超硬核解析!Apache Hudi灵活的Payload机制
Apache Hudi 的Payload是一种可扩展的数据处理机制,通过不同的Payload我们可以实现复杂场景的定制化数据写入方式,大大增加了数据处理的灵活性。Hudi Payload在写入和读取Hudi表时对数据进行去重、过滤、合并等操作的工具类,通过使用参数 "hoodie.datasource.write.payload.class"指定我们需要使用的Payload class。
1.摘要
Apache Hudi 的Payload是一种可扩展的数据处理机制,通过不同的Payload我们可以实现复杂场景的定制化数据写入方式,大大增加了数据处理的灵活性。Hudi Payload在写入和读取Hudi表时对数据进行去重、过滤、合并等操作的工具类,通过使用参数 "hoodie.datasource.write.payload.class"指定我们需要使用的Payload class。本文我们会深入探讨Hudi Payload的机制和不同Payload的区别及使用场景。
2. 为何需要Payload
在数据写入的时候,现有整行插入、整行覆盖的方式无法满足所有场景要求,写入的数据也会有一些定制化处理需求,因此需要有更加灵活的写入方式以及对写入数据进行一定的处理,Hudi提供的playload方式可以很好的解决该问题,例如可以解决写入时数据去重问题,针对部分字段进行更新等等。
3. Payload的作用机制
写入Hudi表时需要指定一个参数hoodie.datasource.write.precombine.field,这个字段也称为Precombine Key,Hudi Payload就是根据这个指定的字段来处理数据,它将每条数据都构建成一个Payload,因此数据间的比较就变成了Payload之间的比较。只需要根据业务需求实现Payload的比较方法,即可实现对数据的处理。
Hudi所有Payload都实现HoodieRecordPayload接口,下面列出了所有实现该接口的预置Payload类。
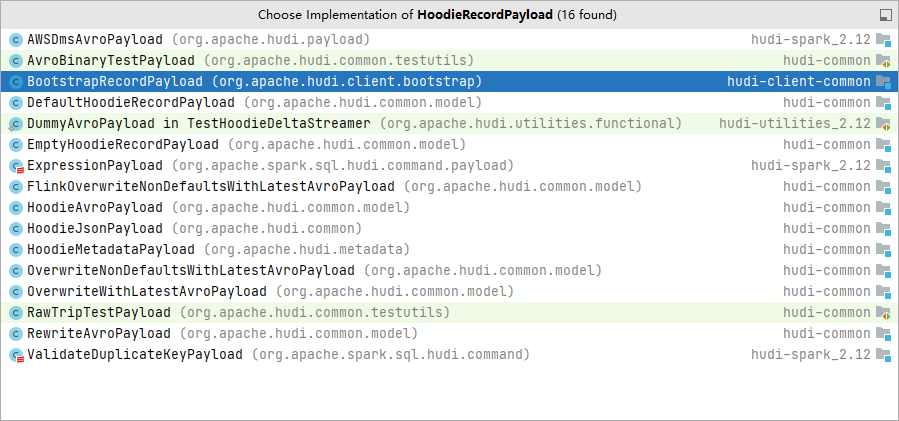
下图列举了HoodieRecordPayload接口需要实现的方法,这里有两个重要的方法preCombine和combineAndGetUpdateValue,下面我们对这两个方法进行分析。
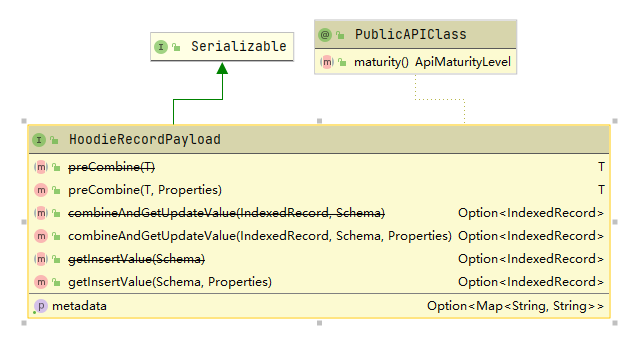
3.1 preCombine分析
从下图可以看出,该方法比较当前数据和oldValue,然后返回一条记录。
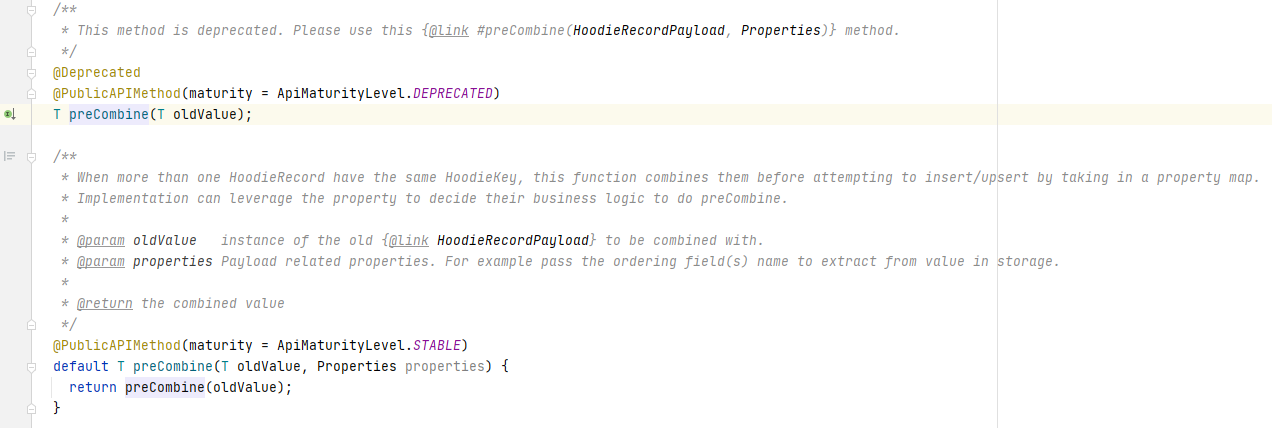
从preCombine方法的注释描述也可以知道首先它在多条相同主键的数据同时写入Hudi时,用来进行数据去重。
调用位置
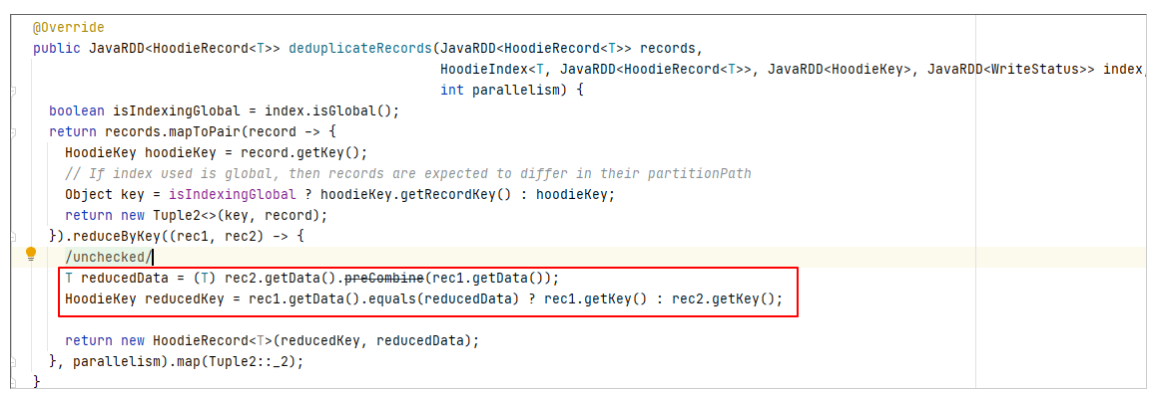
其实该方法还有另一个调用的地方,即在MOR表读取时会对Log file中的相同主键的数据进行处理。
如果同一条数据多次修改并写入了MOR表的Log文件,在读取时也会进行preCombine。
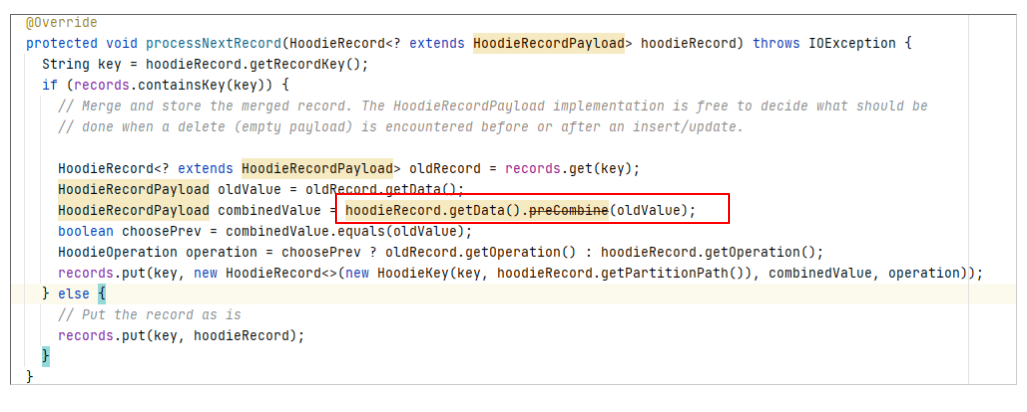
3.2 combineAndGetUpdateValue分析
该方法将currentValue(即现有parquet文件中的数据)与新数据进行对比,判断是否需要持久化新数据。
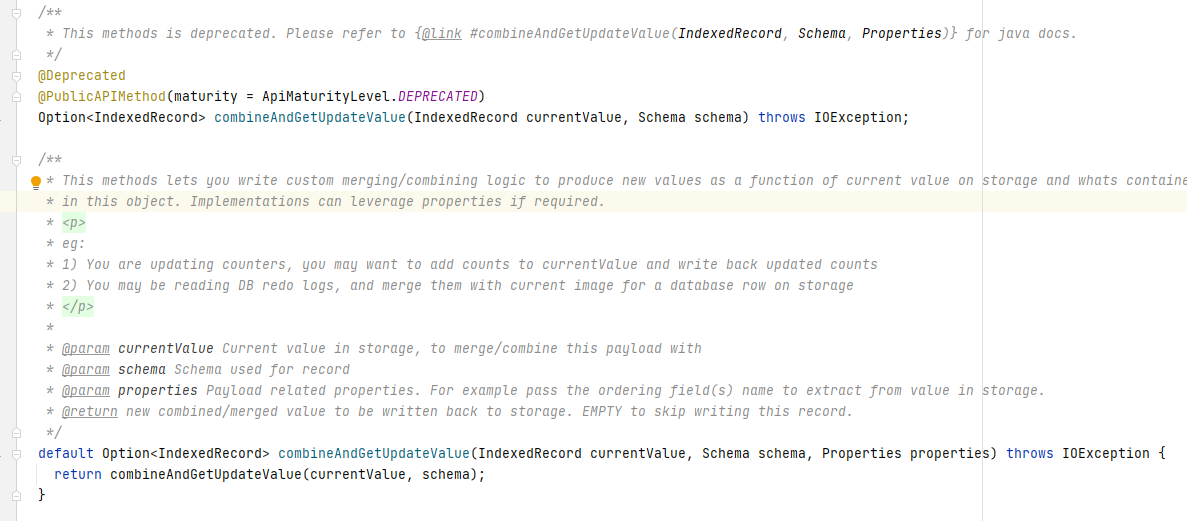
由于COW表和MOR表的读写原理差异,因此combineAndGetUpdateValue的调用在COW和MOR中也有所不同:
- 在COW写入时会将新写入的数据与Hudi表中存的currentValue进行比较,返回需要持久化的数据
- 在MOR读取时会将经过preCombine处理的Log中的数据与Parquet文件中的数据进行比较,返回需要持久化的数据
4.常用Payload处理逻辑的对比
了解了Payload的内核原理,下面我们对比分析下集中常用的Payload实现的方式。
4.1 OverwriteWithLatestAvroPayload
OverwriteWithLatestAvroPayload 的相关方法实现如下

可以看出使用OverwriteWithLatestAvroPayload 会根据orderingVal进行选择(这里的orderingVal即precombine key的值),而combineAndGetUpdateValue永远返回新数据。
4.2 OverwriteNonDefaultsWithLatestAvroPayload
OverwriteNonDefaultsWithLatestAvroPayload继承OverwriteWithLatestAvroPayload,preCombine方法相同,重写了combineAndGetUpdateValue方法,新数据会按字段跟schema中的default value进行比较,如果default value非null且与新数据中的值不同时,则在新数据中更新该字段。由于通常schema定义的default value都是null,在此场景下可以实现更新非null字段的功能,即如果一条数据有五个字段,使用此Payload更新三个字段时不会影响另外两个字段原来的值。
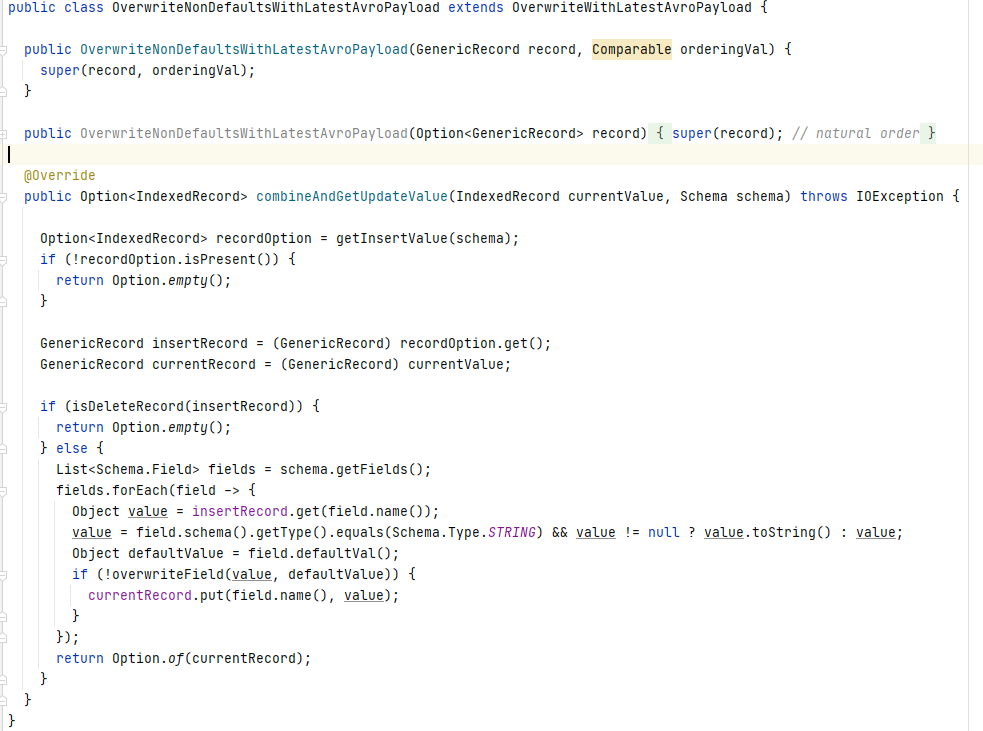
4.3 DefaultHoodieRecordPayload
DefaultHoodieRecordPayload同样继承OverwriteWithLatestAvroPayload重写了combineAndGetUpdateValue方法,通过下面代码可以看出该Payload使用precombine key对现有数据和新数据进行比较,判断是否要更新该条数据。
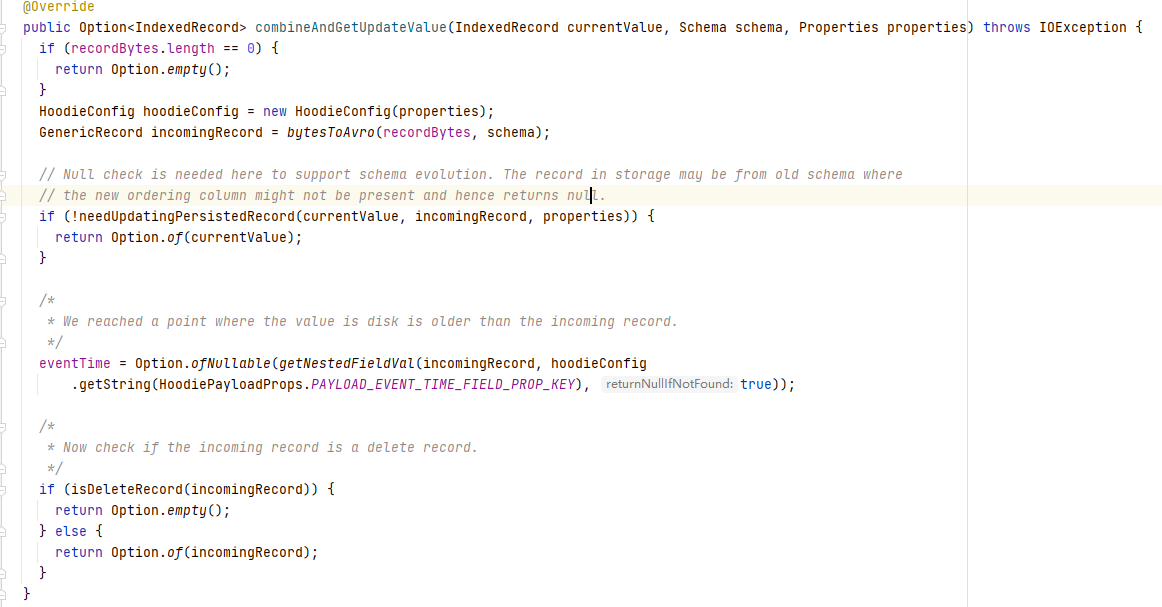
下面我们以COW表为例展示不同Payload读写结果测试
5. 测试
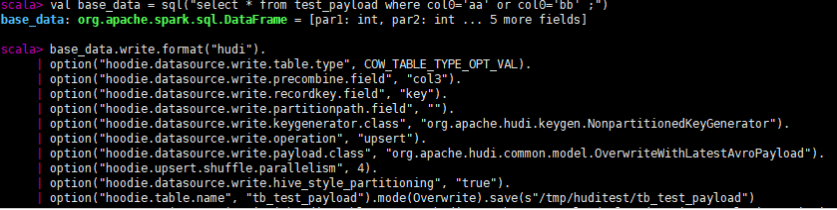
我们使用如下几条源数据,以key为主键,col3为preCombine key写Hudi表。

首先我们一次写入col0是'aa'、'bb'的两条数据,由于他们的主键相同,所以在precombine时会根据col3比较去重,最终写入Hudi表的只有一条数据。(注意如果写入方式是insert或bulk_insert则不会去重)
查询结果

下面我们使用col0是'cc'的数据进行更新,这是由于三种Payload的处理逻辑不同,最终写入的数据结果也不同。
OverwriteWithLatestAvroPayload
完全用新数据覆盖了旧数据。

OverwriteNonDefaultsWithLatestAvroPayload
由于更新数据中col1 col2为null,因此该字段未被更新。

DefaultHoodieRecordPayload
由于cc的col3小于bb的,因此该数据未被更新。

6. 总结
通过上面分析我们清楚了Hudi常用的几种Payload机制,总结对比如下
| Payload | 更新逻辑与适用场景 |
|---|---|
| OverwriteWithLatestAvroPayload | 永远用新数据更新老数据全部字段,适合每次更新数据都是完整的 |
| OverwriteNonDefaultsWithLatestAvroPayload | 将新数据中的非空字段更新到老数据中,适合每次更新数据只有部分字段 |
| DefaultHoodieRecordPayload | 根据precombine key比较是否要更新数据,适合实时入湖且入湖顺序乱序 |
虽然Hudi提供了多个预置Payload,但是仍不能满足一些特殊场景的数据处理工作:例如用户在使用Kafka-Hudi实时入湖,但是用户的一条数据的修改不在一条Kafka消息中,而是多条相同主键的数据消息到,第一条里面有col0,col1的数据,第二条有col2,col3的数据,第三条有col4的数据,这时使用Hudi自带的Payload就无法完成将这三条数据合并之后写入Hudi表的工作,要实现这个逻辑就要通过自定义Payload,重写Payload中的preCombine和combineAndGetUpdateValue方法来实现相应的业务逻辑,并在写入时通过hoodie.datasource.write.payload.class指定我们自定义的Payload实现。
超硬核解析!Apache Hudi灵活的Payload机制的更多相关文章
- 【Nginx】冰河又一本超硬核Nginx PDF教程免费开源!!
写在前面 在 [冰河技术] 微信公众号中的[Nginx]专题,更新了不少文章,有些读者反馈说,在公众号中刷 历史文章不太方便,有时会忘记自己看到哪一篇了,当打开一篇文章时,似乎之前已经看过了, 但就是 ...
- 十一长假我肝了这本超硬核PDF,现决定开源!!
写在前面 在 [冰河技术] 微信公众号中的[互联网工程]专题,更新了不少文章,有些读者反馈说,在公众号中刷 历史文章不太方便,有时会忘记自己看到哪一篇了,当打开一篇文章时,似乎之前已经看过了,但就是不 ...
- 云栖干货回顾 | 云原生数据库POLARDB专场“硬核”解析
POLARDB是阿里巴巴自主研发的云原生关系型数据库,目前兼容三种数据库引擎:MySQL.PostgreSQL.Oracle.POLARDB的计算能力最高可扩展至1000核以上,存储容量可达100TB ...
- 【JVM】肝了一周,吐血整理出这份超硬核的JVM笔记(升级版)!!
写在前面 最近,一直有小伙伴让我整理下关于JVM的知识,经过十几天的收集与整理,初版算是整理出来了.希望对大家有所帮助. JDK 是什么? JDK 是用于支持 Java 程序开发的最小环境. Java ...
- 超硬核 Web 前端学霸笔记,学完就去找工作!
文章和教程 Vue 学习笔记 Node 学习笔记 React 学习笔记 Angular 学习笔记 RequireJS 学习笔记 Webpack 学习笔记 Gulp 学习笔记 Python 学习笔记 E ...
- 硬核解析MySQL的MVCC实现原理,面试官看了都直呼内行
1. 什么是MVCC MVCC全称是Multi-Version Concurrency Control(多版本并发控制),是一种并发控制的方法,通过维护一个数据的多个版本,减少读写操作的冲突. 如果没 ...
- 【面经】超硬核面经,已拿蚂蚁金服Offer!!
写在前面 很多小伙伴都反馈说,现在的工作不好找呀,也不敢跳槽,在原来的岗位上也是战战兢兢!其实,究其根本原因,还是自己技术不过关,如果你技术真的很硬核,怕啥?想去哪去哪呗!这不,我的一个读者去面试了蚂 ...
- Apache Hudi内核之文件标记机制深入解析
1. 摘要 Hudi 支持在写入时自动清理未成功提交的数据.Apache Hudi 在写入时引入标记机制来有效跟踪写入存储的数据文件. 在本博客中,我们将深入探讨现有直接标记文件机制的设计,并解释了其 ...
- KLOOK客路旅行基于Apache Hudi的数据湖实践
1. 业务背景介绍 客路旅行(KLOOK)是一家专注于境外目的地旅游资源整合的在线旅行平台,提供景点门票.一日游.特色体验.当地交通与美食预订服务.覆盖全球100个国家及地区,支持12种语言和41种货 ...
随机推荐
- suse 12 二进制部署 Kubernetets 1.19.7 - 第11章 - 部署coredns组件
文章目录 1.11.0.部署coredns 1.11.1.测试coredns功能 suse 12 二进制部署 Kubernetes 集群系列合集: suse 12 二进制部署 Kubernetets ...
- ApplicationStartedEvent与ContextStartedEvent有区别吗?
大家好,我是DD! 今天跟大家聊聊这个问题:ApplicationStartedEvent与ContextStartedEvent有区别吗? 对了,最近花了几周时间,把SpringForAll社区 3 ...
- Python中模块的定义及案例
1 a = '我是模块中的变量a' 2 3 def hi(): 4 a = '我是函数里的变量a' 5 print('函数"hi"已经运行!') 6 7 class Go2: 8 ...
- python中面向对象VS面向过程
面向过程编程:首先分析出解决问题所需要的步骤(即"第一步做什么,第二步做什么,第三步做什么"),然后用函数实现各个步骤,再依次调用. 面向对象编程:会将程序看作是一组对象的集合,用 ...
- demo_2_27
#define _CRT_SECURE_NO_WARNINGS 1#include <stdio.h>#include <string.h> int count_bit_one ...
- 在sublime上运行node
1.安装node,这个就简单了,不多说了.默认会安装在C盘,也可以自己设定盘符,如D.E 2.打开Sublime Text -> Tools -> Build -> Build Sy ...
- 从菜鸟到高手, HMS Core图像分割服务教你如何在复杂背景里精细抠图
2021年以来,自动驾驶赛道进入爆发期,该行业成为大厂以及初创企业的必争之地.其中众多公司都采用了计算机视觉作为自动驾驶的技术底座,通过图像分割技术,汽车才能够有效理解道路场景,分清楚哪里是路,哪里是 ...
- rlwrap的使用
转至:http://blog.itpub.net/429786/viewspace-776177/ 在LINUX下使用ORACLE一些命令时(如sqlplus,rman等),经常需要调用上次或之前运行 ...
- 鼠标点击的时候出现 "双心心" 的效果
设置步骤 点击博客园的 [管理] → [设置] → 一直往下拉, 找到 [页首Html代码],添加如下代码内容, 保存即可: <script type="text/javascrip ...
- parquet列存储本身自带压缩 配合snappy或者lzo等可以进行二次压缩
上传txt文件到hdfs,txt文件大小是74左右. 这里提醒一下,是不是说parquet加lzo可以把数据压缩到这个地步,因为我的测试数据存在大量重复.所以下面使用parquet和lzo的压缩效果特 ...