在 K8s 上运行 GraphScope
本文将详细介绍:1) 如何基于 Kubernetes 集群部署 GraphScope ; 2) 背后的工作细节; 3) 如何在分布式环境中使用自己构建的 GraphScope 开发镜像。
上篇文章介绍了 GraphScope 可以很容易在单机环境下进行部署。然而在真实的工业场景中,需要处理的图数据规模十分巨大,已远远超过了单机的处理能力。因此除单机部署方式外,借助 vineyard提供的分布式内存数据管理能力,GraphScope 也支持在 Kubernetes 集群上运行。
前置准备
在开始之前,请确保当前环境满足下述条件之一:
- Linux 系统:ubuntu18.04+ 或 centos7+;
- macOS (Big Sur) 11.2.1+。
以及具备以下依赖:
- Docker
- kubectl
- 一套可用的 K8s 环境,可以是
- 一个 K8s 集群
- 或者是 kind/minikube 之类的单机模拟集群的工具
由于 minikube 在服务暴露上与 Kubernetes 不兼容,因此本文以 Kind[1] 为例,介绍如何在本地单机构建一个虚拟 Kubernetes 集群并做部署。如果想搭建一个真实的多节点集群,可以参照 K8s 官方支持的文档[2]搭建;如果你不想手动管理一个 Kubernetes 集群,也可以选择一个经过认证的平台来托管部署服务,如 Aliyun ACK[3] 、AWS EKS[4] 等。
如果已经满足依赖并安装完 kind 之后,首先通过以下命令初始化一个本地虚拟集群:
$ kind create cluster
如果你不想手动逐个安装依赖,也可以使用 GraphScope 提供的脚本,来安装需要的依赖并初始化虚拟集群:
$ wget -O - https://raw.githubusercontent.com/alibaba/GraphScope/main/scripts/install_deps.sh | bash -s -- --k8s
脚本的执行过程会安装所需依赖并尝试检测通过 Kind 拉起 Kubernetes 集群。如果你选择不使用 Kind,也可以使用社区支持的其它工具[5]搭建 Kubernetes 群集。
完成本地虚拟化集群的拉起后,我们可以运行如下命令来查看 Kubernetes 配置是正确的:
$ kubectl get nodes NAME STATUS ROLES AGE VERSION
node1 Ready <none> 5d9h v1.22.3-aliyun.1
如果上述命令报错,则说明集群并未准备就绪。请参考 Kubernetes 相关文档[6] 查看问题。
为了完整运行下文中的示例,你还需要在本机上安装 GraphScope Python 客户端。
pip3 install graphscope
通过 Python 进行集群部署
GraphScope 以 docker 镜像的方式发布引擎组件。默认情况下,如果运行 GraphScope 的机器不存在对应镜像,则会拉取当前版本的最新镜像,因此,请确保你的集群可以正常访问公共镜像仓库。
会话(session)[7] 作为 GraphScope 在客户端的入口,它管理着 GraphScope 背后的一组资源,并允许用户操作这组资源上 GraphScope 引擎的各个组件。接下来,我们可以通过会话(session) 在 Kubernetes 集群上创建一个拥有两个 Worker 节点的 GraphScope 实例:
>>> import graphscope
>>> sess = graphscope.session(num_workers=2)
>>> print(sess)
{'status': 'active', 'type': 'k8s', 'engine_hosts': 'gs-engine-jlspyc-6k8j7,gs-engine-jlspyc-mlnvb', 'namespace': 'gs-xxwczb', 'session_id': 'session_narhaktn', 'num_workers': 2}
第一次部署可能会拉取镜像,因此需要等待一段时间。部署成功后,我们可以看到当前sess的状态,以及本次实例所属的命名空间[8]等。
在命令行窗口,我们可以通过 kubectl get 命令查看当前 GraphScope 实例拉起的组件:
# 查看拉起的 Pod
$ kubectl -n gs-xxwczb get pod
NAME READY STATUS RESTARTS AGE
coordinator-jlspyc-6d6fd7f747-9sr7x 1/1 Running 0 8m27s
gs-engine-jlspyc-6k8j7 2/2 Running 0 8m23s
gs-engine-jlspyc-mlnvb 2/2 Running 0 8m23s
gs-etcd-jlspyc-0 1/1 Running 0 8m24s # 查看拉起的 Service
$ kubectl -n gs-xxwczb get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
coordinator-service-jlspyc NodePort 172.16.137.185 <none> 59050:32277/TCP 8m55s
gs-etcd-jlspyc-0 ClusterIP 172.16.208.134 <none> 57534/TCP,58955/TCP 8m51s
gs-etcd-service-jlspyc ClusterIP 172.16.248.69 <none> 58955/TCP 8m52s
Session 启动各组件的流程
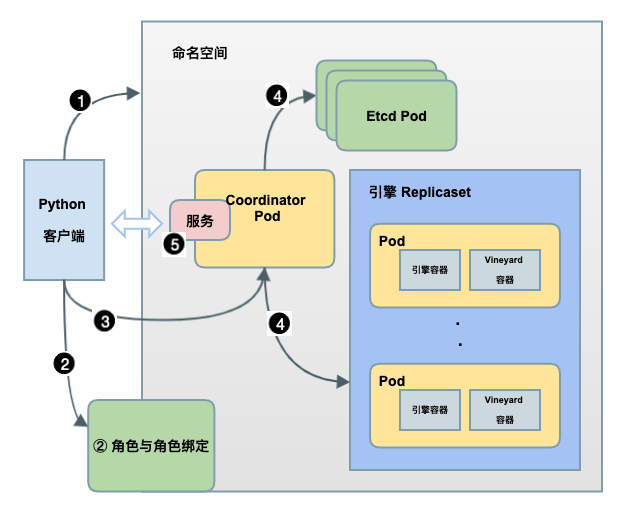
Session 启动流程
如上图所示,在这个 sess = graphscope.session(num_workers=2) 语句背后,GraphScope 拉起各个组件的流程如下:
① 默认情况下,当创建会话(session)时,该方法会为此后使用的每个 Kubernetes 对象,包括 Pod,Role 等创建一个单独的命名空间。当用户关闭会话(session)时,整个命名空间都会被删除。
② 命名空间创建完成后,后续的拉起过程是通过默认的服务账号[9]使用 Kubernetes API 完成的,由于默认的服务账号不具备读取 Pod 的权限,因此我们在客户端创建命名空间后,在对应的命名空间内使用 RBAC API 创建了一个具备操作 Pod、ReplicaSet 等对象的角色[10],此后将其绑定到默认服务账号中。这使得 GraphScope 创建的容器可以访问所属命名空间下的其他 kubernetes 对象。
③ 之后客户端会拉起 Coordinator Pod,作为 GraphScope 后端服务的总入口,通过 GRPC 与客户端通信,并管理着图分析引擎(GAE)、 图查询引擎(GIE),图学习引擎(GLE)的生命周期。
④ Coordinator Pod 拉起后,会根据客户端传入的会话(session)参数,在当前命名空间下拉起服务端组件,包括 1) 一组运行 Etcd 的 Pod,负责图数据元信息的同步;2) 一组运行图计算引擎和 Vineyard 容器的 ReplicaSet 对象。
⑤ 最后,GraphScope Coordinator 使用 Kubernetes Service[11] 对外(客户端)暴露服务,目前支持 NodePort 和 LoadBalancer 两种模式,具体的配置细节可参考下面的参数详情。
Session 的参数
Session 可以接收一系列参数用于定制集群的配置。例如,k8s_gs_image 参数可以定义引擎 Pod 使用的镜像、timeout_seconds 参数定义创建集群的超时时间等,一些常用参数的含义、默认值如下,全部参数细节可参考文档[12]。
| 参数 | 描述 | 默认值 |
|---|---|---|
| addr | 用于连接已有的 GraphScope 集群,通常结合 Helm 部署方式使用 | None |
| k8s_namespace | 指定命名空间,如果存在,则在该命名空间内部署 GraphScope 实例,否则创建一个新的命名空间 | None |
| k8s_gs_image | 引擎 Pod 镜像 | registry.cn-hongkong.aliyuncs.com/graphscope/graphscope:tag |
| k8s_image_pull_policy | 拉取镜像的策略,可选项是 'IfNotPresent' 和 'Always' | IfNotPresent |
| k8s_service_type | 服务暴露类型,可选项是 'NodePort' 和 'LoadBalancer' | NodePort |
| num_workers | 引擎 Pod 数量 | 2 |
| show_log | 客户端是否输出日志信息 | False |
| log_level | 日志信息等级,可选项是 'INFO' 和 'DEBUG' | 'INFO' |
| timeout_seconds | 创建集群的超时时间 | 600 |
在上述参数中,通常需要注意的是 k8s_service_type,你可以参考以下介绍选择适合你的服务类型:
NodePort 类型作为将外部流量导入 Kubernetes 服务最原始的方式,正如其名字所示,它会在对应 Kubernetes 节点上开放一个特定端口 (范围 30000 ~ 32767),任何发送到该端口的流量均会转发给对应的服务 (即 GraphScope 中的 Coordinator 服务),因此如果使用 NodePort 类型,请确保 Python 客户端所在的机器可与 Kubernetes 集群节点进行通信;
LoadBalancer 类型是暴露服务到 Internet 的标准方式,但是目前默认部署的 Kubernetes 集群通常不具备 LoadBalancer 的能力,你需要自己手动部署,可以参考 METALLB[13]。此外,诸如 Aliyun ACK 或 AWS EKS 等经过认证的平台通常直接提供 LoadBalancer 的能力,此时也要注意该方式下的 GraphScope 会为每一个实例请求 LoadBalancer 分配一个单独的 IP 地址,这个过程是收费的。
离线部署
基于 Kubernetes 离线部署 GraphScope 涉及两部分:服务端和客户端部分。
服务端: GraphScope 的服务端部分包含 Etcd 镜像和引擎镜像,其中引擎镜像部分默认会使用 registry.cn-hongkong.aliyuncs.com/graphscope/graphscope 中的镜像,并且每个 GraphScope 发布的版本均会包含一个镜像,例如 v0.11.0 版本对应的镜像是 registry.cn-hongkong.aliyuncs.com/graphscope/graphscope:0.11.0 ,因此若想离线部署 GraphScope,只需要满足相关 Kubernetes 节点存在对应版本的镜像即可,镜像地址如下:
- 引擎镜像:
registry.cn-hongkong.aliyuncs.com/graphscope/graphscope:0.11.0 - Etcd 镜像:
quay.io/coreos/etcd:v3.4.13
具体的,你可以在有网的环境预下载对应镜像,通过 scp 等命令传到集群并载入,命令参考如下:
# 有网环境 下载镜像
docker pull registry.cn-hongkong.aliyuncs.com/graphscope/graphscope:0.11.0 # 通过 docker save 命令将镜像压缩成文件
docker save registry.cn-hongkong.aliyuncs.com/graphscope/graphscope:0.11.0 > gs0.11.0.image # 传输文件到集群
scp gs0.11.0.image <host>:</path/gs0.11.0.image> # 通过 docker load 命令在集群上载入镜像
docker load < gs0.11.0.image
同样 Etcd 镜像也可以用使用该方式进行预导入。
客户端: 你可以直接通过 PYPI[14] 选择你需要 GraphScope 客户端并下载对应环境的 whl 包。下载完成后,通过如下命令安装:
pip3 install ./graphscope_client-0.11.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
构建自定义开发镜像
上面提到,每个 GraphScope 发布的版本均会包含一个镜像,而如果你希望从源码构建一个镜像,可以使用如下命令:
$ git clone https://github.com/alibaba/GraphScope.git && cd GraphScope
$ make graphscope-image
build graphscope/graphscope:<GIT_SHORT_SHA>
此时一个使用当前代码空间 Git Commit 信息作为标签的 Docker 镜像将被构建出来。接下来便可以通过 k8s_gs_image 参数使用该镜像。
>>> import graphscope
>>> sess = graphscope.session(k8s_gs_image='graphscope/graphscope:<GIT_SHORT_SHA>')
结语
作为一款可在云原生环境下高效地处理超大规模数据的图计算引擎,本文重点介绍了如何基于 Kubernetes 环境部署 GraphScope,同时,本文也详细介绍了 GraphScope 在 Kubernetes 上部署的背后细节,以及如何构建并运行自定义镜像。此外 GraphScope 也支持以 Helm[15] 的方式进行部署,届时可以允许客户端连接到一个已经部署好的服务,我们也会在后续的文章中详细介绍这一部分。最后真诚的欢迎大家使用 GraphScope ,并点击阅读原文反馈遇到的任何问题。
参考资料
[1]Kind: https://kind.sigs.k8s.io/docs/
[2]K8s 官方支持的文档: https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/
[3]Aliyun ACK: https://www.aliyun.com/product/kubernetes
[4]AWS EKS: https://aws.amazon.com/eks/?nc1=h_ls
[5]其它工具: https://kubernetes.io/docs/tasks/tools/
[6]Kubernetes 相关文档: https://kubernetes.io/docs/setup/
[7]会话(session): https://graphscope.io/docs/reference/session.html
[8]命名空间: https://kubernetes.io/zh/docs/concepts/overview/working-with-objects/namespaces/
[9]服务账号: https://kubernetes.io/zh/docs/tasks/configure-pod-container/configure-service-account/
[10]角色: https://kubernetes.io/zh/docs/reference/access-authn-authz/rbac/
[11]Kubernetes Service: https://kubernetes.io/zh/docs/concepts/services-networking/service/
[12]文档: https://graphscope.io/docs/reference/session.html
[13]METALLB: https://metallb.universe.tf/
[14]PYPI: https://pypi.org/project/graphscope-client/#files
[15]Helm: https://helm.sh/
在 K8s 上运行 GraphScope的更多相关文章
- gitlab在k8s上运行的一些优化
由 林坤创建,最终由 林坤修改于七月02,2020 gitlab组件图 gitlab在k8s上占用资源 kubectl top pods -n default | grep git* gitlab-g ...
- .net core i上 K8S(二)运行简单.netcore程序
上一章我们搭建了k8s集群,这一章我们开始在k8s集群上运行.netcore程序 1.kubectl run 在我的Docker系列教程里,我曾往docker hub中推送过一个镜像“webdokce ...
- 从认证到调度,K8s 集群上运行的小程序到底经历了什么?
导读:不知道大家有没有意识到一个现实:大部分时候,我们已经不像以前一样,通过命令行,或者可视窗口来使用一个系统了. 前言 现在我们上微博.或者网购,操作的其实不是眼前这台设备,而是一个又一个集群.通常 ...
- Kubernetes学习之路(二十)之K8S组件运行原理详解总结
目录 一.看图说K8S 二.K8S的概念和术语 三.K8S集群组件 1.Master组件 2.Node组件 3.核心附件 四.K8S的网络模型 五.Kubernetes的核心对象详解 1.Pod资源对 ...
- 在k8s上安装Jenkins及常见问题
持续集成和部署是DevOps的重要组成部分,Jenkins是一款非常流行的持续集成和部署工具,最近试验了一下Jenkins,发现它是我一段时间以来用过的工具中最复杂的.一个可能的原因是它需要与各种其它 ...
- 在Kubernetes上运行有状态应用:从StatefulSet到Operator
一开始Kubernetes只是被设计用来运行无状态应用,直到在1.5版本中才添加了StatefulSet控制器用于支持有状态应用,但它直到1.9版本才正式可用.本文将介绍有状态和无状态应用,一个通过K ...
- 是时候考虑让你的Spark跑在K8S上了
[摘要] Spark社区在2.3版本开始,已经可以很好的支持跑着Kubernetes上了.这样对于统一资源池,提高整体资源利用率,降低运维成本(特别是技术栈归一)有着非常大的帮助.这些趋势是一个大数据 ...
- 在K8S上跑一个helloworld
建立docker镜像 为了方便起见,这里直接使用一个js网页作为应用,以此创建镜像 hello world网页 创建server.js,输入以下代码创建helloworld网页: var http = ...
- kubernetes之三 使用kubectl在k8s上部署应用
在上一篇中,我们学习了使用minikube来搭建k8s集群.k8s集群启动后,就可以在上面部署应用了.本篇,我们就来学习如何使用kubectl在k8s上部署应用. 学习之前,可以先从下面这篇博客上了解 ...
随机推荐
- dp:找零问题
C代表币的种类,n代表钱数 #include<iostream> using namespace std; #define C 4 void main( ) { int coin[4]={ ...
- Mysql查询优化器之关于JOIN的优化
连接查询应该是比较常用的查询方式,连接查询大致分为:内连接.外连接(左连接和右连接).自然连接 下图展示了 LEFT JOIN.RIGHT JOIN.INNER JOIN.OUTER JOIN 相关的 ...
- 什么是tar 命令?
用来压缩和解压文件.tar 本身不具有压缩功能,只具有打包功能,有关压缩及解压是调用其它的功能来完成.弄清两个概念:打包和压缩.打包是指将一大堆文件或目录变成一个总的文件:压缩则是将一个大的文件通过一 ...
- vue开发chrome扩展,数据通过storage对象获取
开发chrome插件时遇到一个问题,那就是单文件组件的data数据需要从chrome提供的storage对象中获取,但是 chrome.storage.sync.get 方法是异步获取数据的,需要通过 ...
- ThreadLocal是什么?使用场景有哪些?
什么是ThreadLocal? ThreadLocal为每个使用该变量的线程提供独立的变量副本,所以每一个线程都可以独立地改变自己的副本,而不会影响其它线程所对应的副本. 测试代码: package ...
- 学习Git(二)
常用命令 git add 添加 git status 查看状态 git status -s 状态概览 git diff 对比 git diff --staged 对比暂存区 git commit 提交 ...
- 使用 Docker, 7 个命令部署一个 Mesos 集群
这个教程将给你展示怎样使用 Docker 容器提供一个单节点的 Mesos 集群(未来的一篇文章将展示怎样很容易的扩展这个到多个节点或者是见底部更新).这意味着你可以使用 7 个命令启动整个集群!不需 ...
- 前端存储 - localStorage
发布自Kindem的博客,欢迎大家转载,但是要注意注明出处 localStorage 介绍 在HTML5中,引入了两个新的前端存储特性: localStorage sessionStorage 这两者 ...
- 快速安装 kafka 集群
前言 最近因为工作原因,需要安装一个 kafka 集群,目前网络上有很多相关的教程,按着步骤来也能完成安装,只是这些教程都显得略微繁琐.因此,我写了这篇文章帮助大家快速完成 kafka 集群安装. ...
- uniapp打包成H5部署到服务器教程
当前端uniapp写的项目开发完成的时候,需要将页面打包出来,生成H5的静态文件,部署在服务器上,通过服务器链接地址,就可以直接在手机上点开访问 了. 在网上看了一圈,好像没有找到十分详细的教程,这里 ...