Mysql查询优化器之关于JOIN的优化
连接查询应该是比较常用的查询方式,连接查询大致分为:内连接、外连接(左连接和右连接)、自然连接
下图展示了 LEFT JOIN、RIGHT JOIN、INNER JOIN、OUTER JOIN 相关的 7 种用法。
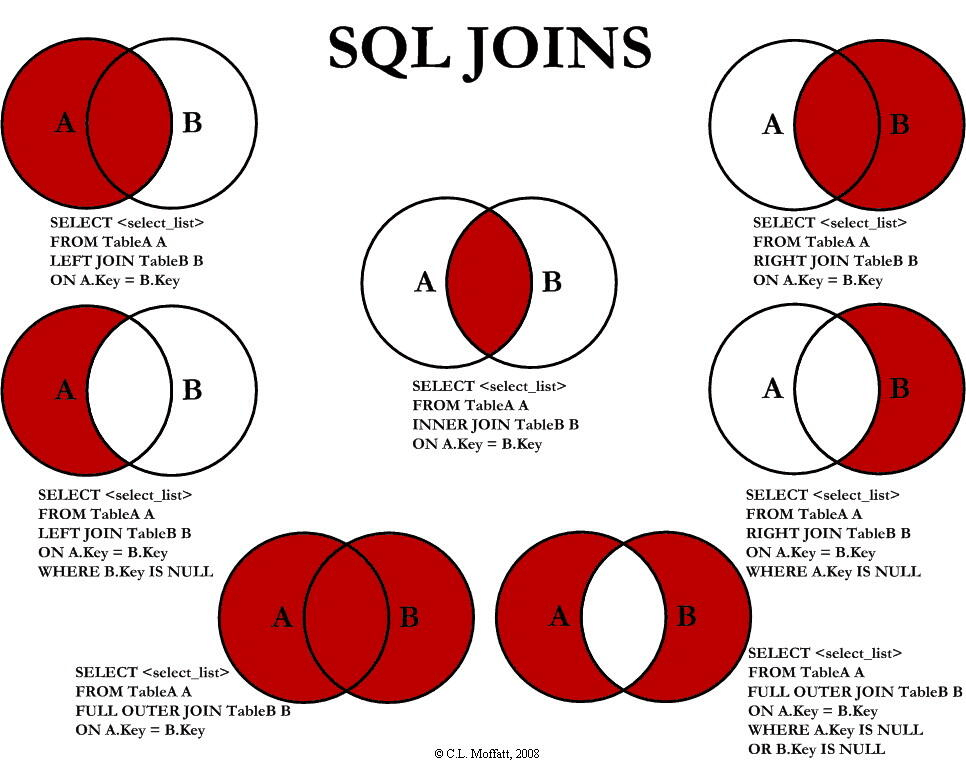
内连接
以下三种写法都是内连接:
mysql> select * from t1 join t2 on t1.a = t2.a;
mysql> select * from t1 inner join t2 on t1.a = t2.a;
mysql> select * from t1 cross join t2 on t1.a = t2.a;
图解:

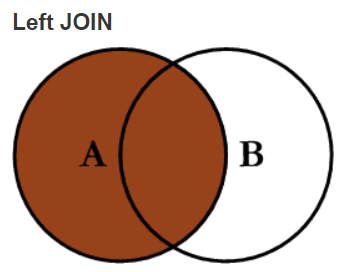
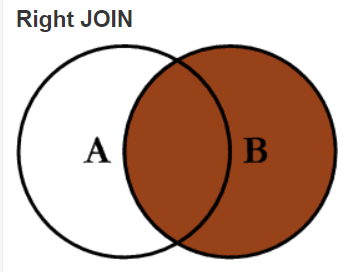
左连接、右连接
左连接:
mysql> select * from t1 left join t2 on t1.a = t2.a;
右连接:
mysql> select * from t1 right join t2 on t1.a = t2.a;
连接的原理
不管是内连接还是左右连接,都需要一个驱动表和一个被驱动表,对于内连接来说,选取哪个表为驱动表都没关系,而外连接的驱动表是固定的,也就是说左连接的驱动表就是左边的那个表,右连接的驱动表就是右边的那个表。
连接的大致原理是:
1. 选取驱动表,使用与驱动表相关的过滤条件,选取代价最低的访问形式来执行对驱动表的单表查询。
2. 对上一步骤中查询驱动表得到的结果集中每一条记录,都分别到被驱动表中查找匹配的记录。
对应伪代码就是:
for each row in t1 { //此处表示遍历满足对t1单表查询结果集中的每一条记录
for each row in t2 { //此处表示对于某条t1表的记录来说,遍历满足对t2单表查询结果集中的每一条记录
// 判断是否符合join条件
}
}
嵌套循环连接(Nested-Loop Join)
上面的过程就像是一个嵌套的循环,所以这种驱动表只访问一次,但被驱动表却可能被多次访问,访问次数取决于对驱动表执行单表查询后的结果集中的记录条数的连接执行方式称之为嵌套循环连接(Nested-Loop Join),这是最简单,也是最笨拙的一种连接查询算法;
比如对于下面这个sql:
select * from t1 join t2 on t1.a = t2.a where t1.b in (1,2);
先会执行:
mysql> select * from t1 where t1.b in (1,2);
+---+------+------+------+------+
| a | b | c | d | e |
+---+------+------+------+------+
| 1 | 1 | 1 | 1 | a |
| 2 | 2 | 2 | 2 | b |
| 5 | 2 | 3 | 5 | e |
+---+------+------+------+------+
3 rows in set (0.00 sec)
得到三条记录。
然后分别执行:
mysql> select * from t2 where t2.a = 1;
mysql> select * from t2 where t2.a = 2;
mysql> select * from t2 where t2.a = 5;
所以实际上对于上面的步骤,实际上都是针对单表的查询,所以都可以使用索引来帮助查询。
基于块的嵌套循环连接(Block Nested-Loop Join)
扫描一个表的过程其实是先把这个表从磁盘上加载到内存中,然后从内存中比较匹配条件是否满足。现实生活中的表可不像t1、t2这种只有几条记录,可能会有成千上万的数据。内存里可能并不能完全存放的下表中所有的记录,所以在扫描表前边记录的时候后边的记录可能还在磁盘上,等扫描到后边记录的时候可能内存不足,所以需要把前边的记录从内存中释放掉。我们前边又说过,采用嵌套循环连接算法的两表连接过程中,被驱动表可是要被访问好多次的,如果这个被驱动表中的数据特别多而且不能使用索引进行访问,那就相当于要从磁盘上读好几次这个表,这个I/O代价就非常大了,所以我们得想办法:尽量减少访问被驱动表的次数。
当被驱动表中的数据非常多时,每次访问被驱动表,被驱动表的记录会被加载到内存中,在内存中的每一条记录只会和驱动表结果集的一条记录做匹配,之后就会被从内存中清除掉。然后再从驱动表结果集中拿出另一条记录,再一次把被驱动表的记录加载到内存中一遍,周而复始,驱动表结果集中有多少条记录,就得把被驱动表从磁盘上加载到内存中多少次。所以我们可不可以在把被驱动表的记录加载到内存的时候,一次性和多条驱动表中的记录做匹配,这样就可以大大减少重复从磁盘上加载被驱动表的代价了。
join buffer
Mysql中有一个叫做join buffer的概念,join buffer就是执行连接查询前申请的一块固定大小的内存,先把若干条驱动表结果集中的记录装在这个join buffer中,然后开始扫描被驱动表,每一条被驱动表的记录一次性和join buffer中的多条驱动表记录做匹配,因为匹配的过程都是在内存中完成的,所以这样可以显著减少被驱动表的I/O代价。
最好的情况是join buffer足够大,能容纳驱动表结果集中的所有记录,这样只需要访问一次被驱动表就可以完成连接操作了。这种加入了join buffer的嵌套循环连接算法称之为基于块的嵌套连接(Block Nested-Loop Join)算法。
这个join buffer的大小是可以通过启动参数或者系统变量join_buffer_size进行配置,默认大小为262144字节(也就是256KB),最小可以设置为128字节。当然,对于优化被驱动表的查询来说,最好是为被驱动表加上效率高的索引,如果实在不能使用索引,并且自己的机器的内存也比较大可以尝试调大join_buffer_size的值来对连接查询进行优化。
另外需要注意的是,驱动表的记录并不是所有列都会被放到join buffer中,只有查询列表中的列和过滤条件中的列才会被放到join buffer中,所以再次提醒我们,最好不要把*作为查询列表,只需要把我们关心的列放到查询列表就好了,这样可以在join buffer中放置更多的记录。
外连接消除
内连接的驱动表和被驱动表的位置可以相互转换,而左连接和右连接的驱动表和被驱动表是固定的。这就导致内连接可能通过优化表的连接顺序来降低整体的查询成本,而外连接却无法优化表的连接顺序。
外连接和内连接的本质区别就是:对于外连接的驱动表的记录来说,如果无法在被驱动表中找到匹配ON子句中的过滤条件的记录,那么该记录仍然会被加入到结果集中,对应的被驱动表记录的各个字段使用NULL值填充;而内连接的驱动表的记录如果无法在被驱动表中找到匹配ON子句中的过滤条件的记录,那么该记录会被舍弃
案例:下图中可以发现驱动表和被驱动表发生了变化,实际上加上了is not null之后被优化成了内连接,就可以利用查询优化器选择最优的连接顺序了。
Mysql查询优化器之关于JOIN的优化的更多相关文章
- Mysql查询优化器之基本优化
对于一个SQL语句,查询优化器先看是不是能转换成JOIN,再将JOIN进行优化 优化分为: 1. 条件优化 2.计算全表扫描成本 3. 找出所有能用到的索引 4. 针对每个索引计算不同的访问方式的成本 ...
- Mysql查询优化器之关于子查询的优化
下面这些sql都含有子查询: mysql> select * from t1 where a in (select a from t2); mysql> select * from (se ...
- Mysql查询优化汇总 order by优化例子,group by优化例子,limit优化例子,优化建议
Mysql查询优化汇总 order by优化例子,group by优化例子,limit优化例子,优化建议 索引 索引是一种存储引擎快速查询记录的一种数据结构. 注意 MYSQL一次查询只能使用一个索引 ...
- mysql 查询优化~join算法
一简介:参考了几位师兄,尤其是M哥大神的博客,让我恍然大悟,赶紧记录下二 原理: mysql的三种算法 1 Simple Nested-Loop Join 将驱动表/外部表的结果集作为循环基础数据,然 ...
- mysql查询优化之四:优化特定类型的查询
本文将介绍如何优化特定类型的查询. 1.优化count()查询count()聚合函数,以及如何优化使用了该函数的查询,很可能是mysql中最容易被误解的前10个话题之一 count() 是一个特殊的函 ...
- MySQL查询优化之explain的深入解析
在分析查询性能时,考虑EXPLAIN关键字同样很管用.EXPLAIN关键字一般放在SELECT查询语句的前面,用于描述MySQL如何执行查询操作.以及MySQL成功返回结果集需要执行的行数.expla ...
- mysql in 子查询 效率慢 优化(转)
mysql in 子查询 效率慢 优化(转) 现在的CMS系统.博客系统.BBS等都喜欢使用标签tag作交叉链接,因此我也尝鲜用了下.但用了后发现我想查询某个tag的文章列表时速度很慢,达到5秒之久! ...
- Mysql查询优化器
Mysql查询优化器 本文的目的主要是通过告诉大家,查询优化器为我们做了那些工作,我们怎么做,才能使查询优化器对我们的sql进行优化,以及启示我们sql语句怎么写,才能更有效率.那么到底mysql到底 ...
- MySQL查询优化处理
查询的生命周期的下一步是将一个sql转化成一个执行计划,MySQL再依照这个执行计划和存储引擎进行交互.这包括多个子阶段:解析sql,预处理,优化sql执行计划.这个过程中任何错误(例如语法错误)都可 ...
随机推荐
- 深入MySQL(二):MySQL的数据类型
前言 对于MySQL中的数据类型的选择,不同的数据类型看起来可能是相同的效果,但是其实很多时候天差地别. 本章从MySQL中的常用类型出发,结合类型选择的常见错误,贯彻MySQL的常用类型选择. 常用 ...
- Dubbo SPI机制之三Adaptive自适应功能
JDK标准中SPI机制的一个问题就是其一次性实例化扩展点所有实现,如果有扩展实现初始化很耗时,但如果没用上也加载,会很浪费资源:扩展点加载失败,其他扩展点都用不了了.Dubbo是如何解决该问题动态的选 ...
- [LeetCode]1295. 统计位数为偶数的数字
给你一个整数数组 nums,请你返回其中位数为 偶数 的数字的个数. 示例 1: 输入:nums = [12,345,2,6,7896] 输出:2 解释: 12 是 2 位数字(位数为偶数) 345 ...
- c++基础的记录(随笔记录一些基础的东西)
1.父类的析构函数为什么要加上virtual关键字. 比如说,父类A,子类B.在A* a = new B()的语句的时候,如果父类析构函数没有virtual,我们在delete指针a的时候,会走父类的 ...
- DNS中的SOA
起始授权机构,SOA(Start Of Authority):该记录表明DNS名称服务器是DNS域中的数据表的信息来源,该服务器是主机名字的管理者,创建新区域时,该资源记录自动创建,且是DNS数据库文 ...
- Java面试题2017
一.Java 基础 1. String 类为什么是 final 的. 2. HashMap 的源码,实现原理,底层结构. 3. 说说你知道的几个 Java 集合类:list.set.queue.map ...
- 微服务从代码到k8s部署应有尽有系列(十、错误处理)
我们用一个系列来讲解从需求到上线.从代码到k8s部署.从日志到监控等各个方面的微服务完整实践. 整个项目使用了go-zero开发的微服务,基本包含了go-zero以及相关go-zero作者开发的一些中 ...
- c语言刷 DFS题记录
144. 二叉树的前序遍历 /** * Definition for a binary tree node. * struct TreeNode { * int val; * struct TreeN ...
- JAVA——类与对象
目录 类与对象 一.类 二.对象 2.1对象的内存布局形式 三.类与对象 3.1如何创建 3.2如何访问属性 3.2类与对象的分配机制 3.2.1Java内存的结构分析 注意事项和细节 类与对象 为什 ...
- 『现学现忘』Docker基础 — 14、Docker的卸载
目录 1.查询Docker安装过的包 2.卸载Docker软件包 3.删除残留目录 4.验证是否卸载 5.20版本Docker卸载(官方文档) 1.查询Docker安装过的包 执行yum list i ...