要在后面添加逗号
import threading, time
def run(name):
time.sleep(10)
print(f"Thread run:{name}")
t1 = threading.Thread(target=run, args=('test1',))
t2 = threading.Thread(target=run, args=('test2',))
t1.start()
t2.start()
python 线程间通信
1.全局变量,一个线程写入,一个线程读取
from typing import List
MSG_LIST:List = []
import threading
def send(msg):
global MSG_LIST
MSG_LIST.append(msg)
def get():
global MSG_LIST
for msg in MSG_LIST:
print(f'recvmsg:{msg}')
MSG_LIST.remove(msg)
t_list = []
for i in range(5):
t = threading.Thread(target=send, args=('msg'+str(i),))
t2 = threading.Thread(target=get)
t.start()
t2.start()
t.join()
t2.join()
2.队列
与全局变量类似,不过方便了编写
import threading, queue
q = queue.Queue()
def send(msg):
global q
q.put(msg)
def get():
global q
print(f'msg:{q.get_nowait()}')
t_list = []
for i in range(5):
t = threading.Thread(target=send, args=('msg'+str(i),))
t2 = threading.Thread(target=get)
t.start()
t2.start()
t.join()
t2.join()
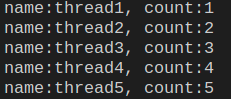
python线程数据不一致问题
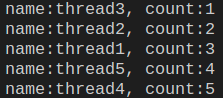
在多线程操作数据时,会导致脏数据、数据不一致的情况,如下所示:
count = 0
import threading, time
def run(name):
global count
time.sleep(5)
count += 1
print(f'name:{name}, count:{count}')
t_list = []
for i in range(5):
t:threading.Thread = threading.Thread(target=run, args=('thread' + str(i+1), ))
t_list.append(t)
t.start()
for t in t_list:
t.join()
为了解决上述问题,需要采取加锁的方式,方式如下:
1.互斥锁(Lock)
使用threading中的Lock模块,只需要将函数或方法中的操作逻辑加上对应的锁即可,此方法可以解决一般的数据不一致问题,但是如果锁发生嵌套,则可能会出现死锁问题
count = 0
import threading, time
lock = threading.Lock()
def run(name):
global count
lock.acquire()
time.sleep(5)
count += 1
print(f'name:{name}, count:{count}')
lock.release()
t_list = []
for i in range(5):
t:threading.Thread = threading.Thread(target=run, args=('thread' + str(i+1), ))
t_list.append(t)
t.start()
for t in t_list:
t.join()
2.如上Lock所写,Lock嵌套可能会出现死锁的问题,如下由于Lock使用了嵌套,则会导致线程发生阻塞,导致死锁问题
count = 0
import threading, time
lock = threading.Lock()
def run(name):
global count
lock.acquire()
time.sleep(5)
count += 1
lock.acquire()
count -= 1
lock.release()
print(f'name:{name}, count:{count}')
lock.release()
t_list = []
for i in range(5):
t:threading.Thread = threading.Thread(target=run, args=('thread' + str(i+1), ))
t_list.append(t)
t.start()
for t in t_list:
t.join()
因此需要使用嵌套锁RLock
count = 0
import threading, time
lock = threading.RLock()
def run(name):
global count
lock.acquire()
time.sleep(5)
count += 1
lock.acquire()
count += 1
lock.release()
print(f'name:{name}, count:{count}')
lock.release()
t_list = []
for i in range(5):
t:threading.Thread = threading.Thread(target=run, args=('thread' + str(i+1), ))
t_list.append(t)
t.start()
for t in t_list:
t.join()
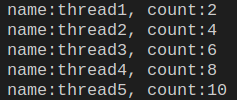
3.信号量(Semaphore)
互斥锁 同时只允许一个线程更改数据,而Semaphore是同时允许一定数量的线程更改数据
count = 0
import threading, time
lock = threading.Semaphore(4)
def run(name):
global count
lock.acquire()
time.sleep(5)
count += 1
print(f'name:{name}, count:{count}')
lock.release()
t_list = []
for i in range(5):
t:threading.Thread = threading.Thread(target=run, args=('thread' + str(i+1), ))
t_list.append(t)
t.start()
for t in t_list:
t.join()
结果虽然都是一样的,但是在实际运行过程中,则会4个线程‘同时’运行,此处同时起始只是人眼可见的,实际上还是依次运行的,不过运行较快
Semaphore原理:相当于早晚班倒
内部存在一个计数器,acquire时-1 release时+1, 当计数器为0时则阻塞, 当有线程释放时则会继续执行相关信息,不需要全部释放后才可以继续执行
计数器的数量取决于设置的n的数量, 默认是1
4.条件(Condition)
import threading, time
count = 0
con = threading.Condition()
def producer():
global count
con.acquire()
time.sleep(5)
count += 1
con.notify()
con.release()
def customer():
global count
con.acquire()
con.wait(timeout=10)
print(f'count:{count}')
con.release()
c = threading.Thread(target=customer)
c.start()
p = threading.Thread(target=producer)
p.start()
Condition原理: 类似与生产消费者模式
python 条件变量Condition也需要关联互斥锁,同时Condition自身提供了wait/notify/notifyAll方法,用于阻塞/通知其他并行线程,可以访问共享资源了。
Condition提供了一种多线程通信机制,假如线程1需要数据,那么线程1就阻塞等待,这时线程2就去制造数据,线程2制造好数据后,通知线程1可以去取数据了,然后线程1去获取数据。
内部使用互斥锁,双层锁结构
5.event(事件):适用于两个线程间通信
import threading, time
count = 0
event = threading.Event()
def run1():
global count
count += 1
print(f'event:flag:before:{event.isSet()}')
time.sleep(10)
event.set()
print(f'event:flag:after:{event.isSet()}')
def run2():
global count
event.wait()
print(f'count:{count}')
t1 = threading.Thread(target=run2)
t2 = threading.Thread(target=run1)
t1.start()
t2.start()
event原理:
python线程的事件用于主线程控制其他线程的执行,事件主要提供了三个方法 set、wait、clear。
默认 event flag为false
事件处理的机制:全局定义了一个“Flag”,如果“Flag”值为 False,那么当程序执行 event.wait 方法时就会阻塞,如果“Flag”值为True,那么event.wait 方法时便不再阻塞。
clear:将“Flag”设置为False
set:将“Flag”设置为True
线程池
使用submit创建单个线程
from concurrent.futures import ThreadPoolExecutor
import time
def run(n, m):
print(f'{n} thread is starting')
time.sleep(3)
print(f'{n} thread is finish')
return n, m
t = ThreadPoolExecutor(4)
ret_list = []
for i in range(5):
# 创建单个线程
ret = t.submit(run, n=i, m=i+1)
ret_list.append(ret)
for ret in ret_list:
print(ret.result())
使用map批量创建线程
需要使用args中间传递值,结果会在最后返回
from concurrent.futures import ThreadPoolExecutor
import time
def run(n, m):
print(f'{n} thread is starting')
time.sleep(3)
print(f'{n} thread is finish')
return n, m
def run_map(args):
print(args)
print(*args)
return run(*args)
t = ThreadPoolExecutor(4)
ret = t.map(run_map, [(1,2)])
print(list(ret))
死锁问题
1.什么是死锁?
死锁是由于两个或以上的线程互相持有对方需要的资源,且都不释放占有的资源,导致这些线程处于等待状态,程序无法执行。
2.产生死锁的四个必要条件
1.互斥性:线程对资源的占有是排他性的,一个资源只能被一个线程占有,直到释放。
2.请求和保持条件:一个线程对请求被占有资源发生阻塞时,对已经获得的资源不释放。
3.不剥夺:一个线程在释放资源之前,其他的线程无法剥夺占用。
4.循环等待:发生死锁时,线程进入死循环,永久阻塞。
3.产生死锁的原因
在多线程的场景,比如线程A持有独占锁资源a,并尝试去获取独占锁资源b同时,线程B持有独占锁资源b,并尝试去获取独占锁资源a。
这样线程A和线程B相互持有对方需要的锁,从而发生阻塞,最终变为死锁。
造成死锁的原因可以概括成三句话:
1.不同线程同时占用自己锁资源
2.这些线程都需要对方的锁资源
3.这些线程都不放弃自己拥有的资源
注意事项
1.建议创建线程时对每一个线程起一个名称,方便后期出现问题后定位问题
python 线程理解的更多相关文章
- PYTHON线程知识再研习A
前段时间看完LINUX的线程,同步,信息号之类的知识之后,再在理解PYTHON线程感觉又不一样了. 作一些测试吧. thread:模块提供了基本的线程和锁的支持 threading:提供了更高级别,功 ...
- Python 线程(threading) 进程(multiprocessing)
*:first-child { margin-top: 0 !important; } body>*:last-child { margin-bottom: 0 !important; } /* ...
- python线程同步原语--源码阅读
前面两篇文章,写了python线程同步原语的基本应用.下面这篇文章主要是通过阅读源码来了解这几个类的内部原理和是怎么协同一起工作来实现python多线程的. 相关文章链接:python同步原语--线程 ...
- python——线程相关
使用python的threading中的Thread 下面是两种基本的实现线程的方式: 第一种方式———— #coding=utf-8 """ thread的第一种声明及 ...
- python线程入门
目录 python线程入门 线程与进程 线程 总结 参考 python线程入门 正常情况下,我们在启动一个程序的时候.这个程序会先启动一个进程,启动之后这个进程会启动起来一个线程.这个线程再去处理事务 ...
- [ python ] 线程的操作
目录 (见右侧目录栏导航) - 1. 前言 - 1.1 进程 - 1.2 有了进程为什么要有线程 - 1.3 线程的出现 - 1.4 进程和线程的关系 - 1.5 线程的 ...
- python多线程理解
在发送网络请求的过程中,单个请求的速度总是有着很大的限制,而任务往往需要以更快的速度去执行,这时多线程就是一个很好地选择.python已经给我们封装好了多线程库thread和threading. th ...
- python线程条件变量Condition(31)
对于线程与线程之间的交互我们在前面的文章已经介绍了 python 互斥锁Lock / python事件Event , 今天继续介绍一种线程交互方式 – 线程条件变量Condition. 一.线程条件变 ...
- python 线程创建和传参(28)
在以前的文章中虽然我们没有介绍过线程这个概念,但是实际上前面所有代码都是线程,只不过是单线程,代码由上而下依次执行或者进入main函数执行,这样的单线程也称为主线程. 有了单线程的话,什么又是多线程? ...
随机推荐
- vue中blob文件下载及其它下载方式
一.Blob对象的了解 1:blob表示一个不可变.原始数据的类文件对象.Blob()构造函数返回一个新的blob对象:blob对象的内容由参数给出的值串联组成: 2:new Blob(array, ...
- python工具---snmp流量监控,自定义粒度,业务突发可视化
现在主流监控软件和云平台提供的流量监控,监控粒度最小只能设置为1分钟,无法准确定位故障,特别是瞬时突发较大的业务 对比python的snmp库还是更喜欢用subprocess调用snmpwalk命令, ...
- 透过实例demo带你认识gRPC
摘要:gRPC是基于定义一个服务,指定一个可以远程调用的带有参数和返回类型的的方法.在服务端,服务实现这个接口并且运行gRPC服务处理客户端调用. 本文分享自华为云社区<gRPC介绍以及spri ...
- 渗透:wesside-ng
WEP自动破解工具wesside-ng wesside-ng是aircrack-ng套件提供的一个概念验证工具.该工具可以自动扫描无线网络,发现WEP加密的AP.然后,尝试关联该AP.关联成功后,它会 ...
- 虚拟环境与django版本与视图层相关知识
目录 虚拟环境 django版本区别 视图函数返回值 JsonResponse对象 form表单上传文件 request方法 FBV与CBV CBV源码剖析 模板语法传值 传值方式 传值范围 虚拟环境 ...
- Yaml中特殊符号"| > |+ |-"的作用
"|",保留每行尾部的换行符\n. ">",删除每行尾部的换行符\n,则看似多行文本,则在程序中会将其视为一行. include_newlines: | ...
- 前端获取cookie,并解析cookie成JSON对象
getCookie() { let strcookie = document.cookie; //获取cookie字符串 let arrcookie = strcookie.split("; ...
- C++调用C#的动态库dll
以往我们经常是需要使用C#来调用C++的dll,这通过PInvoke就能实现.现在在实际的项目过程中,有时会遇到在C++的项目中调用某个C#的dll来完成特定的某个功能,我们都知道,Native C+ ...
- 使用 KubeKey 搭建 Kubernetes/KubeSphere 环境的"心路(累)历程"
目录 今天要干嘛? 在哪里干? 从哪里开始干? 快速开干! 解决依赖问题再继续干! 如何干翻重来? 连着 KubeSphere 一起干! 干不过,输了. 重整旗鼓,继续干! 再次重整旗鼓,继续干! 一 ...
- C语言学习之我见-strcmp()字符串比较函数
strcmp()函数,用于两个字符串的比较. (1)函数原型 int strcmp(const char *_Str1,const char *_Str2); (2)头文件 string.h (3)功 ...