一文详解ATK Loss论文复现与代码实战
摘要:该方法的主要思想是使用数值较大的排在前面的梯度进行反向传播,可以认为是一种在线难例挖掘方法,该方法使模型讲注意力放在较难学习的样本上,以此让模型产生更好的效果。
本文分享自华为云社区《ATK Loss论文复现与代码实战》,作者:李长安。
损失是一种非常通用的聚合损失,其可以和很多现有的定义在单个样本上的损失 结合起来,如logistic损失,hinge损失,平方损失(L2),绝对值损失(L1)等等。通过引入自由度 k,损失可以更好的拟合数据的不同分布。当数据存在多分布或类别分布不均衡的时候,最小化平均损失会牺牲掉小类样本以达到在整体样本集上的损失最小;当数据存在噪音或外点的时候,最大损失对噪音非常的敏感,学习到的分类边界跟Bayes最优边界相差很大;当采取损失最为聚合损失的时候(如k=10),可以更好的保护小类样本,并且其相对于最大损失而言对噪音更加鲁棒。所以我们可以推测:最优的k即不是k = 1(对应最大损失)也不是k = n(对应平均损失),而是在[1, n]之间存在一个比较合理的k的取值区间。
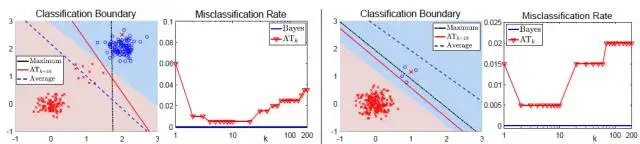
上图结合仿真数据显示了最小化平均损失和最小化最大损失分别得到的分类结果。可以看出,当数据分布不均衡或是某类数据存在典型分布和非典型分布的时候,最小化平均损失会忽略小类分布的数据而得到次优的结果;而最大损失对样本噪音和外点(outliers)非常的敏感,即使数据中仅存在一个外点也可能导致模型学到非常糟糕的分类边界;相比于最大损失损失,第k大损失对噪音更加鲁棒,但其在k > 1时非凸非连续,优化非常困难。
由于真实数据集非常复杂,可能存在多分布性、不平衡性以及噪音等等,为了更好的拟合数据的不同分布,我们提出了平均Top-K损失作为一种新的聚合损失。

本项目最初的思路来自于八月份参加比赛的时候。由于数据集复杂,所以就在想一些难例挖掘的方法。看看这个方法能否带来一个更好的模型效果。该方法的主要思想是使用数值较大的排在前面的梯度进行反向传播,可以认为是一种在线难例挖掘方法,该方法使模型讲注意力放在较难学习的样本上,以此让模型产生更好的效果。代码如下所示。
class topk_crossEntrophy(nn.Layer):
def __init__(self, top_k=0.6):
super(topk_crossEntrophy, self).__init__()
self.loss = nn.NLLLoss()
self.top_k = top_k
self.softmax = nn.LogSoftmax()
return
def forward(self, inputs, target):
softmax_result = self.softmax(inputs)
loss1 = paddle.zeros([1])
for idx, row in enumerate(softmax_result):
gt = target[idx]
pred = paddle.unsqueeze(row, 0)
cost = self.loss(pred, gt)
loss1 = paddle.concat((loss1, cost), 0)
loss1 = loss1[1:]
if self.top_k == 1:
valid_loss1 = loss1
index = paddle.topk(loss1, int(self.top_k * len(loss1)))
valid_loss1 = loss1[index[1]]
return paddle.mean(valid_loss1)
topk_loss的主要思想
- topk_loss的核心思想,即通过控制损失函数的梯度反传,使模型对Loss值较大的样本更加关注。该函数即为CrossEntropyLoss函数的具体实现,只不过是在计算nllloss的时候取了前70%的梯度
- 数学逻辑:挖掘反向传播前 70% 梯度。
代码实战
此部分使用比赛中的数据集,并带领大家使用Top-k Loss完成模型训练。在本例中使用前70%的Loss。
!cd 'data/data107306' && unzip -q img.zip
# 导入所需要的库
from sklearn.utils import shuffle
import os
import pandas as pd
import numpy as np
from PIL import Image
import paddle
import paddle.nn as nn
from paddle.io import Dataset
import paddle.vision.transforms as T
import paddle.nn.functional as F
from paddle.metric import Accuracy
import warnings
warnings.filterwarnings("ignore")
# 读取数据
train_images = pd.read_csv('data/data107306/img/df_all.csv')
train_images = shuffle(train_images)
# 划分训练集和校验集
all_size = len(train_images)
train_size = int(all_size * 0.9)
train_image_list = train_images[:train_size]
val_image_list = train_images[train_size:]
train_image_path_list = train_image_list['image'].values
label_list = train_image_list['label'].values
train_label_list = paddle.to_tensor(label_list, dtype='int64')
val_image_path_list = val_image_list['image'].values
val_label_list1 = val_image_list['label'].values
val_label_list = paddle.to_tensor(val_label_list1, dtype='int64')
# 定义数据预处理
data_transforms = T.Compose([
T.Resize(size=(448, 448)),
T.Transpose(), # HWC -> CHW
T.Normalize(
mean = [0, 0, 0],
std = [255, 255, 255],
to_rgb=True)
])
# 构建Dataset
class MyDataset(paddle.io.Dataset):
"""
步骤一:继承paddle.io.Dataset类
"""
def __init__(self, train_img_list, val_img_list,train_label_list,val_label_list, mode='train'):
"""
步骤二:实现构造函数,定义数据读取方式,划分训练和测试数据集
"""
super(MyDataset, self).__init__()
self.img = []
self.label = []
self.valimg = []
self.vallabel = []
# 借助pandas读csv的库
self.train_images = train_img_list
self.test_images = val_img_list
self.train_label = train_label_list
self.test_label = val_label_list
# self.mode = mode
if mode == 'train':
# 读train_images的数据
for img,la in zip(self.train_images, self.train_label):
self.img.append('data/data107306/img/imgV/'+img)
self.label.append(la)
else :
# 读test_images的数据
for img,la in zip(self.test_images, self.test_label):
self.img.append('data/data107306/img/imgV/'+img)
self.label.append(la)
def load_img(self, image_path):
# 实际使用时使用Pillow相关库进行图片读取即可,这里我们对数据先做个模拟
image = Image.open(image_path).convert('RGB')
image = np.array(image).astype('float32')
return image
def __getitem__(self, index):
"""
步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)
"""
# if self.mode == 'train':
image = self.load_img(self.img[index])
label = self.label[index]
return data_transforms(image), label
def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
return len(self.img)
#train_loader
train_dataset = MyDataset(train_img_list=train_image_path_list, val_img_list=val_image_path_list, train_label_list=train_label_list, val_label_list=val_label_list, mode='train')
train_loader = paddle.io.DataLoader(train_dataset, places=paddle.CPUPlace(), batch_size=4, shuffle=True, num_workers=0)
#val_loader
val_dataset = MyDataset(train_img_list=train_image_path_list, val_img_list=val_image_path_list, train_label_list=train_label_list, val_label_list=val_label_list, mode='test')
val_loader = paddle.io.DataLoader(val_dataset, places=paddle.CPUPlace(), batch_size=4, shuffle=True, num_workers=0)
from res2net import Res2Net50_vd_26w_4s
# 模型封装
model_re2 = Res2Net50_vd_26w_4s(class_dim=4)
import paddle.nn.functional as F
import paddle
modelre2_state_dict = paddle.load("Res2Net50_vd_26w_4s_pretrained.pdparams")
model_re2.set_state_dict(modelre2_state_dict, use_structured_name=True)
model_re2.train()
epochs = 2
optim1 = paddle.optimizer.Adam(learning_rate=3e-4, parameters=model_re2.parameters())
class topk_crossEntrophy(nn.Layer):
def __init__(self, top_k=0.7):
super(topk_crossEntrophy, self).__init__()
self.loss = nn.NLLLoss()
self.top_k = top_k
self.softmax = nn.LogSoftmax()
return
def forward(self, inputs, target):
softmax_result = self.softmax(inputs)
loss1 = paddle.zeros([1])
for idx, row in enumerate(softmax_result):
gt = target[idx]
pred = paddle.unsqueeze(row, 0)
cost = self.loss(pred, gt)
loss1 = paddle.concat((loss1, cost), 0)
loss1 = loss1[1:]
if self.top_k == 1:
valid_loss1 = loss1
# print(len(loss1))
index = paddle.topk(loss1, int(self.top_k * len(loss1)))
valid_loss1 = loss1[index[1]]
return paddle.mean(valid_loss1)
topk_loss = topk_crossEntrophy()
from numpy import *
# 用Adam作为优化函数
for epoch in range(epochs):
loss1_train = []
loss2_train = []
loss_train = []
acc1_train = []
acc2_train = []
acc_train = []
for batch_id, data in enumerate(train_loader()):
x_data = data[0]
y_data = data[1]
y_data1 = paddle.topk(y_data, 1)[1]
predicts1 = model_re2(x_data)
loss1 = topk_loss(predicts1, y_data1)
# 计算损失
acc1 = paddle.metric.accuracy(predicts1, y_data)
loss1.backward()
if batch_id % 1 == 0:
print("epoch: {}, batch_id: {}, loss1 is: {}, acc1 is: {}".format(epoch, batch_id, loss1.numpy(), acc1.numpy()))
optim1.step()
optim1.clear_grad()
loss1_eval = []
loss2_eval = []
loss_eval = []
acc1_eval = []
acc2_eval = []
acc_eval = []
for batch_id, data in enumerate(val_loader()):
x_data = data[0]
y_data = data[1]
y_data1 = paddle.topk(y_data, 1)[1]
predicts1 = model_re2(x_data)
loss1 = topk_loss(predicts1, y_data1)
loss1_eval.append(loss1.numpy())
# 计算acc
acc1 = paddle.metric.accuracy(predicts1, y_data)
acc1_eval.append(acc1)
if batch_id % 100 == 0:
print('************Eval Begin!!***************')
print("epoch: {}, batch_id: {}, loss1 is: {}, acc1 is: {}".format(epoch, batch_id, loss1.numpy(), acc1.numpy()))
print('************Eval End!!***************')
总结
- 在该工作中,分析了平均损失和最大损失等聚合损失的优缺点,并提出了平均Top-K损失(损失)作为一种新的聚合损失,其包含了平均损失和最大损失并能够更好的拟合不同的数据分布,特别是在多分布数据和不平衡数据中。损失降低正确分类样本带来的损失,使得模型学习的过程中可以更好的专注于解决复杂样本,并由此提供了一种保护小类数据的机制。损失仍然是原始损失的凸函数,具有很好的可优化性质。我们还分析了损失的理论性质,包括classification calibration等。
- Top-k loss 的参数设置为1时,此损失函数将变cross_entropy损失,对其进行测试,结果与原始cross_entropy()完全一样。但是我在实际的使用中,使用此损失函数却没使模型取得一个更好的结果。需要做进一步的实验。
一文详解ATK Loss论文复现与代码实战的更多相关文章
- 一文详解Hexo+Github小白建站
作者:玩世不恭的Coder时间:2020-03-08说明:本文为原创文章,未经允许不可转载,转载前请联系作者 一文详解Hexo+Github小白建站 前言 GitHub是一个面向开源及私有软件项目的托 ...
- 一文详解 Linux 系统常用监控工一文详解 Linux 系统常用监控工具(top,htop,iotop,iftop)具(top,htop,iotop,iftop)
一文详解 Linux 系统常用监控工具(top,htop,iotop,iftop) 概 述 本文主要记录一下 Linux 系统上一些常用的系统监控工具,非常好用.正所谓磨刀不误砍柴工,花点时间 ...
- 详解OJ(Online Judge)中PHP代码的提交方法及要点【举例:ZOJ 1001 (A + B Problem)】
详解OJ(Online Judge)中PHP代码的提交方法及要点 Introduction of How to submit PHP code to Online Judge Systems Int ...
- 一文详解 OpenGL ES 3.x 渲染管线
OpenGL ES 构建的三维空间,其中的三维实体由许多的三角形拼接构成.如下图左侧所示的三维实体圆锥,其由许多三角形按照一定规律拼接构成.而组成圆锥的每一个三角形,其任意一个顶点由三维空间中 x.y ...
- 一文详解 WebSocket 网络协议
WebSocket 协议运行在TCP协议之上,与Http协议同属于应用层网络数据传输协议.WebSocket相比于Http协议最大的特点是:允许服务端主动向客户端推送数据(从而解决Http 1.1协议 ...
- 1.3w字,一文详解死锁!
死锁(Dead Lock)指的是两个或两个以上的运算单元(进程.线程或协程),都在等待对方停止执行,以取得系统资源,但是没有一方提前退出,就称为死锁. 1.死锁演示 死锁的形成分为两个方面,一个是使用 ...
- 一文详解Redis键过期策略
摘要:Redis采用的过期策略:惰性删除+定期删除. 本文分享自华为云社区<Redis键过期策略详解>,作者:JavaEdge. 1 设置带过期时间的 key # 时间复杂度:O(1),最 ...
- 一文详解 Linux Crontab 调度任务
最近接到这样一个任务: 定期(每天.每月)向"特定服务器"传输"软件服务"的运营数据,因此这里涉及到一个定时任务,计划使用Python语言添加Crontab依赖 ...
- 一文详解如何在基于webpack5的react项目中使用svg
本文主要讨论基于webpack5+TypeScript的React项目(cra.craco底层本质都是使用webpack,所以同理)在2023年的今天是如何在项目中使用svg资源的. 首先,假定您已经 ...
- HBase 协处理器编程详解,第二部分:客户端代码编写
实现 Client 端代码 HBase 提供了客户端 Java 包 org.apache.hadoop.hbase.client.coprocessor.它提供以下三种方法来调用协处理器提供的服务: ...
随机推荐
- Java实现Excel批量导入数据库
场景说明 在实际开发中,经常需要解析Excel数据来插入数据库,而且通常会有一些要求,比如:全部校验成功才入库.校验成功入库,校验失败返回提示(总数.成功数.失败数.失败每行明细.导出失败文件明细-) ...
- Python 缩进语法的起源:上世纪 60-70 年代的大胆创意!
上个月,Python 之父 Guido van Rossum 在推特上转发了一篇文章<The Origins of Python>,引起了我的强烈兴趣. 众所周知,Guido 在 1989 ...
- 微服务系列之服务监控 Prometheus与Grafana
1.为什么需要监控服务 监控服务的所属服务器硬件(如cpu,内存,磁盘I/O等)指标.服务本身的(如gc频率.线程池大小.锁争用情况.请求.响应.自定义业务指标),对于以前的小型单体服务来说,确实 ...
- 前端h5适配刘海屏和滴水屏
前端适配苹果刘海屏,安卓刘海屏水滴瓶 其实w3c早就为我们提供了解决方法(CSS3新特性viewport-fit) 在w3c.org官方给出的关于圆形展示(Round display)的标准中, 提到 ...
- 读python代码-学到的python函数-1
1.with open(data_path,'r') as f: with open()是python用来打开本地文件的,他会在使用完毕后,自动关闭文件,无需手动书写close(). 三种打开模式: ...
- [OpenCV实战]30 使用OpenCV实现图像孔洞填充
在本教程中,我们将学习如何填充二值图像中的孔.考虑下图左侧的图像.假设我们想要找到一个二值掩模,它将硬币与背景分开,如下图右侧图像所示.在本教程中,包含硬币的圆形区域也将被称为前景. 请注意,硬币的边 ...
- ArcGIS工具 - 批量删除空图层
为了减少数据的冗余,我们经常需将数据库中的空图层(没有任何记录的要素类或表)删除,删除数据本来是一个很简单的操作,但如果数据量大,则需通过程序来处理.例如,删除成百上千个标准分幅DLG数据库中等高线数 ...
- Maui 读取外部文件显示到Blazor中
Maui 读取外部文件显示到Blazor中 首先在maui blazor中无法直接读取外部文件显示 ,但是可以通过base64去显示 但是由于base64太长可能影响界面卡顿 这个时候我们可以使用bl ...
- 算法学习笔记(8.1): 网络最大流算法 EK, Dinic, ISAP
网络最大流 目录 网络最大流 EK 增广路算法 Dinic ISAP 作者有话说 前置知识以及更多芝士参考下述链接 网络流合集链接:网络流 最大流,值得是在不超过管道(边)容量的情况下从源点到汇点最多 ...
- 解决使用linux部署nodejs服务测试代码返回中文是乱码
今天写了个简单的node.js文件 代码如下 var http = require('http'); http.createServer(function (request, response) { ...