读论文SRCNN:Learning a Deep Convolutional Network for Image Super-Resolution
Learning a Deep Convolutional Network for Image Super-Resolution
SRCNN是深度学习应用于SR领域的开山之作。
Pytorch代码 与论文的细节设置有些不同。
实验细节总结:
1 数据集
set5:5张图片
set14:14张图片
用到的数据集为set5、set14、ImageNet。
其中,为和之前其他的方法保持相同的条件,先用91张图片作为训练集,set5、set14作为测试集,其中set5的5张图片用作x2x3x4的测试集,set14的14张图片用作x3的测试集。得出的模型效果比之前其他的方法更好。随后用ImageNet的大数据量训练(网络的参数发生了一些改变),得出训练数据集的增加,会给结果带来更好效果,同时训练时间和推理时间也会增加。
在文章的4 Experiments中,描述如下,
Datasets. For a fair comparison with traditional example-based methods, we use the same training set, test sets, and protocols as in [20].
Specifically, the training set consists of 91 images.
The Set5 [2] (5 images) is used to evaluate the performance of upscaling factors 2, 3, and 4, and Set14 [28] (14 images) is used to evaluate the upscaling factor 3.
In addition to the 91-image training set, we also investigate a larger training set in Section 5.2.
具体来说,训练集包含91张图片。set5的五张图片用来估计模型在上采样x2,x3,x4时的表现,set14用来估计模型在上采样x3的表现。除了91张图片之外,在5.2节也用了大数据集训练。
值得注意的是,文章中提出了sub-images(即子图)的概念。
在训练阶段,地面真实图像{Xi}是从训练图像中随机裁剪出来的32张32×32像素的子图像。我们所说的“子图像”是指这些样本被视为小的“图像”而不是“补丁”,在这个意义上,“补丁”是重叠的,需要一些平均作为后处理,但“子图像”不需要。为了合成低分辨率样本{Yi},我们用适当的高斯核模糊子图像,用放大因子进行子采样,并通过双边插值对相同的因子进行放大。这91张训练图像提供了大约24,800张子图像。子图像从原始图像中提取,步幅为14。我们尝试了较小的进步,但没有观察到显著的性能改善。从我们的观察来看,训练集足以训练所提出的深度网络。
2 实验流程
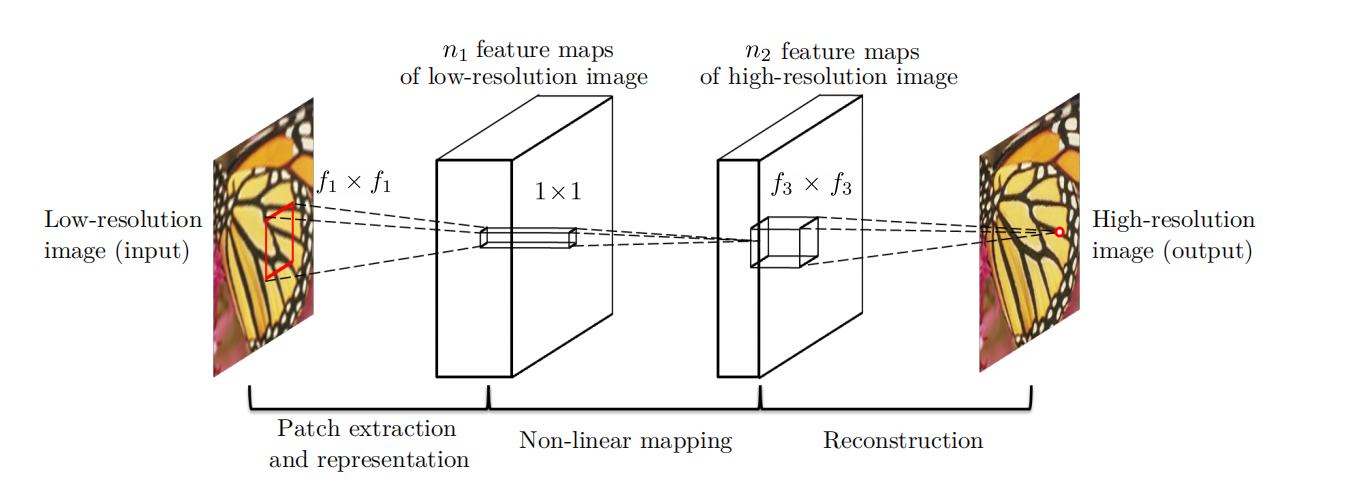
输入为32x32像素的子图sub-image,经过三层卷积,得到输出。
提前对输入input进行了双三次插值,所以网络的输入和输出是相同大小的。
第一层卷积的参数为:(kernel size)9x9,(input channel)1,(outputchannel)64
第二层卷积的参数为:1x1,64,32
第三层卷积的参数为:5x5,32,1
至于为什么第一层网络中输入通道为1,文章中这样说是为了和之前的方法进行对比,所以采用相同的通道数。
在[20]之后,我们在实验中只考虑亮度通道(在YCrCb颜色空间中),所以在第一/最后一层考虑c=1。
这两个色度通道仅为显示的目的而进行双边上采样,而不是用于训练/测试。
请注意,我们的方法可以通过设置c=3来扩展到直接的彩色图像训练。
我们使用c=1主要是为了与以前的方法进行公平的比较,因为大多数方法只涉及亮度通道。
步长s=1;训练时为避免边缘效应,无padding;测试时为保持和input image相同的大小,padding填充0。
所以,训练时的网络输出为20x20像素的子图。因为损失函数为MSE损失函数,所以调整损失函数为仅通过Xi(input image)的中心20×20与网络输出之间的差异来评估。
为了解决边界效应,在每个卷积层中,每个像素的输出(在ReLU之前)被有效输入像素的数量归一化,这可以预先计算。(ReLu激活之前归一化输入像素)
卷积核(kernel or filter)初始化为从一个均值为0,标准差为0.001(偏差为0)的高斯分布中随机抽取来初始化。
前两层的学习率为 \(10^{-4}\) ,最后一层的学习率为 \(10^{-5}\).作者通过经验发现,在最后一层的一个较小的学习速率对网络的收敛是很重要的(类似于去噪的情况[12])。
优化方式为普通的梯度下降SGD。
文章中没写epoch,batch-size。只写了训练 \(8 \times 10^8\) 个反向传播需要三天时间。
网络结构:
3 损失函数:MSE损失函数
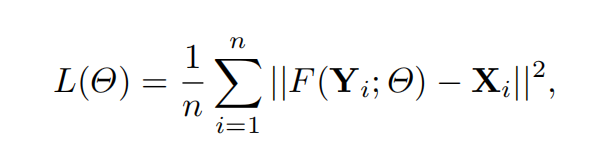
其中,n为像素点的个数,F为网络的输出,X为网络的输入,i表示第i个图像。其中,训练集和测试集的计算方式有区别。
4 实验结果
表一 在set5数据集上的PSNR(dB)和测试时间(sec,秒)
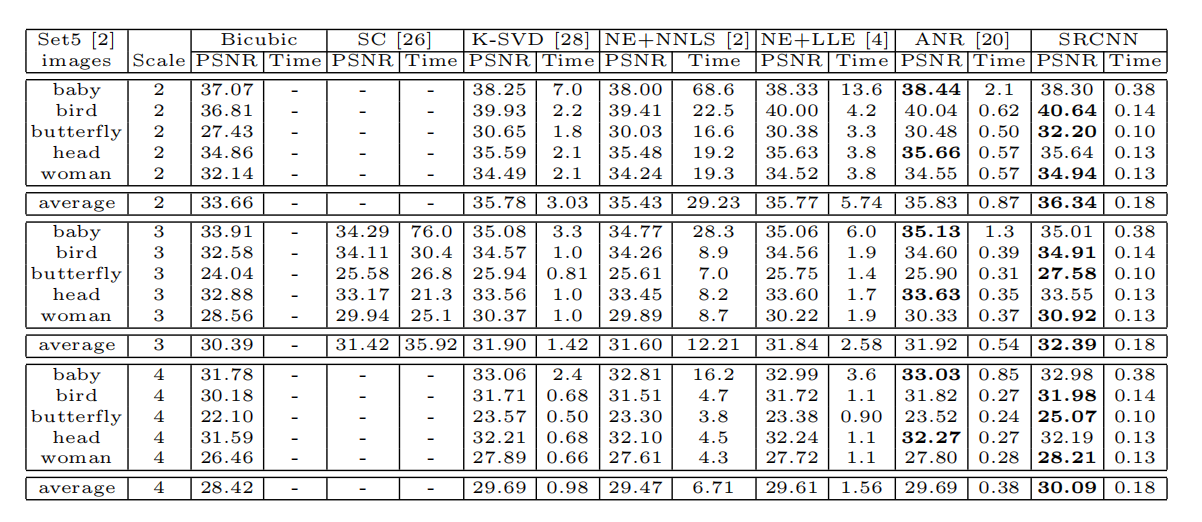
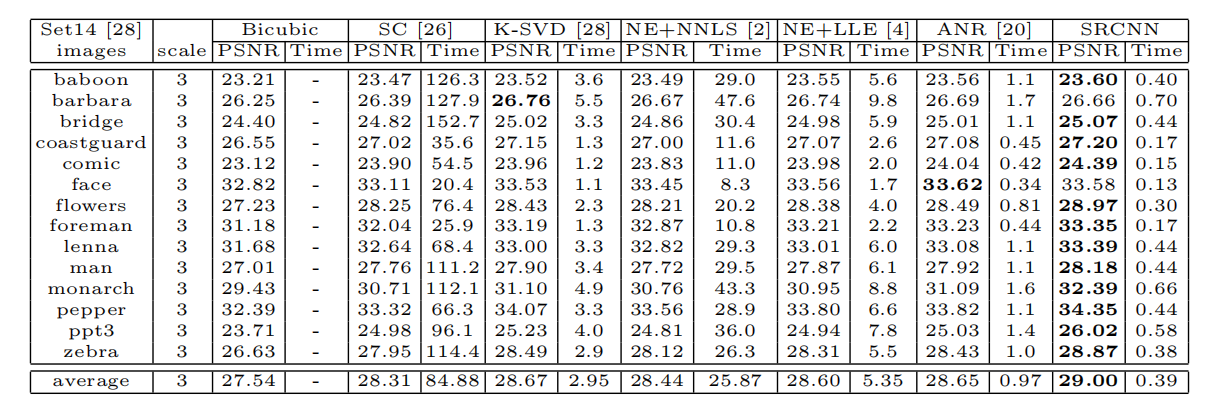
表2 set14数据集上的PSNR(dB)和测试时间(sec)
5 实验配置
GTX 770 GPU
c++
IntelCPU3.10 GHz
16GB内存
读论文SRCNN:Learning a Deep Convolutional Network for Image Super-Resolution的更多相关文章
- 论文学习 :Learning a Deep Convolutional Network for Image Super-Resolution 2014
(Learning a Deep Convolutional Network for Image Super-Resolution, ECCV2014) 摘要:我们提出了一种单图像超分辨率的深度学习方 ...
- 论文笔记之:UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS ICLR 2 ...
- ASPLOS'17论文导读——SC-DCNN: Highly-Scalable Deep Convolutional Neural Network using Stochastic Computing
今年去参加了ASPLOS 2017大会,这个会议总体来说我感觉偏系统和偏软一点,涉及硬件的相对少一些,对我这个喜欢算法以及硬件架构的菜鸟来说并不算非常契合.中间记录了几篇相对比较有趣的paper,今天 ...
- ASRWGAN: Wasserstein Generative Adversarial Network for Audio Super Resolution
ASEGAN:WGAN音频超分辨率 这篇文章并不具有权威性,因为没有发表,说不定是外国的某个大学的毕业设计,或者课程结束后的作业.或者实验报告. CS230: Deep Learning, Sprin ...
- Deep Learning 27:Batch normalization理解——读论文“Batch normalization: Accelerating deep network training by reducing internal covariate shift ”——ICML 2015
这篇经典论文,甚至可以说是2015年最牛的一篇论文,早就有很多人解读,不需要自己着摸,但是看了论文原文Batch normalization: Accelerating deep network tr ...
- 论文笔记(6):Weakly-and Semi-Supervised Learning of a Deep Convolutional Network for Semantic Image Segmentation
这篇文章的主要贡献点在于: 1.实验证明仅仅利用图像整体的弱标签很难训练出很好的分割模型: 2.可以利用bounding box来进行训练,并且得到了较好的结果,这样可以代替用pixel-level训 ...
- DCGAN: "Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Network" Notes
- Alec Radford, ICLR2016 原文:https://arxiv.org/abs/1511.06434 论文翻译:https://www.cnblogs.com/lyrichu/p/ ...
- Discriminative Learning of Deep Convolutional Feature Point Descriptors 论文阅读笔记
介绍 该文提出一种基于深度学习的特征描述方法,并且对尺度变化.图像旋转.透射变换.非刚性变形.光照变化等具有很好的鲁棒性.该算法的整体思想并不复杂,使用孪生网络从图块中提取特征信息(得到一个128维的 ...
- 读论文Machine Learning for Improved Diagnosis and Prognosis in Healthcare
Deep Learning的基本思想 假设我们有一个系统S,它有n层(S1,…Sn),它的输入是I,输出是O,形象地表示为: I =>S1=>S2=>…..=>Sn => ...
- Paper | Compression artifacts reduction by a deep convolutional network
目录 1. 故事 2. 方法 3. 实验 这是继SRCNN(超分辨)之后,作者将CNN的战火又烧到了去压缩失真上.我们看看这篇文章有什么至今仍有启发的故事. 贡献: ARCNN. 讨论了low-lev ...
随机推荐
- MySQL进阶实战3,mysql索引详解,上篇
一.索引 索引是存储引擎用于快速查找记录的一种数据结构.我觉得数据库中最重要的知识点,就是索引. 存储引擎以不同的方式使用B-Tree索引,性能也各有不同,各有优劣.例如MyISAM使用前缀压缩技术使 ...
- python字符串常用方法介绍,基于python3.10
python字符串常用方法-目录: 1.strip().lstrip().rstrip()2.removeprefix().removesuffix()3.replace()4.split().rsp ...
- 【Oracle】Oracle读取RAW二进制类型并实现与十六进制的相互转换
1.十六进制转二进制 select HEXTORAW('7264B1CD0582734D8E27E0FBDA15B2A5') from dual; 2.二进制转十六进制 select AUUID_0, ...
- 01.Typora基本使用
1.标题 方法一: 在文字前面加上"#",将其变成标题. "#"的数量决定字体的大小."#"数量越多字体越小. 如下,其中一级标题是字体最大 ...
- 使用 System.Text.Json 时,如何处理 Dictionary 中 Key 为自定义类型的问题
在使用 System.Text.Json 进行 JSON 序列化和反序列化操作时,我们会遇到一个问题:如何处理字典中的 Key 为自定义类型的问题. 背景说明 例如,我们有如下代码: // 定义一 ...
- Mqttnet内存与性能改进录
1 MQTTnet介绍 MQTTnet是一个高性能的 .NET MQTT库,它提供MQTT客户端和MQTT服务器的功能,支持到最新MQTT5协议版本,支持.Net Framework4.5.2版本或以 ...
- Python启动HTTP服务进行文件传输
有时候局域网共享个东西不方便,尤其在服务器上的时候,总不能先下载下来,再上传上去吧,于是经常在这台机器用python起个http服务,然后去另一台机器直接访问,一来二去,妥试不爽,特进行一下分离 py ...
- 真正“搞”懂HTTP协议07之队头阻塞真的很烦人
这一篇文章,我们核心要聊的事情就是HTTP的对头阻塞问题,因为HTTP的核心改进其实就是在解决HTTP的队头阻塞.所以,我们会讲的理论多一些,而实践其实很少,要学习的头字段也只有一个,我会在最开始就讲 ...
- 深入理解IOC并自己实现IOC容器
title: 深入理解IOC并自己实现IOC容器 categories: 后端 tags: - .NET 背景介绍 平时开发的时候我们经常会写出这种代码: var optionA=new A(...) ...
- YMOI 2019.6.15
题解 YMOI 2019.6.15 前记 NOIP信心个蛋赛,被各路大佬吊打,信心-- 耻辱墙: \(2019.6.15\) \(rank\) \(\color{red}{3}\) T1 简单队列 题 ...