GIL互斥锁与线程
GIL互斥锁与线程
GIL互斥锁验证是否存在
"""
昨天我们买票的程序发现很多个线程可能会取到同一个值进行剪除,证明了数据是并发的,但是我们为了证明在Cpython中证明是存在GIL那么我们就使用列表将他存起来,证明有GIL是串连而不是并发态
"""
from threading import Thread
count = 100
def task():
global count
count -= 1
t1_list = []
if __name__ == '__main__':
for i in range(100):
t = Thread(target=task)
t.start()
t1_list.append(t)
for t in t1_list:
t.join()
print(t1_list)
print(count) # 0
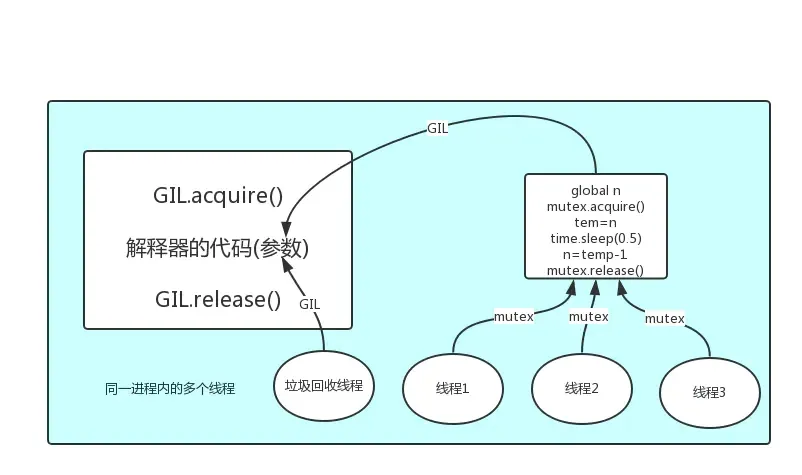
GIL互斥锁的特点
"""
我们在给它加一个IO操作的时候那么他就不会产生GIL,所以它不会影响程序层面的数据也不会保证他的修改是安全的想要保证就需要程序员手动给她加一把锁
"""
from threading import Thread
import time
count = 100
def task():
global count
num = count
time.sleep(0.1)
count = num - 1
t1_list = []
if __name__ == '__main__':
for i in range(100):
t = Thread(target=task)
t.start()
t1_list.append(t)
for t in t1_list:
t.join()
print(t1_list)
print(count) # 99
"""
自己给自己加锁来完成统计
"""
from threading import Thread,Lock
import time
count = 100
mutex = Lock()
def task():
mutex.acquire()
global count
num = count
time.sleep(0.1)
count = num - 1
mutex.release()
t1_list = []
if __name__ == '__main__':
for i in range(100):
t = Thread(target=task)
t.start()
t1_list.append(t)
for t in t1_list:
t.join()
print(t1_list)
print(count) # 0
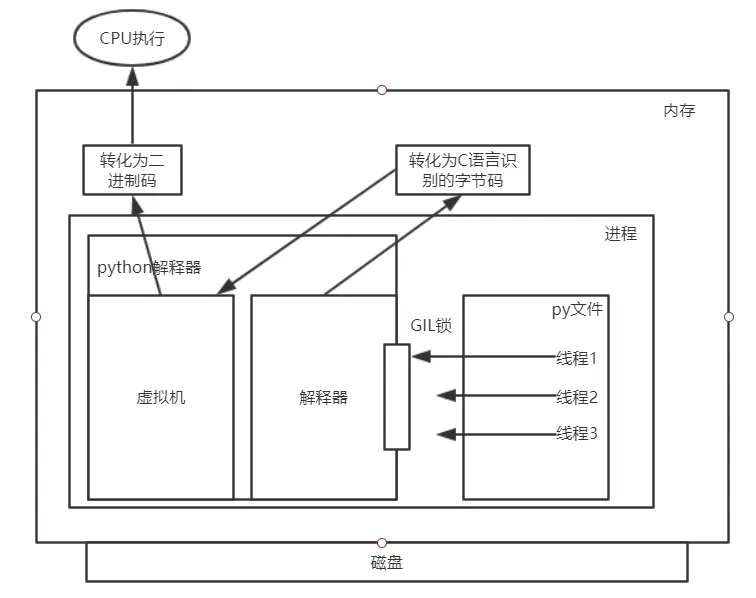
验证python多线程的作用
多种验证方法
- 条件1 单个cpu
- IO密集型操作
- 计算密集操作
- 条件2 多个cpu
- IO密集型操作
- 计算密集操作
- 条件1 单个cpu
单CPU操作
1.io密集型的多进程
需要在内存中多次申请额外的内存空间,需要消耗更多的时间和资源
2.io密集型的多线程
只需要在进程中申请自己所需要的代码即可,只需要通过多道的技术那么就可以实现多线程操作,消耗的资源和时间较少
3.计算密集型的多进程
同样需要在内存中申请额外的内存空间,然后消耗更多的时间和资源(总计算耗时和申请内存空间的时间,拷贝代码的时间再加上各个进程之间切换的时间)
4.计算密集型的多线程
只需要在进程中申请自己所需要的代码即可,并且通过多道技术直接执行(总计算消耗的时间和切换到各线程的时间)
5.总结
所以说在单cup中python的多线程还是非常有用的,即节省内存空间又速度较快
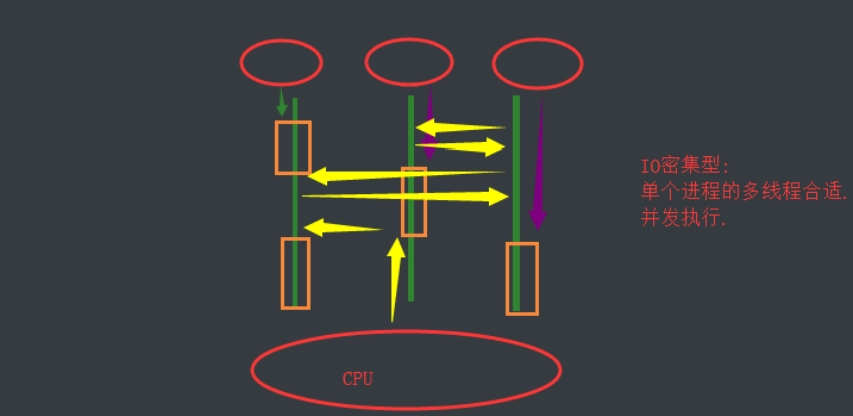
多CPU操作
1.io密集型的多进程
总耗时(单个进程的耗时+IO操作的耗时+申请内存空间的耗时+拷贝代码的耗时)
2.io密集型的多线程
总耗时(单个线程的耗时+IO操作的耗时)
3.计算密集型的多进程
总耗时(单个进程的耗时)
4.计算密集型的多线程
总耗时(多个进程的耗时总和,但是由于内部有优化代码,所以实际上没有那么长的时间进行计算)
5.总结
在多CUP进行密集型计算时由于多进程可以有多个核进行计算所以计算时间会非常短所以在多CPU多计算模型的情况下多进程占据主要又是,也可以称之为完胜,而多线程因为没有办法享用多cpu的好处所以只能一个CPU慢慢计算。

- 多CPU代码展示
1.小知识使用代码查看自己电脑是几核处理
import os
print(os.cpu_count()) # 12
2.展示多计算状态的运行
from threading import Thread
from multiprocessing import Process
import os
import time
def work():
res = 1
for i in range(1,100000):
res *= i
if __name__ == '__main__':
start_time = time.time()
p_list = []
for i in range(12):
p = Process(target=work)
p.start()
p_list.append(p)
for p in p_list:
p.join()
print('总耗时:%s'%(time.time() - start_time)) # 总耗时:5.136746883392334
if __name__ == '__main__':
start_time = time.time()
t_list = []
for i in range(12):
t = Thread(target=work)
t.start()
t_list.append(t)
for t in t_list:
t.join()
print('总耗时:%s' % (time.time() - start_time)) # 总耗时:27.33429765701294
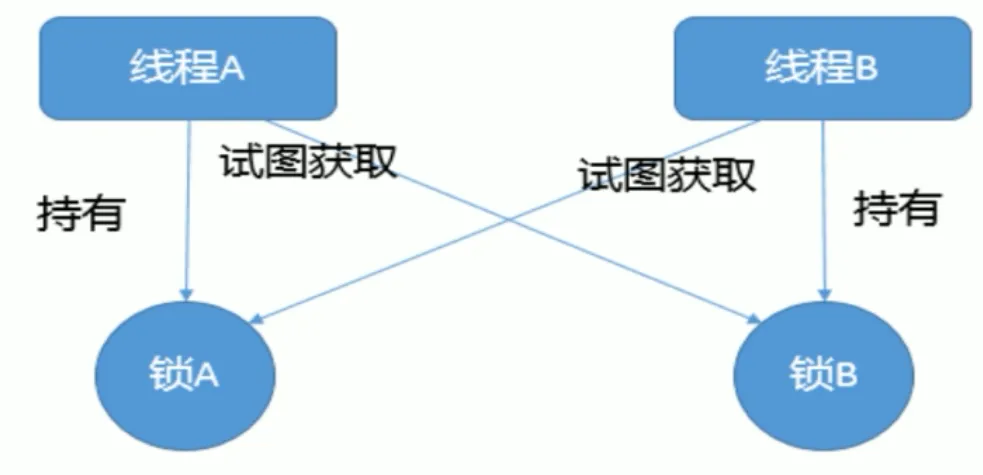
死锁现象
"""
死锁的情况是因为,想要获取我们的想要获取的对象在对方手中而对象想要获取的锁在我们的手中那么就会出现死锁的情况,两方都想要对方的锁,但是自身都有锁
"""
from threading import Thread,Lock
import time
mutexA = Lock()
mutexB = Lock()
class MyThread(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
mutexA.acquire()
print(f'子进程{self.name}获取A锁')
time.sleep(3)
mutexB.acquire()
print(f'子进程{self.name}获取B锁')
mutexB.release()
print(f'子进程{self.name}获取B锁')
mutexA.release()
print(f'子进程{self.name}获取A锁')
def func2(self):
mutexB.acquire()
print(f'子进程{self.name}获取B锁')
time.sleep(3)
mutexA.acquire()
print(f'子进程{self.name}获取A锁')
mutexA.release()
print(f'子进程{self.name}获取A锁')
mutexB.release()
print(f'子进程{self.name}获取B锁')
for i in range(10):
t = Thread()
t.start()
信号量
- 信号量其实本质上也是互斥锁,只不过他这个是多把锁我们可以定义他这个锁的个数,控制线程的最大运行量
- 信号量在不同的变成语言体系中代表的意思可能不太一样,在我们python的并发编程中代表的是多把互斥锁的意思,而在djangomouge中,他则是代表的是某个条件出发的中间件所以不能一概而论,听到信号量就下定论
- 信号量演示
from threading import Thread,Semaphore
import time
import random
SP = Semaphore(3) # 设置信号量为3也就是三把锁
class MyThread(Thread):
def run(self):
SP.acquire()
print(self.name)
time.sleep(random.randint(1,3))
SP.release()
for i in range(20):
t = MyThread()
t.start()
event事件
- 子进程之间可以互相彼此等彼此使用event就可以让一个进程等另一个进程发号师令然后开始运行
- 展示
from threading import Thread,Event
import time
import random
event = Event()
def light():
print('比赛准备开始,本场次有黑哨请所有人启动赛车听到自己的指令出发')
time.sleep(random.randint(1,5))
print('预备,鸣发动机,let GO!GO!GO!')
event.set() # 发送指令
def car(name):
print(f'{name}正在启动赛车')
event.wait() # 等待指令
print(f'{name}发动机轰鸣后出发了')
t = Thread(target=light)
t.start()
l1 = ['Joseph','Alice','Trump','kdi','jason']
for i in l1:
t = Thread(target=car,args=(f'选手{i}',))
t.start()

进程池与线程池和概念
- 在我们的进程和线程中既然我门做服务的时候可以产生很多的进程和线程同时运行的结果,那么我们可以无限制的开启进程和线程可以嘛
- 哒咩,肯定不行鉴于我们的科技水平和技术发展程度,都没有任何硬件可以支持我们进行无限制开启进程和线程,所以我们就需要在硬件的承受范围内创造一个阀值以防资源消耗过度使之损毁。那么产生了我们的进程池和线程池的作用
- 进程池和线程池都会帮我们在使用之前就创建好空的进程和线程,我们以后用的时候就会自动分配给你,不需要重新创建。
进程池与线程池的实际操作
"""
进程池和线程池本质上就是帮它定了一个阀值,让他只能在这个阀值内运行多了那么对不起,你等着吧
"""
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
from threading import current_thread
import os
import time
pool1 = ProcessPoolExecutor(3)
pool2 = ThreadPoolExecutor(3)
def task(n):
print(current_thread().name)
print(os.getpid())
print(os.getppid())
print(n)
time.sleep(1)
return '会返回什么呢'
def func(*args,**kwargs):
print('func',args,kwargs)
print(args[0].result())
if __name__ == '__main__':
for i in range(5):
res = pool1.submit(task,123)
print(res.result())
pool1.submit(task,123).add_done_callback(func)
if __name__ == '__main__':
for i in range(5):
res = pool2.submit(task,123)
print(res.result())
pool2.submit(task,123).add_done_callback(func)
pool2.submit(task,123).add_done_callback(func)
协程简介
- 进程:资源单位,需要从内存中开辟空间
- 线程:执行单位,只需要在进程中执行
- 协程:单线程下实现并发(携程:一款旅行软件,住酒店看携程)
- 协程其实就是在单线程下我们的线程进入IO状态的情况下欺骗CPU让它觉得没有遇到io操作继续运行代码,其实io被我们的代码检测出来一旦有的话就立即让cpu执行别的东西实现无缝连接,这个东西是程序员自己搞出来的,名字也是它起的(协调程序运行,黑心老板压榨cpu剩余劳动力)
from gevent import monkey;monkey.patch_all() # 就是这样写的,我也不知道为什么(猴子补丁)
from gevent import spawn
import time
def func1():
print('func1 正在执行')
time.sleep(3)
print('func1 执行完毕')
def func2():
print('func2 正在执行')
time.sleep(6)
print('func2 执行完毕')
if __name__ == '__main__':
start_time = time.time()
# func1()
# func2() # 9.022636413574219
s1 = spawn(func1) # 一旦遇到io操作那么就立即跳到别的地方执行,如果都在io那么久反复横跳
s2 = spawn(func2) # # 6.01244044303894
s1.join()
s2.join()
print(time.time() - start_time)

协程的实际作用简单实现单线程协程工作
1.服务端
import socket
from gevent import monkey;monkey.patch_all()
from gevent import spawn
def communication(sock):
while True:
data = sock.recv(1024)
print(data.decode('utf-8'))
sock.send(data.upper())
def get_server():
server = socket.socket()
server.bind(('127.0.0.1',8080))
server.listen(5)
while True:
sock,address = server.accept()
spawn(communication,sock)
s1 = spawn(get_server)
s1.join()
2.客户端
import socket
from threading import Thread,current_thread
def get_client():
client = socket.socket()
client.connect(('127.0.0.1',8080))
while True:
client.send(f'good night {current_thread().name}'.encode('utf-8'))
data = client.recv(1024)
print(data.decode('utf-8'))
for i in range(20):
t = Thread(target=get_client)
t.start()
论如何累死一头牛
- 在多进程的情况下使用多线程操作并且在多线程的情况下使用多协程操作,资本家看了都泪目的行为,纯纯的极致压迫和剥削。

GIL互斥锁与线程的更多相关文章
- python并发编程-进程间通信-Queue队列使用-生产者消费者模型-线程理论-创建及对象属性方法-线程互斥锁-守护线程-02
目录 进程补充 进程通信前言 Queue队列的基本使用 通过Queue队列实现进程间通信(IPC机制) 生产者消费者模型 以做包子买包子为例实现当包子卖完了停止消费行为 线程 什么是线程 为什么要有线 ...
- GIL全局解释器锁+GIL全局解释器锁vs互斥锁+定时器+线程queue+进程池与线程池(同步与异步)
以多线程为例写个互斥锁 from threading import Thread ,Lockimport timemutex = Lock() n = 100 def task(): global n ...
- python多线程编程(3): 使用互斥锁同步线程
问题的提出 上一节的例子中,每个线程互相独立,相互之间没有任何关系.现在假设这样一个例子:有一个全局的计数num,每个线程获取这个全局的计数,根据num进行一些处理,然后将num加1.很容易写出这样的 ...
- 8.12 day31 进程间通信 Queue队列使用 生产者消费者模型 线程理论 创建及对象属性方法 线程互斥锁 守护线程
进程补充 进程通信 要想实现进程间通信,可以用管道或者队列 队列比管道更好用(队列自带管道和锁) 管道和队列的共同特点:数据只有一份,取完就没了 无法重复获取用一份数据 队列特点:先进先出 堆栈特点: ...
- python中上双互斥锁的线程执行流程
import threading def sing(): print('进入sing -----------------') for i in range(3): print('进入sing循环 -- ...
- 并发编程 - 线程 - 1.互斥锁/2.GIL解释器锁/3.死锁与递归锁/4.信号量/5.Event事件/6.定时器
1.互斥锁: 原理:将并行变成串行 精髓:局部串行,只针对共享数据修改 保护不同的数据就应该用不用的锁 from threading import Thread, Lock import time n ...
- 【python】-- GIL锁、线程锁(互斥锁)、递归锁(RLock)
GIL锁 计算机有4核,代表着同一时间,可以干4个任务.如果单核cpu的话,我启动10个线程,我看上去也是并发的,因为是执行了上下文的切换,让看上去是并发的.但是单核永远肯定时串行的,它肯定是串行的, ...
- OpenMP 线程互斥锁
OpenMP是跨平台的多核多线程编程的一套指导性的编译处理方案(Compiler Directive),指导编译器将代码编译为多线程程序. 多线程编程中肯定会涉及到线程之间的资源共享问题,就可以使用互 ...
- Python 开启线程的2中方式,线程VS进程(守护线程、互斥锁)
知识点一: 进程:资源单位 线程:才是CPU的执行单位 进程的运行: 开一个进程就意味着开一个内存空间,存数据用,产生的数据往里面丢 线程的运行: 代码的运行过程就相当于运行了一个线程 辅助理解:一座 ...
随机推荐
- JavaScript之创建八个对象过520
马上又到了一年一度的520了,程序猿们赶紧创建对象过520吧!!! JavaScript创建对象的几种方式: 一:字面量方式: var obj = {name: '程序猿'}; 二:通过new操作符: ...
- 『忘了再学』Shell基础 — 30、sed命令的使用
目录 1.sed命令说明 2.行数据操作 (1)查看文件中的数据 (2)删除文件中的数据 (3)向文件中追加数据 (4)向文件中插入数据 (5)修改文件中的多行数据(删除,追加,插入) (6)替换文件 ...
- HMS Core 视频编辑服务开放模板能力,助力用户一键Get同款酷炫视频
前言 短视频模板,是快捷创作短视频的一种方式,一般由专业设计师或模板创作人制作,用户只需替换视频模板中的部分素材,便可生成一支与模板一样的创意视频.这种省时省力.无需"烧脑"构思创 ...
- 【Redis】ziplist压缩列表
压缩列表 压缩列表是列表和哈希表的底层实现之一: 如果一个列表只有少量数据,并且数据类型是整数或者比较短的字符串,redis底层就会使用压缩列表实现. 如果一个哈希表只有少量键值对,并且每个键值对的键 ...
- [安洵杯 2019]easy_web-1
1.首先打开题目如下: 2.观察访问的地址信息,发现img信息应该是加密字符串,进行尝试解密,最终得到img名称:555.png,如下: 3.获得文件名称之后,应该想到此处会存在文件包含漏洞,因为传输 ...
- BUUCTF-BJDCTF2020]just_a_rar
BJDCTF2020]just_a_rar 压缩包提示是四位数密码 爆破得知压缩包密码 16进制查看解压的图片后发现flag flag{Wadf_123}
- 用python进行加密和解密——我看刑
加密和解密 密码术意味着更改消息的文本,以便不知道你秘密的人永远不会理解你的消息. 下面就来创建一个GUI应用程序,使用Python进行加密和解密. 在这里,我们需要编写使用无限循环的代码,代码将不断 ...
- Python列表解析式的正确使用方式(一)
先来逼逼两句: Python 是一种极其多样化和强大的编程语言!当需要解决一个问题时,它有着不同的方法.在本文中,将会展示列表解析式 (List Comprehension).我们将讨论如何使用它?什 ...
- Maven配置【详细】
参考网址:https://www.jianshu.com/p/f2f52a062d5b
- CF1042E Vasya and Magic Matrix 题解
题目链接 思路分析 看到题目中 \(n,m \leq 1000\) ,故直接考虑 \(O(n^2)\) 级别做法. 我们先把所有的点按照 \(val\) 值从小到大排序,这样的话二维问题变成序列问题. ...