Hadoop——API操作
代码示例:
package com.atguigu.hdfs; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.junit.After;
import org.junit.Before;
import org.junit.Test; import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.Arrays; public class HdfsClient {
private FileSystem fs;
@Before
public void init() throws URISyntaxException, IOException, InterruptedException {
URI uri=new URI("hdfs://master:9000");
Configuration configuration=new Configuration();
String user="root";
fs=FileSystem.get(uri,configuration,user);
}
@After
public void close() throws IOException {
// 3 关闭资源
fs.close();
}
//创建目录
@Test
public void testmkdir() throws IOException, URISyntaxException, InterruptedException { fs.mkdirs(new Path("/homework"));
}
//上传
@Test
public void testPut() throws IOException {
//
fs.copyFromLocalFile(true,true,new Path("D:\\sunwukong.txt"),new Path("/xiyou/huaguoshan"));
}
@Test
public void testListFiles() throws IOException, InterruptedException,
URISyntaxException {
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://master:9000"),
configuration, "root");
// 2 获取文件详情
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"),
true);
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println("========" + fileStatus.getPath() + "=========");
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getOwner());
System.out.println(fileStatus.getGroup());
System.out.println(fileStatus.getLen());
System.out.println(fileStatus.getModificationTime());
System.out.println(fileStatus.getReplication());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPath().getName());
// 获取块信息
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println(Arrays.toString(blockLocations));
}
// 3 关闭资源
fs.close();
} }
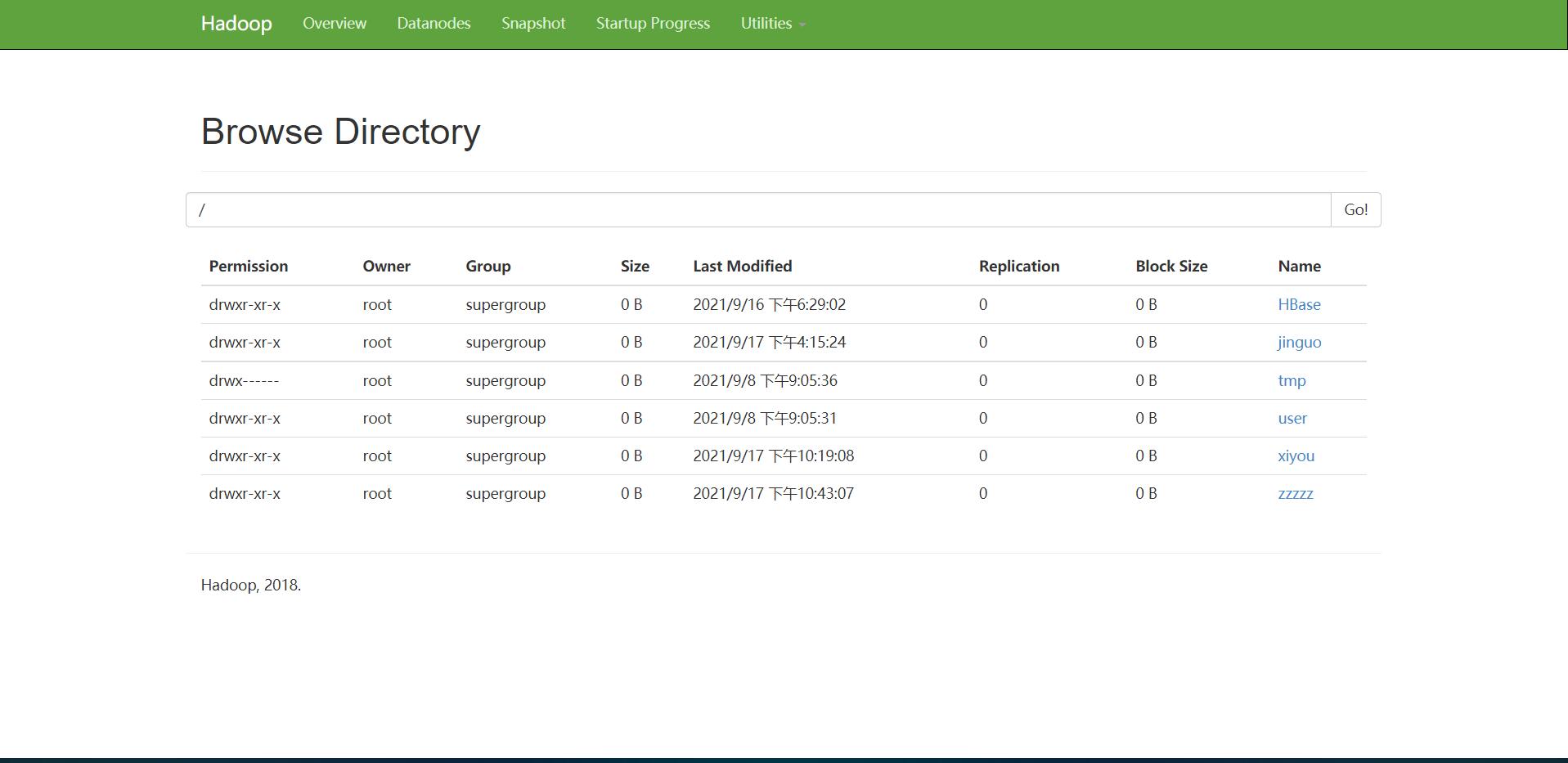
运行截图:
Hadoop——API操作的更多相关文章
- Hadoop学习记录(3)|HDFS API 操作|RPC调用
HDFS的API操作 URL方式访问 package hdfs; import java.io.IOException; import java.io.InputStream; import java ...
- Hadoop之HDFS(三)HDFS的JAVA API操作
HDFS的JAVA API操作 HDFS 在生产应用中主要是客户端的开发,其核心步骤是从 HDFS 提供的 api中构造一个 HDFS 的访问客户端对象,然后通过该客户端对象操作(增删改查)HDFS ...
- 【Hadoop离线基础总结】HDFS的API操作
HDFS的API操作 创建maven工程并导入jar包 注意 由于cdh版本的所有的软件涉及版权的问题,所以并没有将所有的jar包托管到maven仓库当中去,而是托管在了CDH自己的服务器上面,所以我 ...
- Python API 操作Hadoop hdfs详解
1:安装 由于是windows环境(linux其实也一样),只要有pip或者setup_install安装起来都是很方便的 >pip install hdfs 2:Client——创建集群连接 ...
- hive-通过Java API操作
通过Java API操作hive,算是测试hive第三种对外接口 测试hive 服务启动 package org.admln.hive; import java.sql.SQLException; i ...
- hadoop2-HBase的Java API操作
Hbase提供了丰富的Java API,以及线程池操作,下面我用线程池来展示一下使用Java API操作Hbase. 项目结构如下: 我使用的Hbase的版本是 hbase-0.98.9-hadoop ...
- 使用Java API操作HDFS文件系统
使用Junit封装HFDS import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org ...
- Hbase Shell命令详解+API操作
HBase Shell 操作 3.1 基本操作1.进入 HBase 客户端命令行,在hbase-2.1.3目录下 bin/hbase shell 2.查看帮助命令 hbase(main):001:0& ...
- 使用Hadoop API 压缩HDFS文件
下篇解压缩:使用Hadoop API 解压缩 HDFS文件 起因: 集群磁盘剩余空间不足. 删除了存储在HDFS上的,一定时间之前的中间结果,发现并不能释放太多空间,查看计算业务,发现,每天的日志存在 ...
随机推荐
- UP9616移动电源快充案例
第一版的UP9616快充(地址在此 ),从选料到线路板的布局走线都还算不错,实现了当初定下的设计目标,但也有一点小小的遗憾,就是在输出滤波电容这里有点随便了,为了弥补这个遗憾,秉着工程师的" ...
- 关于Css的垂直居中的一些方法
前两种方法称为大致居中,一般误差随高度的减小而减小,不过一般来说不怎么看得出来,除非你用javascript调用offsetTop来查看.不然没有强迫症的比较难看出来.但是兼容性很好,尤其是table ...
- CSS的inline、block与inline-block
基本知识点 行内元素一般是内容的容器,而块级元素一般是其他容器的容器,行内元素适合显示具体内容,而块级元素适合做布局. 块级元素(block):独占一行,对宽高的属性值生效:如果不给宽度,块级元素就默 ...
- 【Android开发】安卓炫酷效果集合
1. android-ripple-background 能产生波浪效果的背景图片控件,可以自定义颜色,波浪扩展的速度,波浪的圈数. github地址 2. android-shapeLoadingV ...
- 什么是机器学习的分类算法?【K-近邻算法(KNN)、交叉验证、朴素贝叶斯算法、决策树、随机森林】
1.K-近邻算法(KNN) 1.1 定义 (KNN,K-NearestNeighbor) 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类 ...
- IDEA 2022.2.1 Beta 2发布:新增支持Java 18、增强JUnit 5的支持
近日,IDEA 2022.1的Beta 2版本发布了!下面我们一起来看看对于我们Java开发者来说,有哪些重要的更新内容. Java增强 随着Java 18的正式发布,IDEA也在该版本中迅速跟进.目 ...
- 新手入门C语言第八章:C循环
一.C 循环 有的时候,我们可能需要多次执行同一块代码.一般情况下,语句是按顺序执行的:函数中的第一个语句先执行,接着是第二个语句,依此类推.编程语言提供了更为复杂执行路径的多种控制结构.循环语句允许 ...
- css 进阶实战项目
1. html 结构 <!DOCTYPE html> <html lang="en"> <head> <meta charset=&quo ...
- 联邦平均算法(Federated Averaging Algorithm,FedAvg)
设一共有\(K\)个客户机, 中心服务器初始化模型参数,执行若干轮(round),每轮选取至少1个至多\(K\)个客户机参与训练,接下来每个被选中的客户机同时在自己的本地根据服务器下发的本轮(\(t\ ...
- XCTF练习题---MISC---simple_transfer
XCTF练习题---MISC---simple_transfer flag:HITB{b3d0e380e9c39352c667307d010775ca} 解题步骤: 1.观察题目,下载附件 2.经过观 ...